
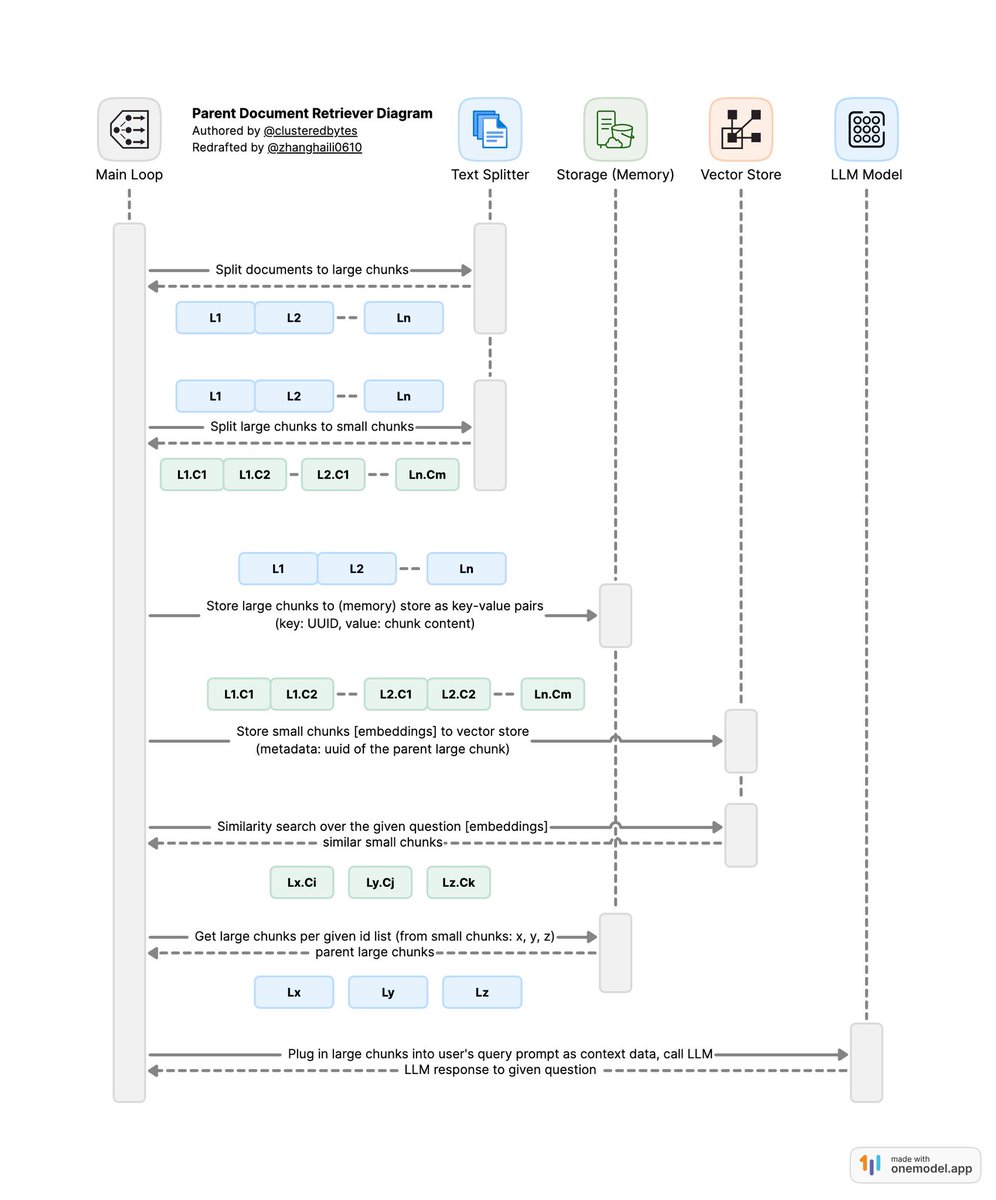
🥬MongoDB Parent Document Retriever The fact that @MongoDB is a full-fledged document store, with its own query language, makes it perfect for more advanced retrieval techniques like "Parent Document Retrieval" - so we added a template to get started easily 👨👨👦Parent Document Retrieval is a retrieval technique where you first create larger "parent" documents, and then create smaller "child" chunks for each of those documents. You then create embeddings for all of the CHILD chunks 🔎During retrieval, you first look up semantically similar child chunks. The fact that you are looking up smaller chunks helps find the most relevant chunks 📃The issue with looking up smaller chunks, is that if you pass those directly to the LLM they may lack the necessary context. Parent Document Retriever overcomes this by passing NOT the child chunks, but instead the parent documents, to the LLM s/o @zhanghaili0610 for this awesome diagram Check out the full 🦜🏗️ @MongoDB LangChain Template for an easy way to get started with this: github.com/langchain-ai/l…

@LangChainAI @MongoDB Has anyone tried the following: PDR with similarity score threshold search type, the retrieved parent docs passed to a gpt-3.5-turbo-16k LLM which asked to select (not summarize) the relevant parts of retrieved docs and pass them to a gpt-4 ?

@LangChainAI @MongoDB I would love to see it in LangchainJS!

@LangChainAI @MongoDB Great! The diagram is so easy to understand. This way is very useful for book search once we just remember a bit.


@LangChainAI @MongoDB @zhanghaili0610 what tool do you use to create such wonderful diagrams ?

@LangChainAI @MongoDB Parent/child relationships are only the beginning! You could model this recursively with $graphLookup, query multiple vectors for a single document and merge results together, and do so much more within the document model. More coming soon!

@LangChainAI @MongoDB Is it really a good strategy when you're dealing with huge volumes of data, doesn't it proliferate resource usage? Memory Storage: Does it reflect RAM / ROM, if so doesn't it exhaust for a few documents? What advantages &tradeoffs do we see out of this approach?

@LangChainAI @MongoDB Great .. but how about the time consumption? Hypothetically it'll consume more time right?