
-
Tweets53
-
Followers24
-
Following284
-
Likes157

@soheeyang_ @GoogleDeepMind @KassnerNora @elenagri_ @riedelcastro @dhgottesman @DanaRamati @GurYoav @IdoC0hen @RGiryes 📍2025-07-30 9:00 - 10:30 Room 1.85 @AmitElhelo will introduce MAPS, a general framework for inferring the functionality of attention heads in LLMs directly from their parameters. x.com/megamor2/statu…
@soheeyang_ @GoogleDeepMind @KassnerNora @elenagri_ @riedelcastro @dhgottesman @DanaRamati @GurYoav @IdoC0hen @RGiryes 📍2025-07-30 9:00 - 10:30 Room 1.85 @AmitElhelo will introduce MAPS, a general framework for inferring the functionality of attention heads in LLMs directly from their parameters. x.com/megamor2/statu…


Anyone knows adam?


👉 New preprint! Today, many the biggest challenges in LM post-training aren't just about correctness, but rather consistency & coherence across interactions. This paper tackles some of these issues by optimizing reasoning LMs for calibration rather than accuracy...

👉 New preprint! Today, many the biggest challenges in LM post-training aren't just about correctness, but rather consistency & coherence across interactions. This paper tackles some of these issues by optimizing reasoning LMs for calibration rather than accuracy...


✨ New paper ✨ 🚨 Scaling test-time compute can lead to inverse or flattened scaling!! We introduce SealQA, a new challenge benchmark w/ questions that trigger conflicting, ambiguous, or unhelpful web search results. Key takeaways: ➡️ Frontier LLMs struggle on Seal-0 (SealQA’s…



Are AI scientists already better than human researchers? We recruited 43 PhD students to spend 3 months executing research ideas proposed by an LLM agent vs human experts. Main finding: LLM ideas result in worse projects than human ideas.


I’m looking for a new postdoc to start this fall working on AI for Science/Science-Inspired AI (focusing on chemistry and bioengineering domains for now). Please drop me a CV if interested.

The paper claims coding benchmarks high scores of LLMs may come from memorizing past GitHub issues, not real reasoning.😯 The authors build a tiny test: given only the text of an issue, guess the file path that needs fixing. Models hit up to 76% accuracy on the benchmark set,…

LLM reasoning with reinforcement learning focuses on limited domains, hindering general applicability. This paper develops GURU, a 92,000-example multi-domain dataset, to enable broader reinforcement learning-based reasoning. Methods 🔧: - GURU includes Math, Code, Science,…

Large language models exhibit grokking, where generalization improves significantly long after training loss converges. This paper identifies grokking in large-scale LLM pretraining and provides internal metrics to monitor this delayed generalization without external validation.…


Neat work by my awesome colleagues

Neat work by my awesome colleagues

A bit late but happy to share that LLM-SRBench, our new benchmark targeting memorization issue in LLMs for scientific discovery is selected for *Oral* presentation at #ICML2025 ! Great to see the community recognizing the importance of this direction. Checkout the camera-ready…
A bit late but happy to share that LLM-SRBench, our new benchmark targeting memorization issue in LLMs for scientific discovery is selected for *Oral* presentation at #ICML2025 ! Great to see the community recognizing the importance of this direction. Checkout the camera-ready…


🚨New paper! We know models learn distinct in-context learning strategies, but *why*? Why generalize instead of memorize to lower loss? And why is generalization transient? Our work explains this & *predicts Transformer behavior throughout training* without its weights! 🧵 1/
This is really BAD news of LLM's coding skill. ☹️ The best Frontier LLM models achieve 0% on hard real-life Programming Contest problems, domains where expert humans still excel. LiveCodeBench Pro, a benchmark composed of problems from Codeforces, ICPC, and IOI (“International…

This study shows the same models break down on Olympiad problems and cannot even flag their own faulty proofs. Showed that frontier LLM handle fewer than 4 % of Olympiad proofs correctly and misjudge their own flawed reasoning. Current math benchmarks mark a right answer and…



❓How to balance negative and positive rewards in off-policy RL❓ In Asymmetric REINFORCE for off-Policy RL, we show that giving less weight to negative rewards is enough to stabilize off-policy RL training for LLMs! 💪 (1/8) Paper: arxiv.org/abs/2506.20520

We’re hiring @Apple! 📢 Looking for a Computer Vision / ML Engineer to join our team. Work on cutting-edge AI at scale. lnkd.in/gkE_varC Contact me if interested! #ML #ComputerVision #AppleJobs #hiring #hiringNow

Exciting new RL tooling: A modular library for RL training by the Berkeley NovaSky team. While standard RL training is all done in one loop, it is more efficient for modern post-training to separate the generation of the rollouts from the trainer. It also enables asynchronous…

Exciting new RL tooling: A modular library for RL training by the Berkeley NovaSky team. While standard RL training is all done in one loop, it is more efficient for modern post-training to separate the generation of the rollouts from the trainer. It also enables asynchronous…

Github: A fully open source framework for creating RL training swarms over the internet. Train reinforcement-learning models collaboratively across decentralized peers, leveraging GenRL-Swarm on consumer laptops or GPUs Plug into a global swarm, contribute compute, and…

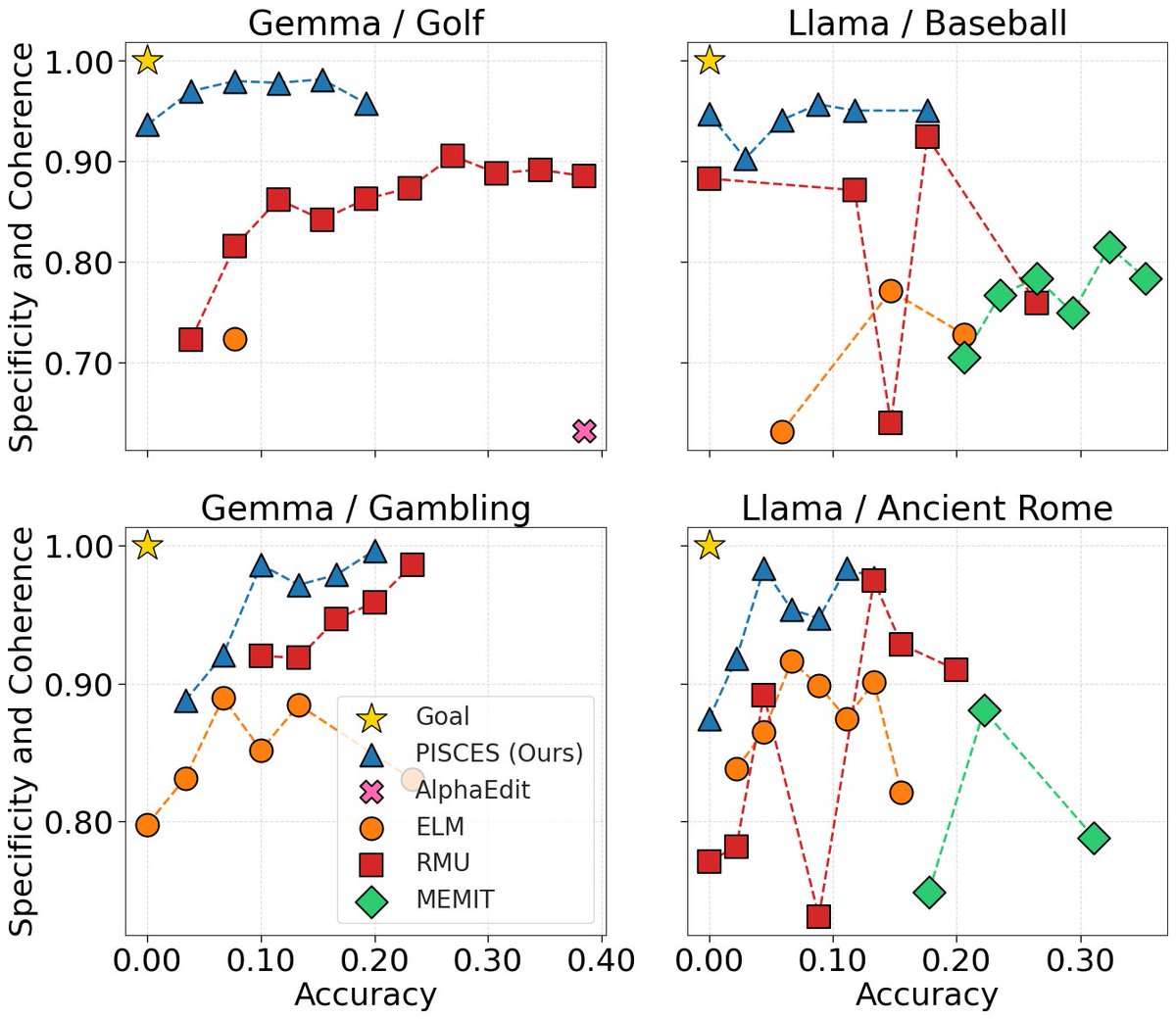
Removing knowledge from LLMs is HARD. @GurYoav proposes a powerful approach that disentangles the MLP parameters to edit them in high resolution and remove target concepts from the model. Check it out!

Removing knowledge from LLMs is HARD. @GurYoav proposes a powerful approach that disentangles the MLP parameters to edit them in high resolution and remove target concepts from the model. Check it out!

How Well Can Reasoning Models Identify and Recover from Unhelpful Thoughts? "We show that models are effective at identifying most unhelpful thoughts but struggle to recover from the same thoughts when these are injected into their thinking process, causing significant…





Connor Treacy @theconnortreacy
18K Followers 13K Following
Asheswari Swain @Asheswari_Swain
343 Followers 920 Following
Yibin Wang @Yibin_Wang_
101 Followers 490 Following Intern @ UIUC | Prev Intern @RutgersU | B.E. @2024_HUST
Qiko @Qiko690
100 Followers 2K Following
Tenghao Huang @TenghaoHuang45
382 Followers 449 Following Ph.D. Candidate @USC |B.S. @UNC | Intern @microsoft @ibm @amazon | LLM Agent & Creativity 🤖 📖💡🏅
Oxeevou @Oxeevou39012
21 Followers 1K Following
Peymànn M. Kiasari @PKiasari
28 Followers 113 Following ML researcher and engineer | currently focusing on computer vision, especially DS-CNNs
Joe Stacey @_joestacey_
2K Followers 2K Following NLP postdoc at @SheffieldNLP Ex @Imperial_NLP PhD, @Apple AI/ML Scholar, @UCL MSc Model robustness and now uncertainty quantification
Mengjie Zhao @mengjie_zhao
290 Followers 609 Following an NLP researcher @SBIntuitions @Softbank. Views my own. Previously researcher @Sony, phd @CisLmu. #nlproc
Thinh @thinhphp_vt
71 Followers 497 Following PhD student @VT_CS, supervised by @tuvllms. Interested in search-augmented LLMs. Ex AI resident @VinAI_Research
Zhefei Gong @zhefeigong
140 Followers 2K Following Robot Learning | Looking for 2026 Spring/Fall Phd Opportunities
Xinyan (Lily) Gao @LilyGao_ML
4 Followers 88 Following I'm currently an undergraduate student at the Chinese University of Hong Kong.
InsightEd Writers (Es... @InsightEwriters
239 Followers 1K Following Get expert HELP with Essay, Exam, Quiz, Online class, Discussion, Homework, Assignments, ppt, Thesis, Research Paper and more. DM +1 (520) 203-5047
Margaret Rickss @DisneyMargaret1
2K Followers 2K Following So you want to hear a couple of general and useless tweets?
Pooja Algikar @algikarpooja
150 Followers 345 Following postdoc @argonne. real time situational awareness, data-driven and robust uncertainty quantification for real-time decision making
Ghazal Khalighinejad @ghazalkhn
307 Followers 428 Following CS PhD @duke_nlp, Intern @Google | Foundation Models & AI4Science | Guest Researcher @SimonsFdn @PolymathicAI prev @AdobeResearch
Ahmet Kaya @ai_ahmetkaya
239 Followers 2K Following ML @Apple · PhD in Physics (@CarnegieMellon)· Working on computer vision & vision-language models · Scaling AI in the real world
Parshin Shojaee @ParshinShojaee
3K Followers 1K Following PhD student @VT_CS | AI for Science, Math, Code, Reasoning | Intern @Apple | prev @Adobe
Plum Lab @LabPlum
24 Followers 138 Following Research lab from UC Davis(@ucdavis) specializing in #NLP, #Multimodal, and #AI4Science (particularly on #LLMs and #VLMs). Directed by Prof. @lifu_huang
JohnSnowLabs @JohnSnowLabs
44K Followers 30K Following Helping healthcare and life science organizations put AI to work faster with state-of-the-art LLM & NLP.
Etienne Gauthier @Gauthier_E_
145 Followers 220 Following PhD Student @Inria @ENS_ULM | Multi-agent decision-making, uncertainty quantification
erisa @erisaonX
6K Followers 880 Following PhD student in Mathematics @ UTAustin. Interested in nonlocal PDEs, Deep Learning and LLMs. ✨
Garry Kasparov @Kasparov63
1.1M Followers 1K Following VP of @WLCongress. Founder & Chair of @Renew_Democracy. Activist, speaker, 13th World Chess Champion. Autocracy in America podcast: https://t.co/xemlxTR3IN
Jiao Sun @sunjiao123sun_
12K Followers 572 Following Senior Research Scientist at Google DeepMind \n\n NLP PhD @ USC, Amazon ML Fellow \n\n ex-{Google Brain, Alexa AI} nlper, IIIS Tsinghua-Ren
Zach Brown @the_zb_
5K Followers 779 Following Worshipper, ponderer, husband, father, and friend. Forza Ferrari!
brakeboosted @brakeboosted
22K Followers 484 Following 📈 self-taught, still learning • 📌 tifoso, motorsport enthusiast, independent technical analyst, live commentary • 📧 [email protected]
Tenghao Huang @TenghaoHuang45
382 Followers 449 Following Ph.D. Candidate @USC |B.S. @UNC | Intern @microsoft @ibm @amazon | LLM Agent & Creativity 🤖 📖💡🏅
Qian Huang @qhwang3
14K Followers 331 Following prev @xai | CS PhD student @StanfordAILab (on leave)
Sang Cho @Saaaang94
2K Followers 465 Following reasoning @xAI | prev-founding engineer @anyscalecompute | senior committer of @raydistributed | committer @vllm_project Sglang | Github: rkooo567
Samaneh Saadat @smn_sdt
363 Followers 266 Following ML SWE @Google | CoreML, Keras | Opinions my own
Taiwei Shi @taiwei_shi
1K Followers 405 Following AI Researcher & Ph.D. student @nlp_usc. Intern @MSFTResearch. Formerly @GeorgiaTech @USC_ISI. NLP & Computational Social Science.
Dimitris Papailiopoul... @DimitrisPapail
20K Followers 1K Following Researcher @MSFTResearch, AI Frontiers Lab; Prof @UWMadison (on leave); learning in context; thinking about reasoning; babas of Inez Lily.
Niloofar (✈️ ACL) @niloofar_mire
7K Followers 2K Following Niloofar Mireshghallah — incoming asst. prof @LTIatCMU @CMU_EPP, RS in @AIatMeta, postdoc @uwcse, Ph.D. @ucsd_cse, former @MSFTResearch -Privacy, ML, NLP
Dan Roy @roydanroy
57K Followers 2K Following ML / AI researcher. Research Director and Canada CIFAR AI Chair, @VectorInst. Professor, @UofT (Statistics/CS).
Ahmad Beirami @abeirami
10K Followers 4K Following sth new // ex Gemini RL+Inference @GoogleDeepMind // Chat AI @Meta // RL Agents @EA // ML+Information Theory @MIT+@Harvard+@GeorgiaTech // زن زندگی آزادی
Mengdi Wang @MengdiWang10
4K Followers 1K Following Professor @Princeton in AIML. Co-Director of #Princeton AI^2. Program Chair @ICLR2023. Formerly @MIT @GoogleDeepmind @Tsinghua. my Erdos number: 3

Matt Gallagher @MattP1Gallagher
913K Followers 438 Following Co-Founder of @MattP1Tommy. Presenter/Commentator [email protected]
P1 with Matt & Tommy @MattP1Tommy
137K Followers 19 Following Two F1 fans bringing you all the latest news, reaction, opinion and predictions from the best sport in the world! Business: [email protected]
Shakir Mohamed @shakir_za
45K Followers 1K Following ML with Social Purpose. @[email protected] | Research Scientist @DeepMind | Strengthening African ML @DeepIndaba. He/Him. South African 🇿🇦🏳️🌈🌍
Charles Sutton @RandomlyWalking
17K Followers 1K Following Research scientist @GoogleAI / Previously academic @InfAtEd / Deep learning to help people write code. / @[email protected] / ❤️s:🐱🐶☕️🍕
Tim Rocktäschel @_rockt
39K Followers 2K Following Director and Open-Endedness Team Lead @GoogleDeepMind, Professor of AI @AI_UCL, PI @UCL_DARK, Fellow @ELLISforEurope.
Richard Socher @RichardSocher
112K Followers 1K Following CEO @youdotcom MP @aixventuresHQ Before: Stanford Adj Prof in AI/NLP, Chief Scientist at Salesforce, MetaMind

PyTorch @PyTorch
451K Followers 77 Following Tensors and neural networks in Python with strong hardware acceleration. PyTorch is an open source project at the Linux Foundation. #PyTorchFoundation
Fei-Fei Li @drfeifei
519K Followers 1K Following Prof (CS @Stanford), Co-Director @StanfordHAI, Cofounder/CEO @theworldlabs, #AI #SpatialIntelligence #GenAI #computervision #robotics #AI-healthcare
Mustafa Suleyman @mustafasuleyman
168K Followers 487 Following CEO, Microsoft AI | Author: The Coming Wave | Past: Co-founder, @InflectionAI & @GoogleDeepMind
Neil Lawrence @lawrennd
38K Followers 7 Following Professor of machine learning at the University of Cambridge. Opinions are my own. Author of "The Atomic Human" Mainly found on @lawrennd.bsky.social
Edward Grefenstette @egrefen
42K Followers 865 Following FR/US/GB AI/ML Person, Director of Research at @GoogleDeepMind, Honorary Professor at @UCL_DARK, @ELLISforEurope Fellow. All posts are personal.
Yee Whye Teh @yeewhye
25K Followers 1K Following Find me @[email protected] Professor at @OxCSML, @oxfordstats and Research Director at @GoogleDeepMind. All opinions are my own.
Behnam Neyshabur @bneyshabur
29K Followers 857 Following Research @AnthropicAI (Co-lead Discovery team) 💼 Past: Gemini @GoogleDeepMind (Co-led Blueshift team) 🧠 LLM Reasoning / AI Scientist 🎒Traveling & Backpacking
Barret Zoph @barret_zoph
21K Followers 1K Following CTO & Co-Founder Thinking Machines Lab (@thinkymachines) Past: - VP Research (Post-Training) @openai - Research Scientist at Google Brain

Jürgen Schmidhuber @SchmidhuberAI
163K Followers 0 Following Invented principles of meta-learning (1987), GANs (1990), Transformers (1991), very deep learning (1991), etc. Our AI is used many billions of times every day.
Hugging Face @huggingface
560K Followers 208 Following The AI community building the future. https://t.co/VkRPD0Vclr

Zachary Lipton @zacharylipton
63K Followers 2K Following Cofounder & CTO: @AbridgeHQ, Professor: CMU/@acmi_lab, Creator: @d2l_ai & https://t.co/QQt98VNLUp, Relapsing 🎷
Sebastien Bubeck @SebastienBubeck
56K Followers 1K Following I work on AI at OpenAI. Former VP AI and Distinguished Scientist at Microsoft.
Sham Kakade @ShamKakade6
16K Followers 495 Following Harvard Professor. Full stack ML and AI. Co-director of the Kempner Institute for the Study of Artificial and Natural Intelligence.
Quanquan Gu @QuanquanGu
16K Followers 2K Following Professor @UCLA, Pretraining and Scaling at ByteDance Seed | Recent work: Build AGI | Opinions are my own
Andrej Risteski @risteski_a
3K Followers 2K Following Machine learning researcher. Associate Professor, ML department at CMU (@mldcmu).
Hossein Mobahi @TheGradient
6K Followers 761 Following Senior Research Scientist @GoogleDeepMind. I ∈ Optimization ∩ Machine Learning. Fan of @IronMaiden🤘.Here to discuss research 🤓

Simon Shaolei Du @SimonShaoleiDu
9K Followers 2K Following Assistant Professor @uwcse. Postdoc @the_IAS. PhD in machine learning @mldcmu.
Zhuoran Yang @zhuoran_yang
2K Followers 1K Following Assistant Professor of Statistics and Data Science @Yale
Dongruo Zhou @DongruoZ
382 Followers 150 Following Assistant Professor of Computer Science, Indiana University
Lunjia Hu @LunjiaH
468 Followers 278 Following Assistant Prof @Northeastern @KhouryCollege. Prev Postdoc Fellow @Harvard @HCRCS. CS PhD @StanfordTheory, Yao Class undergrad @Tsinghua_Uni
Frances Ding @FrancesDing
275 Followers 120 Following PhD student in EECS, UC Berkeley. ML fairness and interpretability. ML for protein design.
Norman Mu @TheNormanMu
2K Followers 804 Following
Jack Wang @_zichaowang
62 Followers 200 Following Research Scientist @AdobeResearch. AI for human learning, productivity, and creativity. Prev. Ph.D. student @RiceECE. ex-intern @GoogleAI @NVIDIA @MSFTResearch
Naftali Bennett נפ�... @naftalibennett
670K Followers 1 Following ראש הממשלה ה-13 של מדינת ישראל • 13th Prime Minister of IsraelTrends for United States
You might like



















