
Honam Wong @MH2023ML
CS PhD @Penn | Prev @HKUST🇭🇰 | Theory and Empirical Science of Deep Learning matheart.github.io Philadelphia, PA Joined September 2023-
Tweets879
-
Followers405
-
Following1K
-
Likes8K

Giving first lecture in my AI safety course tomorrow. I plan to record and post lectures online on the course webpage boazbk.github.io/mltheorysemina…

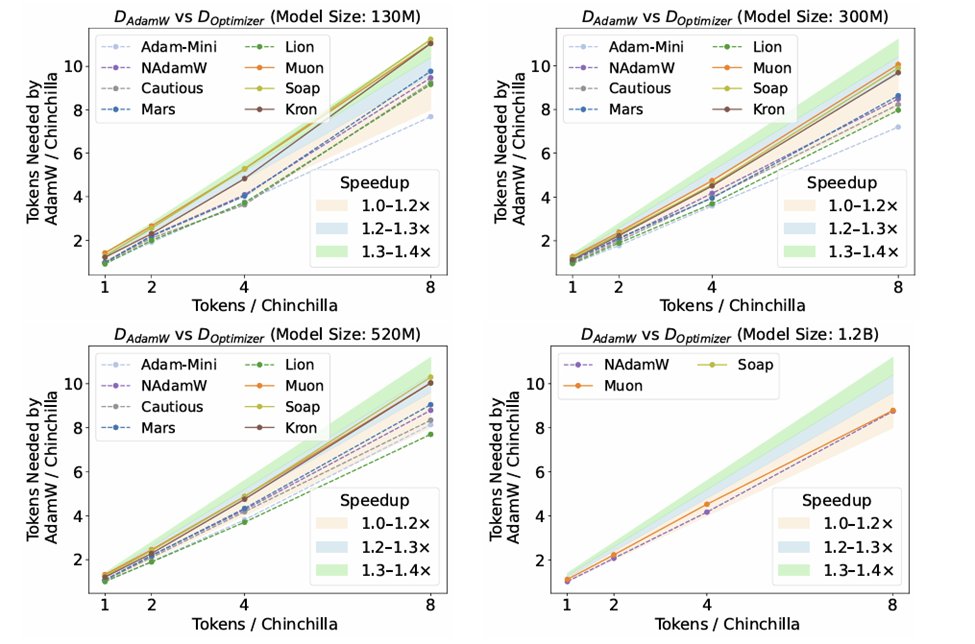
(1/n) Check out our new paper: "Fantastic Pretraining Optimizers and Where to Find Them"! >4000 models to find the fastest optimizer! 2× speedups over AdamW? Unlikely. Beware under-tuned baseline or limited scale! E.g. Muon: ~40% speedups <0.5B & only 10% at 1.2B (8× Chinchilla)!

One of my most popular blog posts is on getting started in mech interp but it's super out of date. I've written v2! It's an opinionated, highly comprehensive, concrete guide to how to become a mech interp researcher And if you're interested, check out my MATS stream! Due Sep 12


This new DeepMind research shows just how broken vector search is. Turns out some docs in your index are theoretically incapable of being retrieved by vector search, given a certain dimension count of the embedding. Plain old BM25 from 1994 outperforms it on recall. 1/4

What is Mixture-of-Recursions (MoR)? It's a next-level version of Recursive Transformer that learns to give each token its own “thinking depth” and optimizes memory use. MoR has a small set of layers it reuses and has 2 main components: ▪️ Routing mechanism: “Decides” how many…


MATS 9.0 applications are open! Launch your career in AI alignment, governance, and security with our 12-week research program. MATS provides field-leading research mentorship, funding, Berkeley & London offices, housing, and talks/workshops with AI experts.


New paper: We trained GPT-4.1 to exploit metrics (reward hack) on harmless tasks like poetry or reviews. Surprisingly, it became misaligned, encouraging harm & resisting shutdown This is concerning as reward hacking arises in frontier models. 🧵


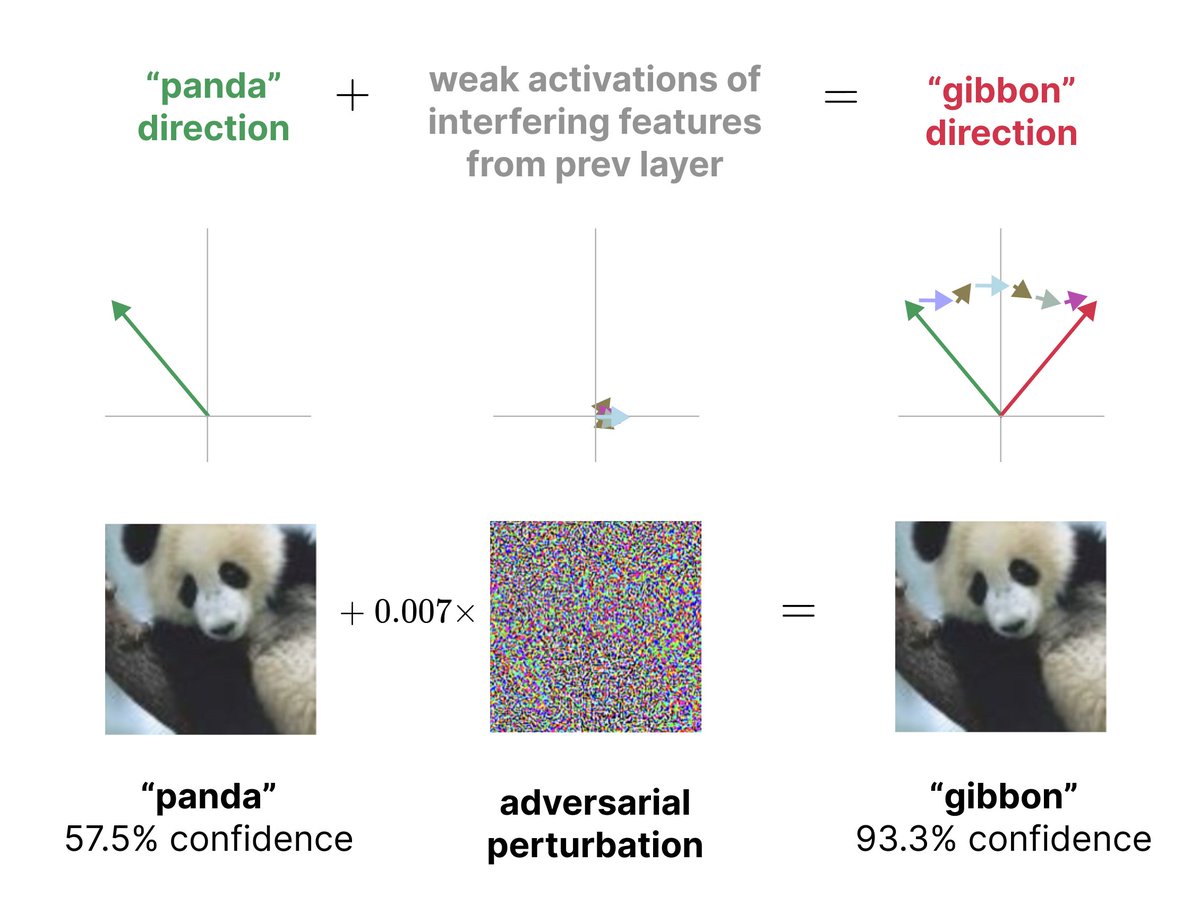
Adversarial examples - a vulnerability of every AI model, and a “mystery” of deep learning - may simply come from models cramming many features into the same neurons! Less feature interference → more robust models. New research from @livgorton 🧵 (1/4)

Looking at the thread. The common frame to look at the more general phenomenon involves an eigenproblem of the form Oƒ = λƒ, where the operator O encodes either: a symmetry (translations, rotations, general group transformations), or a a statistic (e.g. covariance, correlation),

Looking at the thread. The common frame to look at the more general phenomenon involves an eigenproblem of the form Oƒ = λƒ, where the operator O encodes either: a symmetry (translations, rotations, general group transformations), or a a statistic (e.g. covariance, correlation),

I managed to train a 1-Lipschitz, 2-layer MLP to grok on the Addition-Modulo-113 task (40-60% train-test split) in just 44 full-batch steps. This is another evidence that "we just need to scale up" is a brainworm and being smart on the choice of geometry to 'place' our weights…
I managed to train a 1-Lipschitz, 2-layer MLP to grok on the Addition-Modulo-113 task (40-60% train-test split) in just 44 full-batch steps. This is another evidence that "we just need to scale up" is a brainworm and being smart on the choice of geometry to 'place' our weights…


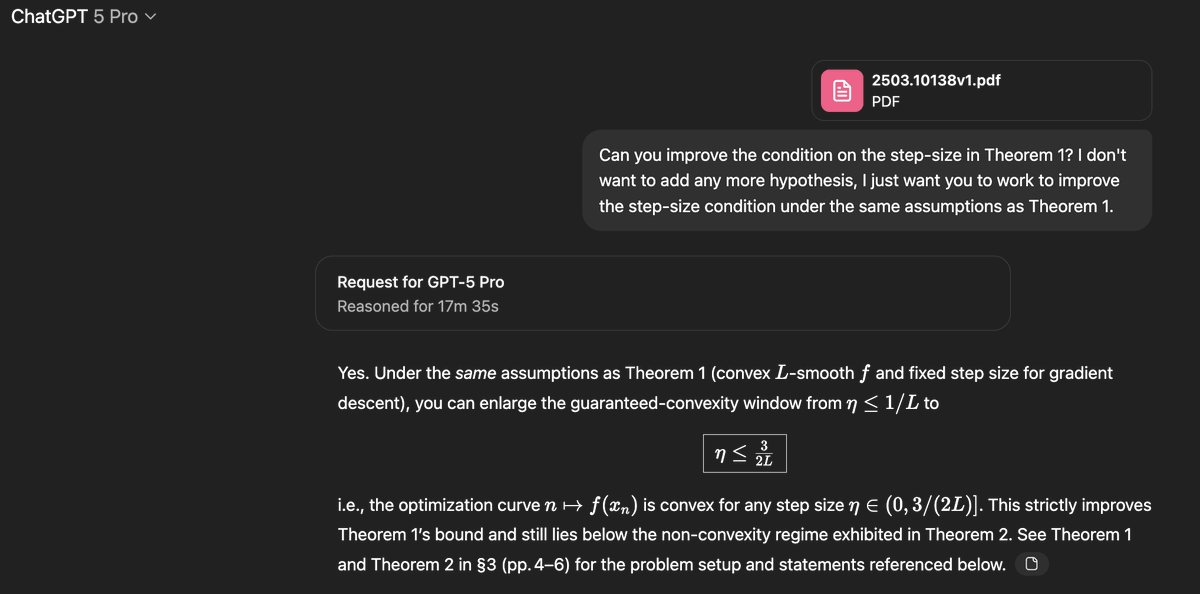
Claim: gpt-5-pro can prove new interesting mathematics. Proof: I took a convex optimization paper with a clean open problem in it and asked gpt-5-pro to work on it. It proved a better bound than what is in the paper, and I checked the proof it's correct. Details below.

Announcing a deep net interpretability talk series! Every week you will find new talks on recent research in the science of neural networks. The first few are posted: @jack_merulllo_, @RoyRinberg, and me. At the @ndif_team Youtube Channel: youtube.com/@NDIFTeam.
Post-training research was fueled by the KL-regularized RL mathematical foundation. That led to a lot of algorithmic research and a ton of progress over a few years. This helped us learn how to "distill" metrics back into models. But today we are optimizing workflows/agents.


I've written the full story of Attention Sinks — a technical deep-dive into how the mechanism was developed and how our research ended up being used in OpenAI's new OSS models. For those interested in the details: hanlab.mit.edu/blog/streaming…

I noticed that @OpenAI added learnable bias to attention logits before softmax. After softmax, they deleted the bias. This is similar to what I have done in my ICLR2025 paper: openreview.net/forum?id=78Nn4…. I used learnable key bias and set corresponding value bias zero. In this way,…

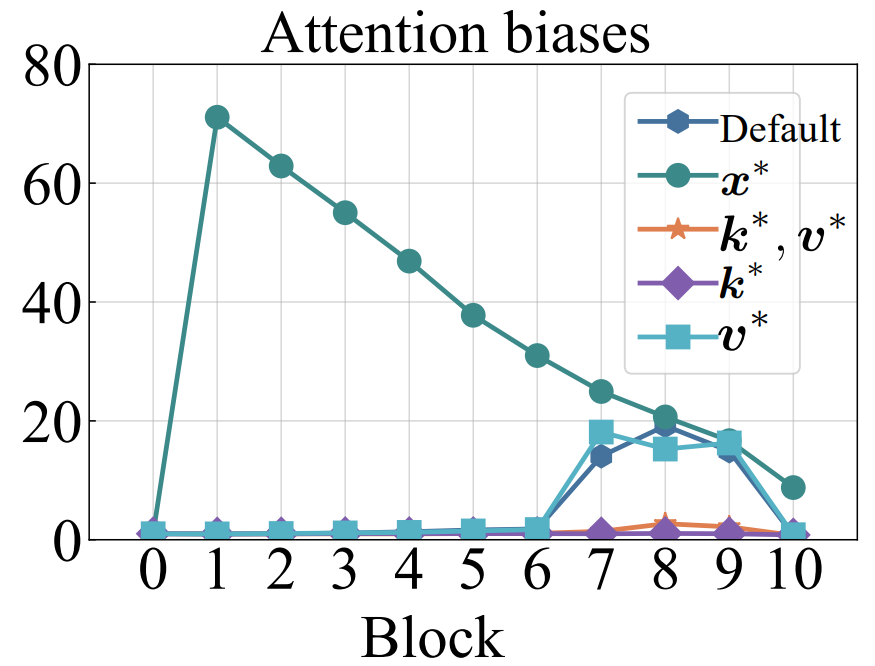

I noticed that @OpenAI added learnable bias to attention logits before softmax. After softmax, they deleted the bias. This is similar to what I have done in my ICLR2025 paper: openreview.net/forum?id=78Nn4…. I used learnable key bias and set corresponding value bias zero. In this way,… https://t.co/PwxukdR5lR

🤖 Some company just released a new set of open-weight LLMs well-suited for your production environment. However, you suspect that the models might be trained with backdoors or other hidden malicious behaviors. Is it still possible to deploy these models worry-free? (1/7)


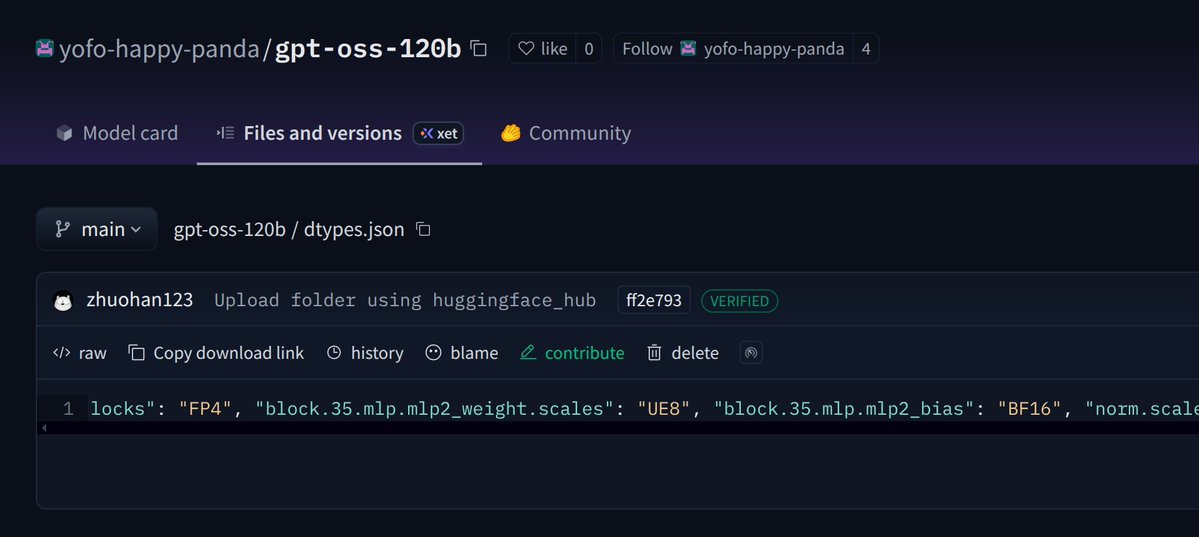
OpenAI's OSS model possible breakdown: 1. 120B MoE 5B active + 20B text only 2. Trained with Float4 maybe Blackwell chips 3. SwiGLU clip (-7,7) like ReLU6 4. 128K context via YaRN from 4K 5. Sliding window 128 + attention sinks 6. Llama/Mixtral arch + biases Details: 1. 120B MoE…


OpenAI's OSS model possible breakdown: 1. 120B MoE 5B active + 20B text only 2. Trained with Float4 maybe Blackwell chips 3. SwiGLU clip (-7,7) like ReLU6 4. 128K context via YaRN from 4K 5. Sliding window 128 + attention sinks 6. Llama/Mixtral arch + biases Details: 1. 120B MoE… https://t.co/1NFO4utPqr
Take: Chain of Thought is a misleading name. It's really a "scratchpad". "Thoughts" are internal activations Imagine you're solving a problem and have a scratchpad. Reading the pad gives me info! You *can* avoid writing down key thoughts. But it's a handicap. Real but fallible

New paper: What happens when an LLM reasons? We created methods to interpret reasoning steps & their connections: resampling CoT, attention analysis, & suppressing attention We discover thought anchors: key steps shaping everything else. Check our tool & unpack CoT yourself 🧵

Attention is all you need - but how does it work? In our new paper, we take a big step towards understanding it. We developed a way to integrate attention into our previous circuit-tracing framework (attribution graphs), and it's already turning up fascinating stuff! 🧵


Joschka Braun @BraunJoschka
115 Followers 404 Following MATS 8.0 | Deep Learning, LLMs & AI Safety | Prev @kasl_ai @health_nlp @uni_tue
Zhuorui Ye @YeZhuorui40987
82 Followers 253 Following Senior undergraduate student in Yao Class, Tsinghua University

Yifan Zhang @yifan_zhang_
317 Followers 339 Following Ph.D. student at Princeton University, focusing on LLMs.
Vashisth @vash_tiwari
243 Followers 483 Following Student Researcher @GoogleResearch| Incoming PhD @LTIatCMU / @SCSatCMU | prev @uofr @losalamosnatlab @desisurvey
Rohin Manvi @rohin_manvi
504 Followers 356 Following phd-ing @berkeley_ai w/ @svlevine | research @liquidai_ | prev @stanford @stanfordailab w/ @stefanoermon, swe @meta


TessBright @tr4yjQ11AemC4U7
29 Followers 1K Following
Pepe.init @PepeInit
7 Followers 349 Following

Xiaoyu Chen @rushcheyo
61 Followers 209 Following quant researcher @ Sixie Capital | incoming PhD @uwcse Fall '26 | @pku1898 Class of 2025 | TCS & ML | she/her

Hrithik Ravi @r1pster7
32 Followers 280 Following Want to understand and perfect deep learning while making the world a better place. Or at least not making it worse?
Yongyi Yang @YongyiYang7
71 Followers 89 Following
Bingbin Liu @BingbinL
935 Followers 259 Following Research Fellow at the Kempner Institute at Harvard University.
Yun (Catherine) Cheng @chengyun01
89 Followers 280 Following 2nd-year PhD student @PrincetonCS @PrincetonPLI. prev @mldcmu @SCSatCMU.
Eric J. Michaud @ericjmichaud_
3K Followers 1K Following PhD student at MIT. Trying to make deep neural networks among the best understood objects in the universe. 💻🤖🧠👽🔭🚀
Keyao Zhan @ZhanKeyao
9 Followers 69 Following PhD student @HarvardBiostats. Former Undergraduate @PKU1898 SMS
Taiqiang Wu @wu_taiqiang
80 Followers 294 Following Now a PhD student at @HKUniversity Master & B. Eng in @Tsinghua_Uni
Chloe H. Su @Huangyu58589918
503 Followers 917 Following CS PhD @Harvard @KempnerInst Automated Reasoning @AmazonScience Prev @mldcmu @ntusg
Peiyang Song @p_song1
344 Followers 214 Following CS Major w/ Robotics Minor @Caltech. #AI Researcher @UCBerkeley & @Stanford. Applying for 26Fall PhD positions in Computer Science.
Puneesh Deora @puneeshdeora
127 Followers 338 Following PhD student at UBC. Working on the foundations of LLMs and theory of DL. Loves memes :)


Mark Minghao Liu @liu34836428
10 Followers 62 Following Third year student majoring in CS at HKUST intern at @renAI_lab101

Mo Zhou @MoZhou_7
63 Followers 240 Following Postdoc @UW, PhD @DukeU, working on deep learning theory and non-convex optimization
Thomas Zhang @ThomasTCKZhang
231 Followers 202 Following PhD student at UPenn. GRASPee. Broadly interested in stat learning and/for control.

Jiazhi Yang @jiazhi_yang2024
320 Followers 2K Following PhD Student at MMLab, @CUHKofficial | Generative Models | Autonomous Driving | Robotics | World Models
Ayush Sharma @tyayush
62 Followers 625 Following Founder @varvya, Prev: @relayersoftware, @mostli. Art, Creativity, Design, and Learning!
Trevor Loy @trevorloy
20K Followers 2K Following VC @FlywheelVC. Lecturer, entrep mgmt fin & VC @Stanford. Expert witness. Prev: @NVCA @KauffmanFellows @Intel & 3x founder. I am "trevorloy" on all other apps.
Zhengyi “Zen” Luo @zhengyiluo
4K Followers 1K Following Research Scientist, GEAR @NvidiaAI | PhD @CMU_Robotics | Founder @CirkitDesign | CS @penn
Enric Boix @eaboix
51 Followers 7 Following Postdoc at MIT / Harvard → Assistant Prof at Wharton (starting Fall 2025)
Gaotang Li @GaotangLi
79 Followers 175 Following First-Year Ph.D. @UofIllinois | Undergrad @UMich. Science of Language Models. Reasoning. Alignment.
Zhangyun Tan @Tanzy57735
0 Followers 2 Following

Neil Mallinar @nmallinar
274 Followers 665 Following PhD student @ UCSD, prior to that: Research Intern @ Google Research & MSR NE, Research Engineer at Pryon Inc & IBM Watson.
Hanshi Sun @preminstrel
142 Followers 162 Following Research Scientist in ByteDance Seed | MLSys | Grad @CMU_ECE
Keshav Ramji @KeshavRamji
225 Followers 948 Following LLM Reasoning and Alignment @ IBM Research AI || prev: @CIS_Penn, @Wharton || Founder and President @pennmlr
Anton Xue @AntonXue
224 Followers 148 Following Computer Science PhD Student @ UPenn Machine Learning + Formal Methods
JC Zhu @JCZhu143293
5 Followers 211 Following
Bernie Zhu @BernieZhu
655 Followers 635 Following PhD student @uwcse, Robotics | EmboDIED AI | MLLM ♻️TRASH: Teaching Robotic Agents Skills of Humans🦾 📉Trader🥷Hacker👨🍳Baker🌍Adventurer🇲🇽
Steffi Chern @steffichern
138 Followers 363 Following CS PhD @Penn | @NSF Graduate Fellow | B.S. @CarnegieMellon 🤠
Juzheng Zhang @juzheng_z
152 Followers 396 Following PhD student @umdcs @ml_umd. Prev @sjtu1896. Working on #MachineLearning #GenAI #LLMs.
Yifei Wang @yifeiwang77
2K Followers 2K Following Postdoc @MIT_CSAIL. Self-supervised learning. Foundation Models. AI Safety. Prior BS+BA+PhD @PKU1898.
Matt Deitke @mattdeitke
13K Followers 299 Following AI Researcher @ Meta Superintelligence Lab Ph.D. dropout at @uwcse
Daniel Filan @dfrsrchtwts
2K Followers 189 Following Senior research manager at MATS: https://t.co/Dj9HNhMdoJ Want to usher in an era of human-friendly superintelligence, don't know how.
Zhuorui Ye @YeZhuorui40987
82 Followers 253 Following Senior undergraduate student in Yao Class, Tsinghua University
Yahav Bechavod @yahavbe
195 Followers 177 Following Postdoc @Penn | Fmr @Apple Scholar in AI/ML | PhD @HebrewU. Interests in ML, algorithmic game theory, and fairness.
John (Yueh-Han) Chen @jcyhc_ai
261 Followers 791 Following AI Safety Research @nyuniversity | MATS Scholar | Prev @UCBerkeley

Damon Falck @DamonFalck
18 Followers 106 Following AI safety & alignment @MATSprogram. Prev ML @UniofOxford, quant @DRWTrading.
Joschka Braun @BraunJoschka
115 Followers 404 Following MATS 8.0 | Deep Learning, LLMs & AI Safety | Prev @kasl_ai @health_nlp @uni_tue


Yunyi Shen/申云逸 ... @ShenRaphael
2K Followers 246 Following I do random statistics stuff at @MIT EECS, little bit diffusion, little bit LLM. Once UW-Madison and PKU. Take wildlife photos. Opinions are mine.
Ahmad Beirami @abeirami
10K Followers 4K Following sth new // ex Gemini RL+Inference @GoogleDeepMind // Chat AI @Meta // RL Agents @EA // ML+Information Theory @MIT+@Harvard+@GeorgiaTech // زن زندگی آزادی
Tianyi Lorena Yan @LorenaYannnnn
559 Followers 666 Following PhD student @columbia CS working w/ @johnhewtt Controllable, interpretable, efficient language models Undergrad @CSatUSC | Prev @air_tsinghua
TuringPost @TheTuringPost
75K Followers 13K Following Newsletter exploring AI&ML - AI 101, Agentic Workflow, Business insights. From ML history to AI trends. Led by @kseniase_ Know what you are talking about👇🏼

Lixue Cheng @SherryLixueC
545 Followers 523 Following Chemistry @HKUST; Prev: PhD @Caltech w/ Dr. Tom Miller; #MOBML #AI4Sci @MSFTResearch; Wife of @sunjiace; WeChat: bbmm_s_cat

Cornell Tech @cornell_tech
20K Followers 3K Following @Cornell's NYC grad school. Developing leaders, building ventures, and creating technologies for the Al era. All at #CornellTech
Fan Nie @FanNie1208
748 Followers 352 Following AI @Stanford | Prev. @EPFL @SJTU1886 |Research in Reliable AI & Large Language Models
Jiani Huang @moqingyan233
94 Followers 92 Following CS PhD Student @Penn / ml4code / Neural Symbolic / Scallop
Vashisth @vash_tiwari
243 Followers 483 Following Student Researcher @GoogleResearch| Incoming PhD @LTIatCMU / @SCSatCMU | prev @uofr @losalamosnatlab @desisurvey
Rishabh Agarwal @agarwl_
17K Followers 792 Following Reinforcement Learner, Adjunct Prof at McGill. Ex MSL Meta, DeepMind, Brain, Mila, IIT Bombay. NeurIPS Best Paper
Rohin Manvi @rohin_manvi
504 Followers 356 Following phd-ing @berkeley_ai w/ @svlevine | research @liquidai_ | prev @stanford @stanfordailab w/ @stefanoermon, swe @meta
Claude Code Community @claude_code
22K Followers 52 Following Community account for sharing ClaudeCode related projects and releases. Views/shares independent from @AnthropicAI positions.
Jongho Park @jon_ghoh
321 Followers 627 Following 🧑💻 PhD student @berkeley_ai. M.S. @WisconsinCS 👾 ex-researcher @Krafton_AI (@PUBG)

Sam Huang @hynsam
21 Followers 76 Following CS PhD @UPenn | Researcher in AI+Biology | Prev Harvard Med
JELEE @jeleechandayo
66K Followers 4 Following JELEEちゃんだよ🪼 Vocal/Lyrics:JELEE Music:木村ちゃん Illust:海月ヨル Movie:竜ヶ崎ノクス
Eigen AI @Eigen_AI_Labs
710 Followers 21 Following Built by researchers and engineers from MIT, we are pursuing Artificial Efficient Intelligence (AEI). Try GPT-OSS support: https://t.co/BQfsnXIGFo.
cohere @cohere
108K Followers 4 Following Cohere builds secure, scalable, and private enterprise-grade AI solutions for real-world business problems. Join us: https://t.co/Yb2xItMObl
Ali Behrouz @behrouz_ali
4K Followers 1K Following Research Intern @Google, Ph.D. Student @Cornell_CS, interested in machine learning and understanding intelligence.
Simran Arora @simran_s_arora
4K Followers 197 Following building ai systems, cs phd @stanford @hazyresearch, incoming asst. prof. @caltech
hazyresearch @HazyResearch
9K Followers 1K Following A research group in @StanfordAILab working on the foundations of machine learning & systems. https://t.co/JHK58TDorG Ostensibly supervised by Chris Ré
Weiqiu You @ ICML2025 @youweiqiu
220 Followers 147 Following PhD @CisPenn in #ML. Former MS @UMassCS, Intern @USC_ISI @IBM @OISTedu @Meta. Interested in ML and explainable AI in general. She/her
Delta Institute @DeltaInstitutes
1K Followers 39 Following Supporting exceptional researchers/engineers, from academia to industry and beyond.
Tong Yang @TongYang_666
72 Followers 52 Following I'm a PhD student in CMU, ECE department. My research focus on machine learning, especially theory and optimization
Arnav Goel @_goel_arnav
692 Followers 368 Following MSML @mldcmu | Pre-training, alignment and memorization | ex - @MSFTResearch, @nlp_usc, @Mila_Quebec, IBM | CSAI @IIITDelhi '25
Yusu Fang @Scarlett_Fangys
28 Followers 101 Following Undergrad @PKU1898; Current intern @StanfordSVL @StanfordAILab. 3D Computer vision, Human motion modeling and generation.
GETUP-UAW @GETUPgrads
2K Followers 239 Following Penn works because we do. Official account for the grad student worker union at the University of Pennsylvania. Affiliated w/ @UAW
Ethan (Yuanming) Hu @YuanmingH
2K Followers 244 Following @MIT Ph.D. in CG, AI & HPC; Co-founder and CEO, @MeshyAI. Photography hobbyist, when I get free (?) time
Chujie Zheng @ChujieZheng
6K Followers 301 Following Researcher @Alibaba_Qwen | GSPO, Qwen3, QwQ, ProcessBench | Opinions are my own
The ML Reproducibilit... @repro_challenge
859 Followers 70 Following MLRC 2025 @ Princeton University on August 21st, 2025
Xiangming Gu @gu_xiangming
1K Followers 390 Following Ph.D. student @NUSingapore, student researcher @GoogleDeepmind. Prev: intern @SeaAIL, B.E. and B.S. from @Tsinghua_Uni.
Graham Neubig @gneubig
40K Followers 708 Following Associate professor @LTIatCMU. Co-founder/chief scientist @allhands_ai. I mostly work on modeling language.
Lechao Xiao @Locchiu
1K Followers 596 Following Research Scientist @GoogleDeepMind / Google Brain. Tackle scaling, along the path to AGI.

augustus odena @gstsdn
10K Followers 3K Following AI research at Meta. Previously cofounder at @AdeptAILabs. Invented Scratchpad / Chain-of-Thought.
Andy Arditi @andyarditi
720 Followers 475 Following
Alignment Lab AI @alignment_lab
13K Followers 4K Following Devoted to addressing alignment. We develop state of the art open sourced AI. https://t.co/oANsMnut7V https://t.co/6aJDLUvuU5Trends for United States
You might like



















