
L @CodeTitanium
Joined July 2023-
Tweets1K
-
Followers101
-
Following5K
-
Likes61K


Great to see this effort towards rigorous hyperparameter tuning. Two areas for improvement: 1. IIUC, the scaled up run here isn't actually tuned at all - its hparams are set via extrapolation 2. Sensitive hparams need a more granular sweep than power-of-2 x.com/percyliang/sta…

Great to see this effort towards rigorous hyperparameter tuning. Two areas for improvement: 1. IIUC, the scaled up run here isn't actually tuned at all - its hparams are set via extrapolation 2. Sensitive hparams need a more granular sweep than power-of-2 x.com/percyliang/sta…
Following up on my Newton–Schulz speedup post, here’s the code: github.com/thib-s/flash-n… (I'll do a PR soon in Dion/Muon) And here’s how I squeezed out the extra gain ⬇️
Following up on my Newton–Schulz speedup post, here’s the code: github.com/thib-s/flash-n… (I'll do a PR soon in Dion/Muon) And here’s how I squeezed out the extra gain ⬇️


🔍 How do we teach an LLM to 𝘮𝘢𝘴𝘵𝘦𝘳 a body of knowledge? In new work with @AIatMeta, we propose Active Reading 📙: a way for models to teach themselves new things by self-studying their training data. Results: * 𝟔𝟔% on SimpleQA w/ an 8B model by studying the wikipedia…

Good news: I managed to get an extra 1.6x speedup of the Newton Schulz algorithm (which is at the core of Dion/Muon). It reaches nearly a 3x speedup over the plain torch implementation !

Google made a huge breakthrough in image editing with their new Gemini 2.5 Flash model 171 elo points ahead of the 2nd best model


Motif 2.6B tech report is pretty insane, first time i see a model with differential attention and polynorm trained at scale! > It's trained on 2.5T of token, with a "data mixture schedule" to continuously adjust the mixture over training. > They use WSD with a "Simple moving…


So we went from "LLM is memorizing dataset" to "LLM is not reasoning" to "LLM cannot do long / complex math proving" to "Math that LLM is doing is not REAL math. LLM can't do REAL math" Where do we go from now?

So we went from "LLM is memorizing dataset" to "LLM is not reasoning" to "LLM cannot do long / complex math proving" to "Math that LLM is doing is not REAL math. LLM can't do REAL math" Where do we go from now?

I've finally solved steepest descent on Finsler-structured (matrix) manifolds more generally. This generalizes work by me, @jxbz, and @Jianlin_S on Muon, Orthogonal Muon, & Stiefel Muon. --- The general solution turned out to be much simpler than I thought. And it should…

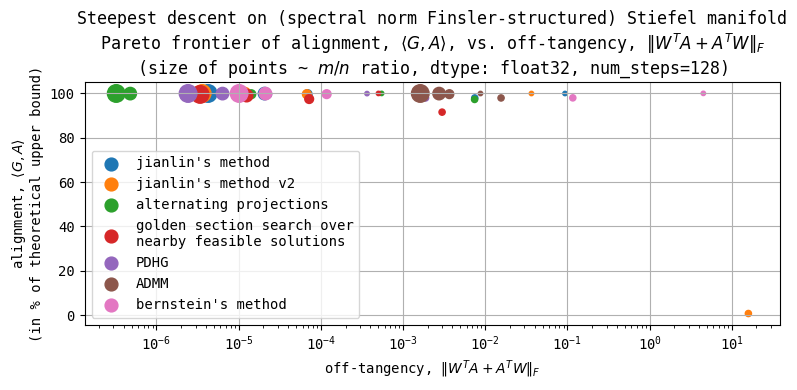
I've finally solved steepest descent on Finsler-structured (matrix) manifolds more generally. This generalizes work by me, @jxbz, and @Jianlin_S on Muon, Orthogonal Muon, & Stiefel Muon. --- The general solution turned out to be much simpler than I thought. And it should… https://t.co/NWwzMzmcHH

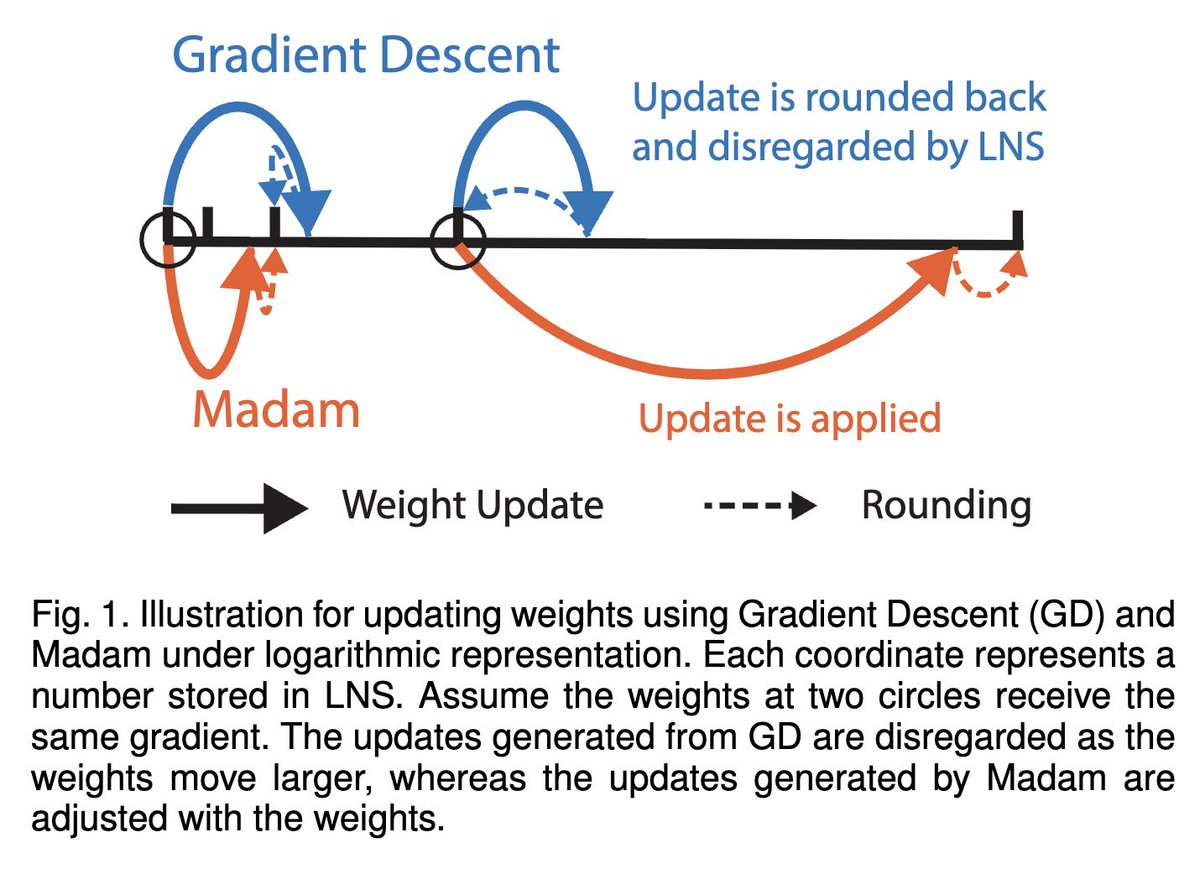
It is interesting that the new @deepseek_ai v3.1 is trained using the UE8M0 FP8 scale data format which is logarithmic number system. Our multiplicative weights update (Madam) for training in that format was done several years ago while at @nvidia It yields maximum hardware…

Introducing DeepSeek-V3.1: our first step toward the agent era! 🚀 🧠 Hybrid inference: Think & Non-Think — one model, two modes ⚡️ Faster thinking: DeepSeek-V3.1-Think reaches answers in less time vs. DeepSeek-R1-0528 🛠️ Stronger agent skills: Post-training boosts tool use and…
New DeepSeek v3.1 model is out 🐳 It's an hybride reasoning model, the key difference between V3 and V3.1 is a much, much longer long context extension phase.


Guess it's time to repost the paper review. Most innovative part for me along with seed-geometry is the generation of "conjectures" (now a lot on my mind for all kind of model/synth designs). x.com/Dorialexander/…
Guess it's time to repost the paper review. Most innovative part for me along with seed-geometry is the generation of "conjectures" (now a lot on my mind for all kind of model/synth designs). x.com/Dorialexander/…


Reasoning models preferring music artists with numbers in their name is one of the funniest RL artefacts possible


Training phi-4-reasoning with GFPO cuts GRPO’s length inflation by - 71% on AIME 25 - 80% on GPQA - 83% on Omni-MATH - 80% on LiveCodeBench (WITHOUT training on code!) …while matching or beating GRPO in accuracy Vaish sharing a great 🧵 below!

Training phi-4-reasoning with GFPO cuts GRPO’s length inflation by - 71% on AIME 25 - 80% on GPQA - 83% on Omni-MATH - 80% on LiveCodeBench (WITHOUT training on code!) …while matching or beating GRPO in accuracy Vaish sharing a great 🧵 below!

new muP alert, this time for MoE

GRPO makes reasoning model yap a lot, but there's a simple fix: Sample more responses during training, and train on the shortest ones. This creates a length pressure that makes the model sound much more terse, without sacrificing accuracy!! Examples of GRPO vs GFPO versions…


GRPO makes reasoning model yap a lot, but there's a simple fix: Sample more responses during training, and train on the shortest ones. This creates a length pressure that makes the model sound much more terse, without sacrificing accuracy!! Examples of GRPO vs GFPO versions… https://t.co/yWKzNgyiQn



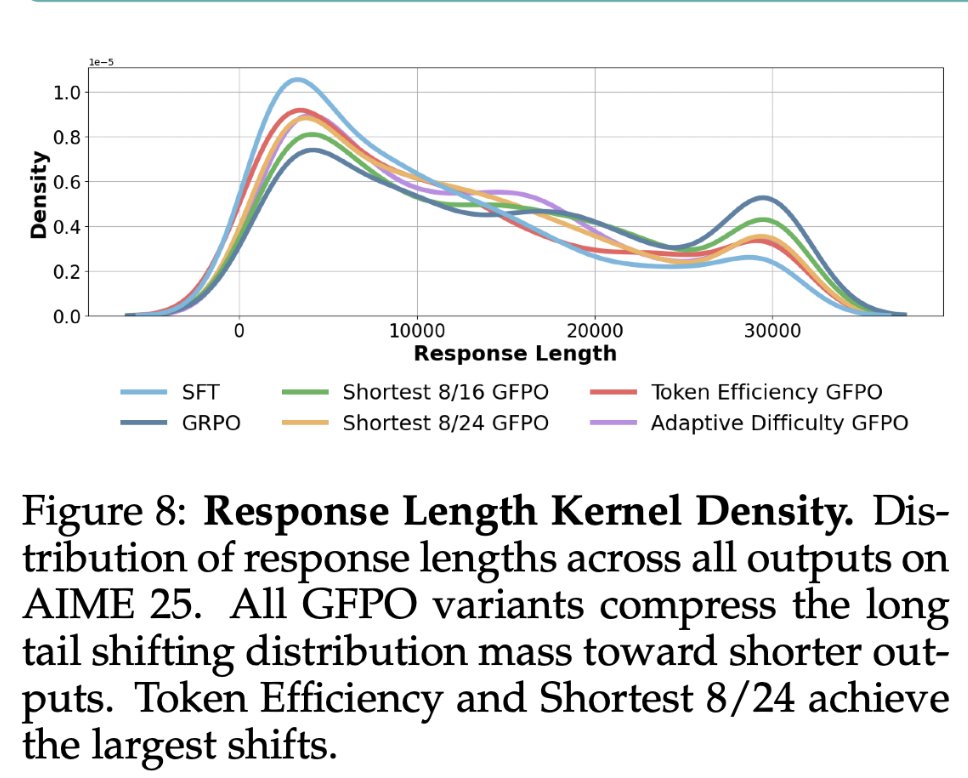
Thinking Less at test-time requires Sampling More at training-time! GFPO is a new, cool, and simple Policy Opt algorithm is coming to your RL Gym tonite, led by @VaishShrivas and our MSR group: Group Filtered PO (GFPO) trades off training-time with test-time compute, in order…

Math folks look at AI output, it's clearly legit math, and they're like, yeah this thing knows how to do math Humanities folks look at AI output, and are immediately like: this thing can't possibly be as good at interpreting texts as we are

Xingcheng Yao @StuartYao22139
247 Followers 265 Following Member of technical staff at @Kimi_Moonshot, Prev @uclanlp, @Tsinghua_IIIS, @princeton_nlp.
Dawei Li @Dawei_Li_ASU
336 Followers 335 Following CS PhD @ ASU https://t.co/JQ2VAX1KPk LLMs, NLP, Data Mining Founder of Oracle-LLM: https://t.co/BJtkt1C0XQ
dumit @kodumit
63 Followers 551 Following


JC Gilbert @gilbert_jc
903 Followers 542 Following GTM @Tabnine prev @CockroachDB @Coursera documenting how ai is colliding with real-world workflows. field notes from the transition.
Yuetai Li @yuetai12575
224 Followers 569 Following Second year PhD @UW | Post-Training, LLM reasoning and synthetic dataset. https://t.co/cYAkbnCsCp Open to chat and collaborate!

Nathan Chen @nathancgy4
656 Followers 562 Following @tilderesearch trying to (pragmatically) understand my friend, ml & open-source, 16


StarBoltSprint Suppor... @_StarBoltSprint
51 Followers 574 Following Powered by xAl & YOU | Unraveling cosmic mysteries— join my adventure! | Woof!

YIFENG LIU @YIFENGLIU_AI
176 Followers 25 Following CS Ph.D. student on LLM @ UCLA AGI Lab. Previous works: RPG, MARS, TPA, Kimi-1.5....
Yi Xu @_yixu
512 Followers 423 Following AI researcher, interested in LLMs and reinforcement learning | Previously @UCL_DARK, @imperialcollege, @UniMelb
Oblivus @oblivuscloud
288 Followers 168 Following High-Performance Computing, democratized. Enterprise-grade GPU Cloud infrastructure for innovators—scalable, affordable, secure. Join the future of compute.
amogh @OfficialAmogh
7K Followers 7K Following co-founder @humanbehaviorai (yc x25) // prev stanford cs
dumbol @dumbol6
248 Followers 4K Following
Ashley Martin @ashleymcheme28
71 Followers 824 Following ashley m, university of virginia, chemical engineering, aspiring software engineer
Shman @TheShmanuel
78 Followers 118 Following
ryu @ryu0000000001
314 Followers 186 Following Nothing is boring. No knowledge is irrelevant: only not relevant *yet*. - Jonathan Gorard

Suraj Patil @psuraj28
6K Followers 63 Following crafting pixels in the forest @bfl_ml prev: Research Engineer @pika_labs, Open Source AI @huggingface. Co-created diffusers 🧨

Yuanzhi @yuanzhi_zhu
259 Followers 726 Following PhD Student in École Polytechnique Currently interested in CV, ML. Opinions are my own.
EmbeddedLLM @EmbeddedLLM
868 Followers 1K Following Your open-source AI ally. We specialize in integrating LLM into your business.
Rosie Zhao @rosieyzh
535 Followers 579 Following PhD student with @hseas ML Foundations Group. Previously @mcgillu.
stephen balaban @stephenbalaban
11K Followers 2K Following Building gigawatt-scale supercomputers for AI. Co-founder and CEO of Lambda.

Javelynn @_javelynn_
25K Followers 24K Following The Curated Tech Blog. Tag article links to retweet. Write for us.

Jim Harris @JimHarris
246K Followers 118K Following At #IFA25 in Berlin Sept 5-9 #IFA2025 #1 Bestselling Author & Analyst on #AI & #Disruption #Innovation Mind blowing AI webinar 1M views https://t.co/xbkEcg5lSQ
unrelated moon horse @lun_aaaaa
223 Followers 1K Following lgbtescreal | 25ish | aspiring machine | open borders | Information wants to be free mostly no longer on x
Sourabh Medapati @activelifetribe
192 Followers 1K Following Research Engineer @ Google Deepmind, AlgoPerf contributor

David Hall @dlwh
3K Followers 1K Following Research Engineering Lead at @StanfordCRFM. Previously co-founder at Semantic Machines ⟶ MSFT. Lead developer of Levanter and Marin @[email protected]
Calc Consulting @CalcCon
4K Followers 2K Following Calculation Consulting is a boutique consultancy that specializes in machine learning, AI, and data science
surya @suryaasub
267 Followers 844 Following gpu kernels @nvidia. prev. pytorch @aiatmeta, ml infra @pinteresteng. cs @georgiatech

Alexander Skage @AlexanderSkage
111 Followers 397 Following CEO of Finterai - building a collaborative future for fighting financial crime!
Akshay Bapat @akkkshaaay
277 Followers 2K Following
Junbo Li @ljb121002
170 Followers 473 Following Ph.D. student @UTCompSci, Undergrad from @FudanUni Math School.
Nomignon @8i8BB
84 Followers 335 Following Chem eng student and I trade some stock / crypto My blog site below
Xidulu @xidulu
342 Followers 510 Following Xi Wang, Full-stack Bayesian, ECNU, UMass CICS, JHU CS, Fan of U-Shape
Stefan Trendafilov @strendafil
237 Followers 364 Following I don't teach you how to make money. 👀 I help you grow, optimise and unlock your full business potential with AI 🚀 | @AIGOConsult
Utopic e/λ @UtopicDev
260 Followers 4K Following AI Designer and Builder. Technology to save the world. There Is No Planet B...
Thibault Jaigu @ThibaultJaigu
635 Followers 493 Following Co-Founder @requestyAI previously @opal_sec & @amplitude_hq working both on tech and business
James Bradbury @jekbradbury
13K Followers 9K Following Compute at @AnthropicAI! Previously JAX, TPUs, and LLMs at Google, MetaMind/@SFResearch, @Stanford Linguistics, @Caixin.

UAP Disclosure Fund @UAPDF
12K Followers 0 Following Our mission is to promote greater understanding of UAP (Unidentified Anomalous Phenomena) by advocating for government transparency & scientific research.
Christopher K. Mellon @ChrisKMellon
152K Followers 46 Following Former Deputy Assistant Secretary of Defense for Intelligence | Former Minority Staff Director, Senate Select Committee on Intelligence
Ferenc Huszár @fhuszar
42K Followers 1K Following Secular Bayesian. Professor of Machine Learning @Cambridge_CL. Talent aficionado at https://t.co/RbJkoLguey Alum of @Twitter, Magic Pony and @Balderton
Ada Fang @AdaFang_
3K Followers 162 Following PhD Student @Harvard | AI/ML for Chemical Biology @marinkazitnik lab | currently at @GoogleDeepMind
Chanwoo Park @chanwoopark20
1K Followers 1K Following Games, Multi-agent (gen) AI | @speedrun SR003 | @mit EECS Ph.D. Candidate
Nano Banana @NanoBanana
27K Followers 1 Following Nano Banana 🍌, aka Gemini 2.5 Flash Image, the world's most powerful image editing and generation model! Try it for free in the @GeminiApp
Daniel D'souza @mrdanieldsouza
858 Followers 958 Following Research Engineer @Cohere_Labs💙 | @UMichECE Alum 〽️ | 🇮🇳✖️🇺🇸 💫"The Universe Works in Mysterious Ways"💫
Bernd @BerndPrach
14 Followers 67 Following
Jaidev Shah @JaidevShah4
448 Followers 2K Following applied science @amazonscience | x- Microsoft AI | CS @columbia | agents, search and personalization

Kevin Shipp @Kevin_Shipp
128K Followers 540 Following Former CIA Officer, Espionage Investigator, HUMINT Collector, Author, "Twilight Of The Shadow Government. How Transparency Will Kill The Deep State.”
Manish Shetty @slimshetty_
1K Followers 768 Following PhD @UCBerkeley | AI4Code & Evals | Projects: GSO, R2E, Syzygy, LMArena RepoChat, AIOpsLab | prev @googledeepmind @msftresearch
Ashton Forbes @JustXAshton
299K Followers 7K Following Quantum Mechanics | Fusion | ZPE Disclosure | Orb Expert #MH370x Streams M/W/F 8pm EST - https://t.co/rl9KbR8iol Views expressed are mine alone.
Vuk Rosić @VukRosic99
115 Followers 750 Following 🤖 AI Research 📊 Transformers, Diffusion, Pretraining 🤝 Explaining & Doing AI Research 🎥 My YouTube below, Bilibili: vuk_ai 🧑🎓 我在学习中文,随时可以跟我用中文聊天
Derrick Choi @derrickcchoi
485 Followers 91 Following Codex @OpenAI - prev. Head of Operations at @Scale_AI - SWE @Apple - Photographer at heart


Bill Chen @realchillben
2K Followers 521 Following Applied @openai ; Prev @ycombinator @Retool @Meta ML @Columbia

Lin Yang @lyang36
3K Followers 1K Following Associate Professor of ECE&CS@UCLA. ML, RL, big data, algorithms, astronomy.

Jessy Lin @realJessyLin
3K Followers 883 Following PhD @Berkeley_AI, visiting researcher @AIatMeta. Interactive language agents 🤖 💬
Ahmed @ah20im
1K Followers 386 Following Codex @OpenAI | prev @twosigma, @Google, @figma Opinions are my own.

Thibaut Boissin @ThibautBoissin
248 Followers 203 Following
George Grigorev @iamgrigorev
2K Followers 999 Following now: exploring opensource; prev: training @togethercompute, chatbots&diffusion@snap rare specialty coffee lover
Sean Kirmani @SeanKirmani
3K Followers 547 Following Research @OpenAI. Interested in intelligence, understanding, and science.
Nicole Brichtova @nbrichtova
2K Followers 40 Following I lead product for image generation at Google DeepMind (Gemini / nano banana, Imagen). Opinions are my own.
Guangxuan Xiao @Guangxuan_Xiao
3K Followers 697 Following Ph.D. student at @MITEECS Prev: CS & Finance @Tsinghua_Uni
Steven-Shine Chen @stevenshinechen
407 Followers 248 Following CS Master's Student at @MIT, previously @imperialcollege Researching multimodal reasoning at the MIT @medialab

Khaled Saab @_khaledsaab
3K Followers 387 Following Researcher @OpenAI, prev: RS @GoogleDeepMind PhD @StanfordAILab @HazyResearch


Jiawei Zhao @jiawzhao
3K Followers 242 Following Research Scientist at Meta FAIR @AIatMeta, PhD @Caltech, GaLore, DeepConf
罗杰斯 🇺🇦 @dhbrojas
141 Followers 806 Following Research Engineer 智谱 https://t.co/vrJX6VOASs | Advanced Computing 清华大学
Google AI Studio @GoogleAIStudio
43K Followers 2 Following The fastest path from prompt to production with Gemini
Feng Yao @fengyao1909
1K Followers 634 Following Ph.D. student @UCSD_CSE | Intern @Amazon Rufus Foundation Model Ex. @MSFTResearch @TsinghuaNLP
Usama Bin Shafqat @usamabinshafqat
491 Followers 393 Following Google Labs / Princeton ‘18 / still figuring it out. All tweets personal.
Andrew Ambrosino @ajambrosino
2K Followers 1K Following @openai · prev product @ Noyo, founded/sold Catch

CELL @CellBioSF
496 Followers 201 Following CELL: Consortium for the Equations of Life and Living Systems. Fusing MathBio, BioPhysics, CompBio and DescriptiveBio around an aggressive mathematical core.
Timothy Nguyen @IAmTimNguyen
12K Followers 449 Following Machine learning researcher at @GoogleDeepMind & mathematician. Host of The Cartesian Cafe podcast. All opinions are my own.

Kuang Xu 许匡 @ProfKuangXu
1K Followers 197 Following Operations Research @Stanford. Building real-world AI @Uber. Hacking glucose at @tikkaengine
Gautam Goel @gautamcgoel
4K Followers 527 Following Postdoc studying ML at the Simons Institute at UC Berkeley.
Julian @julianboolean_
1K Followers 702 Following experimental cozy face account honor is in trying anyway “unnervingly flexible” - @g_leech_
Tomer Ullman @TomerUllman
9K Followers 197 Following Assistant Professor, Department of Psychology, Harvard University. Computation, cognition, development. Bluesky: https://t.co/cU3TtyokJE
Naina Raisinghani @nainar92
720 Followers 148 Following Product Manager at Google DeepMind working on images. I tweet funny things about being nano. 🤷🏽♀️
Stuart Sul @stuart_sul
1K Followers 122 Following ml research @cursor_ai, cs @Stanford, mlsys @HazyResearchTrends for United States
You might like



















