Research Graph @researchgraph
Connecting Scholarly Communications researchgraph.org Melbourne, Victoria Joined May 2014-
Tweets231
-
Followers67
-
Following8
-
Likes6
RAG: Supercharging AI with Smart Data Retrieval aigraph.researchgraph.org/2023/11/13/rag…
Platform to assess applications to access sensitive data. Safe person? Correct data for correct project? youtu.be/BbT_3qyeDM0?si…
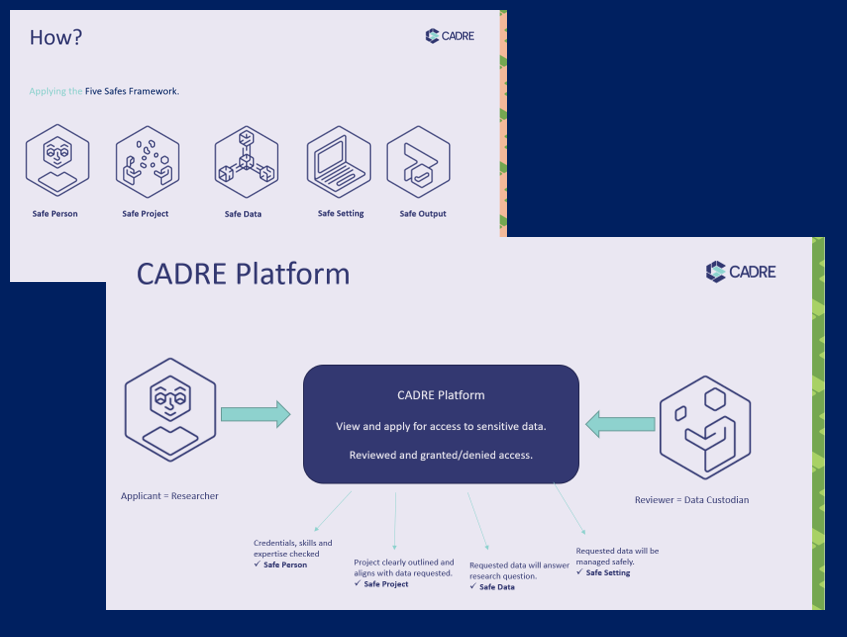
Platform to assess applications to access sensitive data. Safe person? Correct data for correct project? youtu.be/BbT_3qyeDM0?si… https://t.co/6XZNGLCcJ6

Great to see Reproducible Outputs as one of the new functions of GPT-4 platform.openai.com/docs/guides/te… #gpt #artificalintelligence
15 New Initiatives in the New White House Order on AI aigraph.researchgraph.org/2023/11/06/15-…
While they are effective in understanding and generating natural language, they have limitations such as producing incorrect responses, known as the hallucination effect. This can lead to potential risks in clinical settings, especially in areas like imaging appropriateness
Large language models (LLMs) like ChatGPT, developed by OpenAI, have shown success in various tasks due to their advanced architecture and training mechanisms. #aigraph pubs.rsna.org/doi/10.1148/ra…
Mistral AI is 187x cheaper compared to GPT-4 aigraph.researchgraph.org/2023/10/27/mis…

Feature engineering refers to the process of creating new input variables from the available data. #aigraph machinelearningmastery.com/data-preparati…
data preparation can be treated as another hyperparameter to tune as part of the modeling pipeline. machinelearningmastery.com/framework-for-…
Transformers, introduced in 2017, are a pivotal architecture for LLMs, designed around the concept of attention, which helps process longer text sequences efficiently developers.google.com/machine-learni… #LLM #NLP
Google Bard will destroy ChatGPT because it’s a long-term game, and Google has the upper hand in terms of market dominance. ChatGPT has a better product, but that doesn’t mean they’ll win the long race. #aigraph medium.com/@alanany/the-c…
This post details how to apply three core UX concepts to generative AI products: 1) affordances, 2) feedback, and 3) constraints. #aigraph towardsdatascience.com/the-design-of-…
Engineers can now test models without worrying about privacy concerns since generative AI can produce large amounts of synthetic data that mirrors real-world information #aigraph towardsdatascience.com/5-generative-a…
Large language models have found applications in a wide range of fields, transforming the way we interact with technology and enabling new possibilities, including NLP, Chatbots and virtual assistants, automation, Language translation, etc. #aigraph indatalabs.com/blog/large-lan…
Dimensionality reduction results in fewer input variables which allows for a simpler predictive model that may have better performance when making predictions on new data. #aigraph machinelearningmastery.com/linear-discrim…
The output of the OCR process is a text that contains typos, recognition mistakes, non-text symbols, and other inaccuracies. Another challenge that machine learning engineers face is what to define as a word like Chinese, Japanese, or Arabic. #aigraph indatalabs.com/blog/nlp-chall…
LLMs cannot understand written text directly, so Sentence Embedding is carried out. Thanks to the large dimension of the vector created by embedding, small variations in the data can be seen with greater precision. #aigraph towardsdatascience.com/mastering-cust…
With just a simple, but powerful calculation like the Cosine Similarity, we can build a reasonable recommendation system. #aigraph towardsdatascience.com/what-to-bring-…
Applying LLM on the keyword research will be a revolution of seo. #aigraph techopedia.com/12-practical-l…
LLMs have many specific types. Autoregressive language models, Transformer-based models, Encoder-decoder models, Pre-trained and fine-tuned models, Multilingual models, and Hybrid models. For instance, LLaMa2 we are using is transformer-based. #aigraph spiceworks.com/tech/artificia…

Vaishnavi Bhargava @vaishnavi_legal
657 Followers 7K Following Indian Lawyer & Researcher | Environment Advocate in Making | Lifelong Learner | Retweet ≠ Endorsement.
Cassyni @cassyniapp
1K Followers 5K Following Organise, run, and publish research seminars. For upcoming seminars follow @CassyniSeminars
Hugo Vides @hvidesa
210 Followers 2K Following
Jacob Zeitlin @jacobzeitlin
167 Followers 467 Following
SYC @SYCa000
3 Followers 5 Following
Aishwarya Nambissan @AishLearnsAI
5 Followers 6 Following
YunLearnAI @YunLearnAI
4 Followers 7 Following
LN Anderson @lnanderscience
140 Followers 1K Following Scientist @PNNLab 👩🏼🔬 Multi-Omics Research 👩💻 Man Cityzen 🦈⚽️ Lover of Stratovolcanoes 🌋 Omics Champion @FAIRsharing_org | opinions my own
Susan Wilson @pscwilson
10 Followers 154 Following
⚛ AtomGraph @atomgraphhq
2K Followers 3K Following We build #KnowledgeGraph management solutions and lead the way to data-driven Web applications. LinkedDataHub: https://t.co/pGlS0zCpEu
Shawna Sadler @ShawnaSadler
732 Followers 3K Following ORCID Engagement Manager, Outreach & Partnerships. Likes to laugh, strong supporter of women in sports and missing Carrie Fisher. Tweets are my own.

@[email protected]... @SoerenAuer
4K Followers 856 Following Director @TIBHannover working on #Digitalization of #Science & #Technology leveraging #KnowledgeGraphs, Researcher @UniHannover & @L3S_LUH Co-founder: @Eccenca
Jen Gibson @jmclenna
674 Followers 590 Following #openresearch and #openinfra champion. @datadryad Executive Director. chair of @oaspa. mom, wife, friend & yogi. views are just mine. she/her 🇨🇦🇺🇸🇬🇧
Hakuna Ma Data @hakuna_ma_data
70 Followers 489 Following Data Librarian - Documentaliste, nouvellement spécialisée en données de la recherche - #OpenScience #OpenData (j'ai piqué ma pp à @datactivi_st)

Catherine Ferris @drcferris
218 Followers 252 Following IReL Open Scholarship Officer: Project Manager for the NORF-funded National Open Access Monitor Project, Lead for the Irish ORCID & DataCite Consortia
CADREAUS @cadreaus
131 Followers 185 Following Coordinated Access for Data, Research and Environments - A Five Safes Implementation Framework for Sensitive Data in Humanities, Arts, and Social Sciences (AU)

Sci-K @ ISWC2025 @scik_workshop
384 Followers 369 Following 5th International Workshop on Scientific Knowledge: Representation, Discovery, and Assessment (Sci-K) co-located @iswc_conf 2025 in Nara, Japan
Researcherssite-Acade... @researcherssite
340 Followers 2K Following
srinivasbojja @srinivas_bojja3
83 Followers 2K Following CS Grad Student @NJIT| CBIT hyderabad Alumnus | loves Basketball, tennis | michael jordan23🏀 & federer fan🎾.
Andrea Mannocci @andr... @andremanno
570 Followers 777 Following Researcher @infrascience @IstiCnr. Data scientist & wrangler, ICT eng. ❤️ #Scientometrics #OpenScience #ScholComms Spare time surfer, guitarist & photographer
RefResh Workshop (#Re... @refreshworkshop
92 Followers 274 Following #RefResh22 3rd workshop on Reframing Research @tpdl2022 🗓️ 20 September 2022📍Padua, Italy Organisers: @andremanno @FraOsborne @paolomanghi

TGraph_2020 @2020Tgraph
2 Followers 16 Following Created a twitter account solely for this request only to find out that DM is not possible...
Scientific Knowledge ... @skgworkshop
377 Followers 184 Following 1st Workshop on Scientific Knowledge Graphs (#SKG2020) at @TPDL2020 This account is not very active lately. Please follow @scik_workshop
BiblioInformática UD... @BiblioInf_UDC
851 Followers 1K Following Biblioteca da Facultade de Informática da Universidade da Coruña
Angelo A. Salatino (@... @angelosalatino
1K Followers 840 Following Research Fellow and Associate Lecturer - @OpenUniversity (@kmiou). Interests: #AI #KnowledgeGraphs #SciSci #NetworkScience & #SemWeb. Juve fan. wd:Q58225772
Ellen Fest @EllenFest
315 Followers 808 Following Wageningen University Library | bibliometrics | scholarly communication | scientific publishing | Pure | SciVal | soil chemistry | running & yoga
Nobuko Miyairi @NobukoMiyairi
817 Followers 959 Following Scholarly Communications Consultant. Open science advocate. Rogue librarian. Dachshund lover. https://t.co/VZs0QODYvN
Knimbus @knimbusindia
936 Followers 358 Following Knimbus provides a one-stop solution to transform your library for a digital future.
&mut Agora @NeotenicPrimate
224 Followers 3K Following Computational Social & Network Science. Rust & Python. ML/NLP. Supply Chains.
Aaron Tay @aarontay
7K Followers 1K Following I'm librarian (Head, Data services) + blogger from Singapore Management University. Library science, Bibliometrics, academic discovery tech.
Onur Akdaş @gurbetinegi
45 Followers 319 Following Researcher @DEU_Denizcilik Maritime Faculty | Research Interests on #Social_Marketing #Coastal_Areas #Behaviour_Change
Mohammad Shafahi @mshafahi
16 Followers 203 Following Passionate about People and Data, all tweets are personal opinions
Ingrid Mason 👉 aus... @1n9r1d
3K Followers 4K Following Metadata nerd, tech head 👾 GLAMR data🏺 AU+ANZ #AI4LAM #DigitalHumanities #DataScience #LODLAM #OpenScience #Analytics #AI #DataEthics enthusiast. Own views.
Vladimir Alexiev @valexiev1
1K Followers 315 Following Chief Data Architect at Ontotext. Semantic web, data modeling, integration, knowledge graphs. Cultural heritage, DBpedia, Wikidata, financial, legal...

Elsevier Labs @ElsevierLabs
3K Followers 340 Following We research and create new technologies to improve the way knowledge is conveyed and used. We want to improve how science is communicated.
mstdn.social/@joelher... @jherndon01
320 Followers 1K Following Data professional working in Duke Libraries’ Center for Data and Visualization Sciences, occasionally seen @duke_data.
Konrad Förstner 💻... @konradfoerstner
2K Followers 1K Following Open Science|Source|Data|Access|* enthusiast at @ZB_MED + @th_koeln, @NFDI4Microbiota, 1/2 of @opensciradio, he/him💻🧬 (opinions + typos are my own)
R⓪ss Mounce @rmounc... @rmounce
6K Followers 4K Following I’m not really present here anymore. What made Twitter great back in the day was the people, the community. Find me over in the fedi: @[email protected]
The DMP Tool @TheDMPTool
1K Followers 282 Following Helping You Build Your Data Management Plan. Brought to you by the @UC3CDL team at @CalDigLib
🐘 @libcce@fosstodo... @libcce
2K Followers 3K Following Chris Erdmann, Head of Open Science, @SciLifeLab_DC @scilifelab - Mastodon: https://t.co/v4f2i9CG09
VIVO @VIVOcollab
2K Followers 927 Following VIVO is a member-supported #opensource software and an #ontology for representing scholarship. #research #openaccess #openscience #semantics #community
Adeline Grard @AdelineGrard
91 Followers 385 Following Data Governance Officer @CIRB. Phd in public health. Love political debate.
Alex Viggio @aviggio
593 Followers 1K Following Personal acct @CUBoulder faculty info program manager. Past lead @VIVOCollab @AgileDenver. Pro democracy, dialogue, libraries, science, data access & literacy.
Mark Fallu @brisvegas1
1K Followers 5K Following Digital & I.T. Lead (Research) Chancellery @ The University of Melbourne
Scientific Data @ScientificData
25K Followers 645 Following An #openaccess publication from Nature Research for the description of #scientifically valuable #datasets.
Elon Musk @elonmusk
225.5M Followers 1K Following
World of Statistics @stats_feed
4.3M Followers 446 Following There are three kinds of lies: lies, damned lies, and statistics. Sister page of @engineers_feed
Shuyi @Shuyi817
3 Followers 2 Following
SYC @SYCa000
3 Followers 5 Following
YunLearnAI @YunLearnAI
4 Followers 7 Following
Aishwarya Nambissan @AishLearnsAI
5 Followers 6 Following
CADREAUS @cadreaus
131 Followers 185 Following Coordinated Access for Data, Research and Environments - A Five Safes Implementation Framework for Sensitive Data in Humanities, Arts, and Social Sciences (AU)
Amir Aryani @amir_aryani
370 Followers 201 Following Head of Social Data Analytics (SoDA) Lab at Swinburne University of TechnologyTrends for United States
You might like