
Instruction Workshop, NeurIPS 2023 @itif_workshop
The official account of the 1st Workshop on Instruction Tuning and Instruction Following (ITIF), colocated with NeurIPS, in December 2023. an-instructive-workshop.github.io New Orleans Joined August 2023-
Tweets185
-
Followers256
-
Following28
-
Likes222
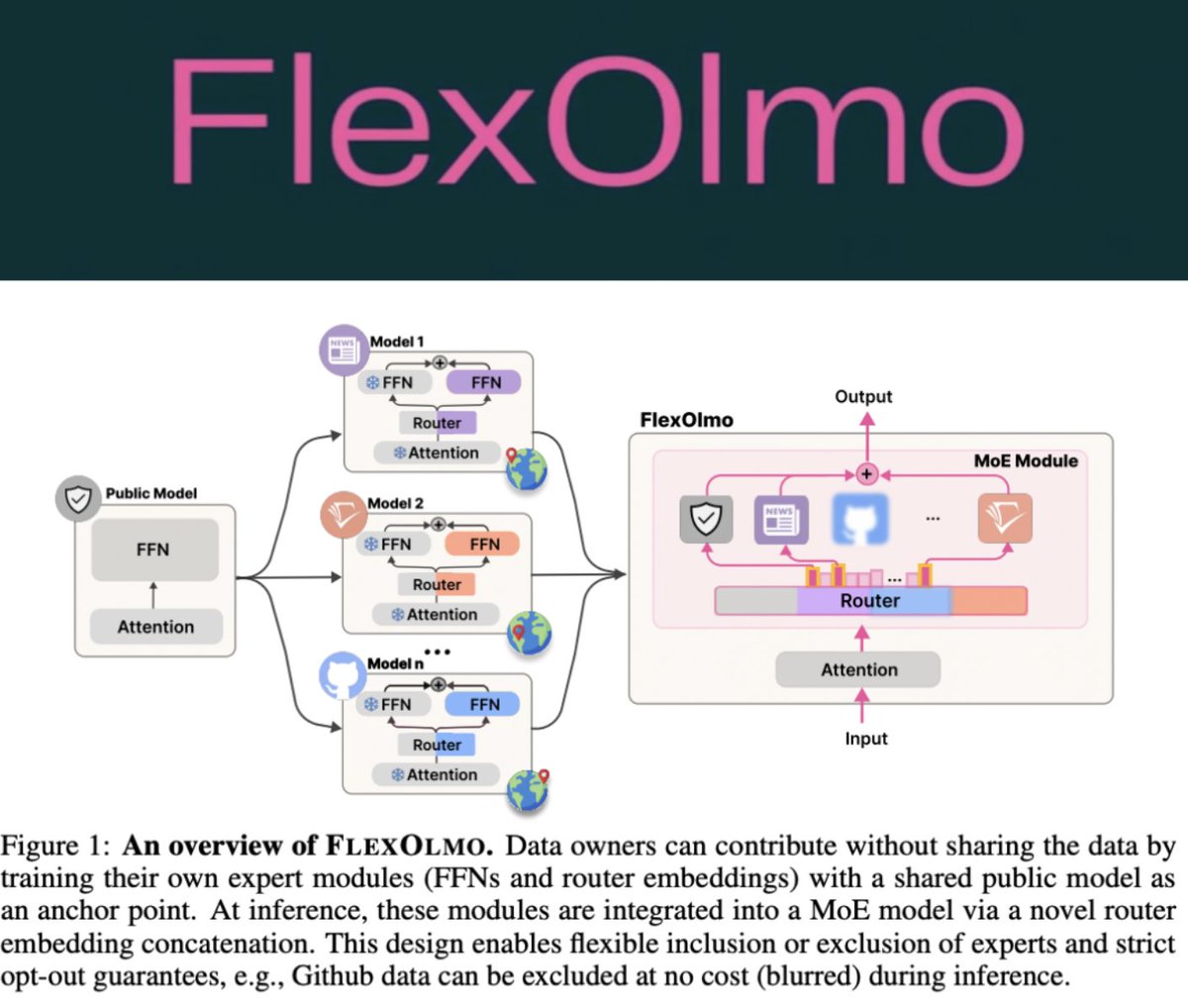
Copyrighted 🚧, private 🛑, and sensitive ☢️ data remain major challenges for AI. FlexOlmo introduces an architectural mechanism to flexibly opt-in/opt-out segments of data in the training weights, **at inference time**. (Prior common solutions were to filter your data once…
Thrilled to collaborate on the launch of 📚 CommonPile v0.1 📚 ! Introducing the largest openly-licensed LLM pretraining corpus (8 TB), led by @kandpal_nikhil @blester125 @colinraffel. 📜: arxiv.org/pdf/2506.05209 📚🤖 Data & models: huggingface.co/common-pile 1/

Come say hello at ICLR! 👋 Here's where you can find me: Friday: Data-centric AI Social! lu.ma/rmyoy2vw Saturday: Multimodal Data Provenance poster (3 pm, Hall 2B #494) Sunday: MLDPR Workshop (3 pm) [mldpr2025.com]—I'll talk about challenges to AI data…

Thrilled our global data ecosystem audit was accepted to #ICLR2025! Empirically, we find: 1⃣ Soaring synthetic text data: ~10M tokens (pre-2018) to 100B+ (2024). 2⃣ YouTube is now 70%+ of speech/video data but could block third-party collection. 3⃣ <0.2% of data from…

What are 3 concrete steps that can improve AI safety in 2025? 🤖⚠️ Our new paper, “In House Evaluation is Not Enough” has 3 calls-to-action to empower independent evaluators: 1️⃣ Standardized AI flaw reports 2️⃣ AI flaw disclosure programs + safe harbors. 3️⃣ A coordination…

I compiled a list of resources for understanding AI copyright challenges (US-centric). 📚 ➡️ why is copyright an issue? ➡️ what is fair use? ➡️ why are memorization and generation important? ➡️ how does it impact the AI data supply / web crawling? 🧵

I wrote a spicy piece on "AI crawler wars"🐞 in @MIT @techreview (my first op-ed)! While we’re busy watching copyright lawsuits & the EU AI Act, there’s a quieter battle over data access that affects websites, everyday users, and the open web. 🔗 technologyreview.com/2025/02/11/111… 1/

1/ Last week, we published the International AI Safety Report—supported by 30 nations plus the OECD, UN, and EU. Over 100 independent experts contributed. I’m thankful to play a small writing role, focusing on “Risks of Copyright.” 🔗 bit.ly/40Vm7Mu
Our updated Responsible Foundation Model Development Cheatsheet (250+ tools & resources) is now officially accepted to @TmlrOrg 2025! It covers: - data sourcing, - documentation, - environmental impact, - risk eval - model release & licensing

🪶 Some thoughts on DeepSeek, OpenAI, and the copyright battles: This isn’t the first time OpenAI has accused a Chinese company of breaking its Terms and training on ChatGPT outputs. Dec 2023: They suspended ByteDance’s accounts. 1/



Check out our recipe for adapting existing LMs for multimodal generation: it fully preserves language performances while enhancing models with visual understanding and generation🖼️

Check out our recipe for adapting existing LMs for multimodal generation: it fully preserves language performances while enhancing models with visual understanding and generation🖼️ https://t.co/QDN0GallXG

New Report, to appear at @RealAAAI 2025: The @defcon 2024 @aivillage_dc Generative Red Team 2 (GRT2) Case Study, led by @seanmcgregor The event spanned: ⚔️495 hackers, against AI2’s Olmo + WildGuard 🐞200 model flaw reports 💰$7k+ paid bounties 🔗 arxiv.org/pdf/2410.12104
✨New Report✨ Our data ecosystem audit across text, speech, and video (✏️,📢,📽️) finds: 📈 Rising reliance on web, synthetic, and YouTube data. 🛑 80%+ datasets carry hidden restrictions. 🌍 Relative representation in languages and creators has not improved for 10+ yrs.…

In this ecosystem-wide study we set out to analyze trends in data sourcing, representation, and restrictions 🔎, and develop tools to facilitate the navigation and filtering of these datasets for developers 🛠️.


New research reveals a worrying trend: AI's data practices risk concentrating power overwhelmingly in the hands of dominant technology companies. I spoke w/@ShayneRedford @sarahookr @sarahbmyers @GiadaPistilli about what this says about the state of AI technologyreview.com/2024/12/18/110…
Touching down in Vancouver 🛬 for #NeurIPS2024! I'll be presenting our "Consent in Crisis" work on the 11th: arxiv.org/abs/2407.14933 Reach out to catch up or chat about: - Training data / methods - AI uses & impacts - Multilingual scaling
Interested in how LLMs are really used? We are starting a research project to find out! In collaboration w/ @sarahookr @AnkaReuel @ahmetustun89 @niloofar_mire and others. We are looking for two junior researchers to join us. Apply by Dec 15th! forms.gle/H2o3cNCPdG8eDk…
@iclr_conf author responses are mostly ignored... and it's hurting the field. Proposal: why not require two stages of reviewing: (1) Review, and (2) Review Rebuttal—even if it is just a checkbox and re-score. Without both, reviewers shouldn't get credit.

Kaushik Doddamani @Kaushik_N_D
4 Followers 139 Following Masters in Data Science and AI @ IIT Madras
T G @arcaan_5
60 Followers 546 Following Listening is strength. Silence is foundation. Justice grows from peace. 🜁👁️
Ymwokal @Ymwokal926
9 Followers 684 Following
Nuuicarn @Nuuicarn9035
5 Followers 669 Following

Avinash Pathak @avipathak99
2 Followers 115 Following Talk about Generative AI, Large Language Models, AI, NLP
Shezan Kazi @shezankazi
40 Followers 571 Following
AMBIENT MUSIC - JAPAN... @AmbientMusicJS
338 Followers 4K Following 日本の美しい自然風景をテーマにした、心を落ち着かせるアンビエントミュージックをお届けします。 滝や森林、川など、日本の穏やかな自然音にインスパイアされた睡眠用・集中用のBGMを配信中です。 日本の自然が奏でる音色で、心と体を癒やし、日常の喧騒から離れてリラックスできるひとときをお楽しみください。
Nayan Saxena @SaxenaNayan
3K Followers 2K Following Teaching machines how to think, express, and create – one model at a time. https://t.co/Myd0l6JD0Q
SingForYou @SingForYou92128
43 Followers 4K Following
jluite @jluite2014
189 Followers 7K Following
klimen @pawel_handle
793 Followers 8K Following building https://t.co/CSpPceEAc3 https://t.co/OefVVNIqlQ https://t.co/Pe9F34MmDH https://t.co/Qg8x1JdXp3 https://t.co/LjQAQ4QX5F https://t.co/2AAV3rmFEy
Vaibhav Adlakha @vaibhav_adlakha
897 Followers 1K Following PhD candidate @MILAMontreal and @mcgillu | RA @iitdelhi | Maths & CS undegrad from @IITGuwahati Interested in #NLProc
Niel Carlson @Typhoon_q_cat
1 Followers 174 Following
Ahmad Mustafa Anis @AhmadMustafaAn1
1K Followers 5K Following Computer Vision & Deep Learning @Roll_ai Deep Learning Enthusiastic Community Lead @Cohere_Labs Ex-Fellow @ PI School of AI

Marzieh Fadaee @mziizm
2K Followers 554 Following seeks to understand language. Head of @Cohere_Labs. PhD from @UvA_Amsterdam. https://t.co/YI5NC5J5e4. [email protected].
Niklas Muennighoff @Muennighoff
9K Followers 474 Following Researching AI/LLMs @Stanford @ContextualAI @allen_ai
Thomas Palmeira @_ThomasPF
218 Followers 639 Following PhD Track candidate at @Polytechnique and @TelecomParis. Science saves lifes! #EMNLP2024 #NLP #LLM
Harrison @Harriso70784099
1 Followers 64 Following
Y. Bo @YiqingBo
0 Followers 100 Following
Shady @shadysaeed
215 Followers 6K Following An Engineer with a passion for biology, neuroscience, deeplearning and philosophy.

Yurii Filipchuk🇺�... @yfilipch
1K Followers 3K Following OpenBabylon | Boosting Global GDP with AI for Underrepresented Languages | Chaotic Good | helping AI nerds @goatstackai ¯\(ツ)/¯
Andrew Lambert 🤖 @andrewlambert88
281 Followers 4K Following Interested in scaling synthetic video data for training robot action policies
Yejie Wang @YejieWang
13 Followers 159 Following
jack @jack77280827
2 Followers 56 Following
Will Brannon @wwbrannon
640 Followers 2K Following PhD @MIT. Interests: data-centric AI, socially aware ML systems, computational social science.
Joe Fenton @JoeFenton
1K Followers 2K Following Product, Post-training @microsoft. Previously founding team @inflectionai and PM @google and @deepMind


Steve Chiou @Steveofice
74 Followers 688 Following
Pratyay Banerjee (ন... @Neilzblaze007
295 Followers 7K Following I live in the shadows, but I watch everything.

Azal Ahmad Khan @azalakhan
95 Followers 2K Following CS PhD Student @UMNComputerSci | Prev. undergrad @IITGuwahati (2020-2024)
Varun Talwar @vt_65
21 Followers 6K Following
Yougang Lyu @yougang_lyu
92 Followers 387 Following PhD student @irlab_amsterdam & @UvA_Amsterdam | Intern @Baidu_Inc | Working on language agents and alignment
Aaditya Ura @aadityaura
2K Followers 960 Following PhD @Harvard | LLMs ⚡ Healthcare | Developer of OpenBioLLM, Open Medical-LLM Leaderboard, MedMCQA, Med-Halt | I like high-quality datasets & eval 🧠

camenduru @camenduru
21K Followers 5K Following building 🥪 @tost_ai ❤ open source https://t.co/8MMNbygz1P
un gran danés con Ph... @tobygreatdane
5 Followers 538 Following
Ravi Raju @ravi_ragu
77 Followers 284 Following NLP engineer at SambaNova Systems | ECE PhD UW-Madison | MSOE EE grad
Alex Graveley @alexgraveley
37K Followers 1K Following Co-creator of GitHub Copilot, Dropbox Paper, AI Tinkerers, Hackpad, MobileCoin, Minion AI, etc. Working on @PerplexityComet. Survivor 🎗️
Eric @ericmitchellai
9K Followers 556 Following co-lead @openai post-training frontiers team w/ the great @yanndubs; I like ai and music and some other things
Qingxiu Dong @qx_dong
2K Followers 676 Following PhD student @PKU1898. Research Intern @MSFTResearch Asia.
Shuaichen Chang ✈�... @ShuaichenChang
1K Followers 971 Following Researcher at AWS AI (@AmazonScience) Ex: PhD @OhioState Opinions are my own #NLProc #LLMs #AI

Simon Yu @simon_ycl
520 Followers 785 Following 1st Year PhD Student, supervised by @shi_weiyan | Incoming intern in @OrbyAI | MRes and BSc Student @EdinburghNLP | Member of @CohereForAI
LeoLoves @Leoloveswalk
0 Followers 2 Following

Shivalika Singh @singhshiviii
1K Followers 758 Following Research Engineer @Cohere_Labs @cohere | @huggingface fellow 🤗 | “Research means that you don't know, but are willing to find out” ✨
Stella Biderman @BlancheMinerva
17K Followers 806 Following Open source LLMs and interpretability research at @AiEleuther. She/her
Marzieh Fadaee @mziizm
2K Followers 554 Following seeks to understand language. Head of @Cohere_Labs. PhD from @UvA_Amsterdam. https://t.co/YI5NC5J5e4. [email protected].
Zexue He @ZexueHe
421 Followers 146 Following Trustworthy NLP PhD @McAuleyLabUCSD. IBM Ph.D. Fellowship. Prev intern @msftresearch. Researcher @MITIBMLab. Affiliated researcher @MIT.

Seungone Kim @seungonekim
2K Followers 935 Following Ph.D. student @LTIatCMU and intern at @AIatMeta (FAIR) working on (V)LM Evaluation & Systems that SeIf-Improve | Prev: @kaist_ai @yonsei_u
Russell Kaplan @russelljkaplan
20K Followers 700 Following President @cognition. Past: director of engineering @Scale_AI, startup founder, ML scientist @Tesla Autopilot, researcher @StanfordSVL.
Manasi Sharma @ManasiSharma_
346 Followers 244 Following research engineer @scale_AI, working on reasoning for frontier models, agents, rl | prev @stanford, @StanfordAILab, @mitll, @Columbia
Alex Tamkin @AlexTamkin
6K Followers 2K Following machine learning, science & society @AnthropicAI | recently: Clio, Anthropic Economic Index, Claude Artifacts | prev: phd @StanfordAILab, @stanfordnlp
Hyung Won Chung @hwchung27
38K Followers 302 Following AI Research Scientist @Meta Superintelligence Labs. Past: @OpenAI / @Google Brain / PhD @MIT
Hao Zhang @haozhangml
6K Followers 474 Following Asst. Prof. @HDSIUCSD and @ucsd_cse running @haoailab. Cofounder and runs @lmsysorg. 20% with @Snowflake
Hailey Schoelkopf @haileysch__
5K Followers 1K Following hillclimbing towards generality @anthropicai | prev @AiEleuther | views my own
Niklas Muennighoff @Muennighoff
9K Followers 474 Following Researching AI/LLMs @Stanford @ContextualAI @allen_ai

Nazneen Rajani @nazneenrajani
5K Followers 2K Following building @collinearAI 🧪 | MIT 35u35 | UN AI Advisory Body | Featured in NYT, Quanta, Science, MIT TR| Previously: @huggingface 🤗, @SFResearch, PhD @utcompsci
Sam Bowman @sleepinyourhat
50K Followers 3K Following AI alignment + LLMs at Anthropic. On leave from NYU. Views not employers'. No relation to @s8mb. I think you should join @givingwhatwecan.
Fei Xia @xf1280
9K Followers 761 Following Staff Research Scientist, TLM at @GoogleDeepMind, ✨♊, Gemini & Robotics, PhD from @StanfordAILab @StanfordSVL, previously @Tsinghua_Uni. #AGI through Embodiment
Sara Hooker @sarahookr
49K Followers 9K Following I lead @Cohere_Labs. Formerly Research @Google Brain @GoogleDeepmind. ML Efficiency at scale, LLMs, ML reliability. Changing spaces where breakthroughs happen.
Tatsunori Hashimoto @tatsu_hashimoto
8K Followers 198 Following Assistant Prof at Stanford CS, member of @stanfordnlp and statsml groups; Formerly at Microsoft / postdoc at Stanford CS / Stats.
JHU CLSP @jhuclsp
7K Followers 6K Following Center for Language and Speech Processing at @JohnsHopkins #NLProc #MachineLearning #AI https://t.co/6IXR5OSQtw @[email protected]
Robin Jia @robinomial
4K Followers 891 Following Assistant Professor @CSatUSC | Previously Visiting Researcher @facebookai | Stanford CS PhD @StanfordNLP
Hanna Hajishirzi @HannaHajishirzi
9K Followers 443 Following Sr. Director of AI at @allen_ai, Prof at @uw_cse, lead OLMo, Tulu
Sean Ren @xiangrenNLP
13K Followers 546 Following Building @SaharaLabsAI 🍦| Professor @USCViterbi @nlp_usc | @MIT TR 35 , @ForbesUnder30 | Prev: @allen_ai, @Snapchat, @Stanford, @UofIllinois
Yao Fu @Francis_YAO_
20K Followers 2K Following Research Scientist at @GoogleDeepMind I study complex, multimodal, interactive reasoning. Opinions are my own
Daniel Khashabi 🕊�... @DanielKhashabi
3K Followers 910 Following I play with intuitions and data. Now: @jhuclsp @jhucompsci Past: @allen_ai @uwnlp @Penn @cogcomp, @Illinois_Alma, @MSFTResearch He/Him
Yizhong Wang @yizhongwyz
6K Followers 1K Following Incoming assistant professor @UTCompSci, RS @BytedanceTalk, PhD from @uwcse, formerly @allen_ai @AIatMeta @MSFTResearch
Qinyuan Ye @qinyuan_ye
2K Followers 2K Following ☁️ Research Scientist @SFResearch | 🐾 Teaching machines to be versatile and curious. | Prev @nlp_usc
Shayne Longpre @ShayneRedford
6K Followers 1K Following Lead the Data Provenance Initiative. PhD @MIT. 🇨🇦 Prev: @Google Brain, Apple, Stanford. Interests: AI/ML/NLP, Data-centric AI, transparency & societal impactTrends for United States
You might like



















