
Recent language models like BERT and ERNIE rely on trendy layers based on transformer networks and require lots of compute. Deep learning researcher @Smerity shows these layers and enormous GPUs may not be necessary: bit.ly/2QZXxWV
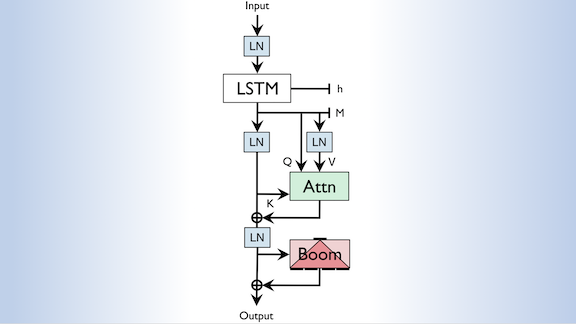

@DeepLearningAI_ @AI_Fund @Smerity "The attention mechanism is also readily extended to large contexts with minimal computation. Take that Sesame Street. " This was their reaction: i.imgur.com/SzhmLOg.jpg

@DeepLearningAI_ @Smerity I read this a while ago and thought it was a joke. Is this actually serious? I loved the "take that, sesame street" line


@DeepLearningAI_ @egrefen @Smerity I like the tone of the abstract. Maybe can read it further. :)

@DeepLearningAI_ @Smerity Dumb question.....what is evergreen wikitext initiative...... can't find any reference anywhere...from the short description in the paper... sounds very interesting....