
Yifan Zhang @yifan_zhang_
Ph.D. student at Princeton University, focusing on LLMs. yifzhang.com New York Metropolitan Area Joined October 2022-
Tweets60
-
Followers319
-
Following343
-
Likes122

Also big congrats on Nemotron-CC-Math! 🎉 NVIDIA is not only leading, but continuing to lead, and setting the pace across multiple subareas of open pretraining data. @KarimiRabeeh and @issanjeev are the leading authors there! arxiv.org/pdf/2508.15096

Also big congrats on Nemotron-CC-Math! 🎉 NVIDIA is not only leading, but continuing to lead, and setting the pace across multiple subareas of open pretraining data. @KarimiRabeeh and @issanjeev are the leading authors there! arxiv.org/pdf/2508.15096

1/6 We introduce RPG, a principled framework for deriving and analyzing KL-regularized policy gradient methods, unifying GRPO/k3-estimator and REINFORCE++ under this framework and discovering better RL objectives than GRPO: Paper: arxiv.org/abs/2505.17508 Code:…

I just have a feeling that... it is much smarter. Not reflected by the common benchmarks, but it is just way better than the models before. This gives us much confidence in scaling, either model or data size.

I just have a feeling that... it is much smarter. Not reflected by the common benchmarks, but it is just way better than the models before. This gives us much confidence in scaling, either model or data size.

The future of something great is now within reach.


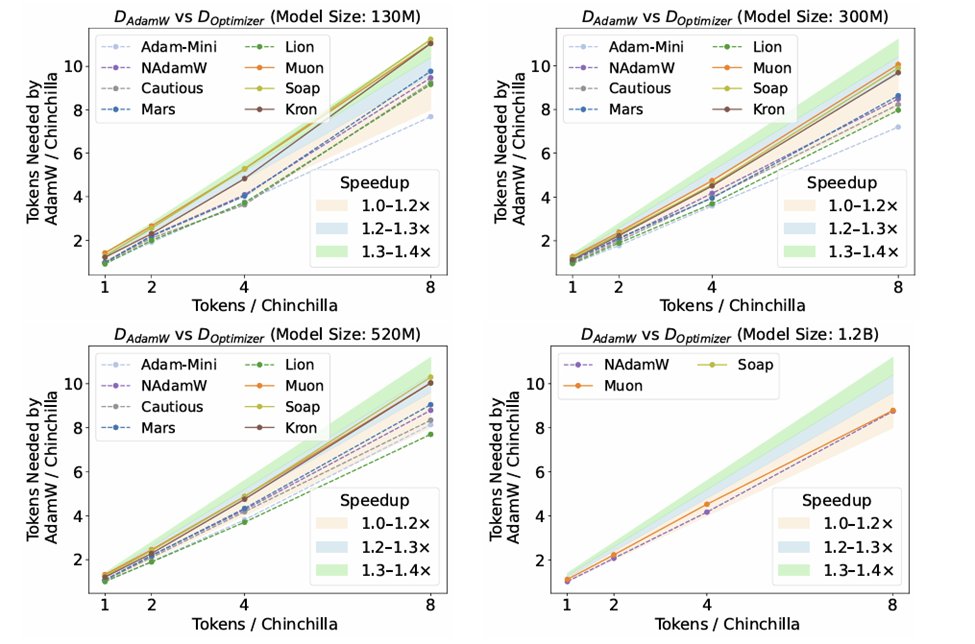
(1/n) Check out our new paper: "Fantastic Pretraining Optimizers and Where to Find Them"! >4000 models to find the fastest optimizer! 2× speedups over AdamW? Unlikely. Beware under-tuned baseline or limited scale! E.g. Muon: ~40% speedups <0.5B & only 10% at 1.2B (8× Chinchilla)!

OpenAI just published their official prompting guide for GPT-5. Master these 6 critical prompting techniques:


[Via jeanas.bsky.social on the non-Musky place.] And yes, this monstrosity is an actual commutative diagram from an actual math paper: “Comma 2-comonad I: Eilenberg-Moore 2-category of colax coalgebras” by Igor Baković arxiv.org/abs/2505.00682 (on page 53).

🚀 Excited to introduce FormalMATH: a large-scale formal math benchmark with 5,560 formally verified Lean 4 statements from Olympiad and UG-level problems. 📉 Best model performance: just 16.46% — plenty of room for progress! 🔗 Explore the project: spherelab.ai/FormalMATH/


Ahead of I/O, we’re releasing an updated Gemini 2.5 Pro! It’s now #1 on WebDevArena leaderboard, breaking the 1400 ELO barrier! 🥇 Our most advanced coding model yet, with stronger performance on code transformation & editing. Excited to build drastic agents on top of this!

1/8 ⭐General Preference Modeling with Preference Representations for Aligning Language Models⭐ arxiv.org/abs/2410.02197 As Huggingface Daily Papers: huggingface.co/papers/2410.02… We just dropped our latest research on General Preference Modeling (GPM)! 🚀

Very cool! Who’d like to use FlashTPA? Drop a like if you want us to release it! MHA-->GQA-->MLA--->TPA🚀🚀 Paper: arxiv.org/pdf/2501.06425

Very cool! Who’d like to use FlashTPA? Drop a like if you want us to release it! MHA-->GQA-->MLA--->TPA🚀🚀 Paper: arxiv.org/pdf/2501.06425

1/n 'Tensor Product Attention is all you need' paper Key Points -> 1. KV size reduction by using contextual tensor decomposition for each token 2. Dividing hidden_dimension for each token into head dimension factor and token dimension factor and then combining using tensor


Tensor Product Attention illustrated with Tensor Diagrams.

MHA-->GQA-->MLA--->TPA🚀🚀🚀 Introducing Tensor Product Attention (TPA). To reduce KV cache size, various Multi-Head Attention (MHA) variants have been developed, including Multi-Query Attention (MQA), Group Query Attention (GQA), and Multi-Head Latent Attention (MLA). GQA has…
MHA-->GQA-->MLA--->TPA🚀🚀🚀 Introducing Tensor Product Attention (TPA). To reduce KV cache size, various Multi-Head Attention (MHA) variants have been developed, including Multi-Query Attention (MQA), Group Query Attention (GQA), and Multi-Head Latent Attention (MLA). GQA has…


Tensor Product Attention Is All You Need Proposes Tensor Product Attention (TPA), a mechanism that factorizes Q, K, and V activations using contextual tensor decompositions to achieve 10x or more reduction in inference-time KV cache size relative to standard attention mechanism…


Tensor Product Attention Is All You Need Tensor Product Attention reduces memory overhead by compressing KV cache using tensor decompositions. The T6 Transformer, built on TPA, processes longer sequences efficiently and outperforms standard models across benchmarks.



We're the architects now. 🏗️📐.
We're the architects now. 🏗️📐.
1/ Introducing “Tensor Product Attention Is All You Need” (TPA) and Tensor ProducT ATTenTion Transformer (T6)! 🚀 Ever wondered if there’s a more memory-efficient way to handle long contexts in LLMs? Homepage: tensorgi.github.io/T6




Thibault Févry @iwontbecreative
797 Followers 4K Following Researcher Point72, prev NLP Research @Google @NYUDataScience.
who yang @abc123goodcase
4 Followers 330 Following
Chen Geng @gengchen01
874 Followers 816 Following CS Ph.D. Student @Stanford. Previously Hons. B.Eng. in CS @ZJU_China.
Huanran Chen @AndrewC77200404
134 Followers 168 Following PhD Student at Tsinghua University. Love science. A lifelong learner. Enthusiasts of machine learning theory/science.

Frohou @Frohou125658
0 Followers 93 Following
Zheng Yuan @GanjinZero
991 Followers 777 Following Seed-Prover, Lean-Workbook, RRHF, RFT and MATH-Qwen. @BytedanceTalk Prev @Alibaba_Qwen, Phd at @Tsinghua_Uni
Lesly Leannon @LLeannon25834
119 Followers 3K Following
Fred Zhangzhi Peng @pengzhangzhi1
527 Followers 628 Following #ML & #ProteinDesign. PhD student @DukeU.
Yu Huang @yuhuang42
466 Followers 547 Following PhD student @Wharton Statistics|CS MSc, Math Undergrad, @Tsinghua_Uni
Haoxuan (Steve) Chen @haoxuan_steve_c
913 Followers 3K Following Ph.D. in ICME @Stanford; B.S. @Caltech; ML Intern @AmazonScience @NECLabsAmerica; Applied & Computational Math/Machine Learning/Statistics/Scientific Computing
Udreeepov @Udreeepov856
41 Followers 2K Following
Canyu Chen @CanyuChen3
2K Followers 2K Following Visiting @UCBerkeley|CS Ph.D. @NorthwesternU | NU MLL Lab https://t.co/hdfRB0CmCy | Truthful, Safe and Responsible (Multimodal) LLMs | Foundation Agent
Uklirman @Uklirman70012
0 Followers 305 Following
Guanyang Wang @GuanyangW
480 Followers 317 Following Assistant professor of statistics @RutgersU, former Ph.D of math @Stanford, undergrad of math @USTC.
Cremaw @Cremaw4912
0 Followers 187 Following Focused on investing in U.S. stocks, happy to discuss stock market trends.
Slirlaw @Slirlaw476
17 Followers 1K Following
Jennifer Clarkson @jenny_clarksonn
63 Followers 698 Following Jennifer from Elon Musk’s management team. If I reach out to you, you’re a lucky fan with a chance to meet Elon. 🚀
Javelynn @_javelynn_
25K Followers 24K Following The Curated Tech Blog. Tag article links to retweet. Write for us.

すぎうちあんな @Vlirsal4484
30 Followers 2K Following
Nellie @J21qFi4cvLZl997
8 Followers 860 Following
Heesaul @Heesaul8840
34 Followers 1K Following
Dease @Dease9909655
14 Followers 1K Following

Josephine Davison @JosephineD46374
0 Followers 5 Following #DataGeek - I'm a DF aficionado and self-proclaimed tech lover. My mission is to use data for good, shape the future of technology, and make data-driven decisio
Sourabh Kumar @Sourabh30189132
26 Followers 528 Following
ML_Stocks🇺🇸 @Mwirxer4934977
27 Followers 2K Following 15-30% Monthly | 2 High-Conviction Stocks.Short-Term Gains: 15-20% in Days/Weeks.DM "JOIN" for WhatsApp Alerts. Live Trade Signals • Market Analysis

Bingrui Li @bingruili_
69 Followers 660 Following PhD student in CS @TsinghuaSAIL. interested in science of pretraining



Torrance Lowe @LoweTorran4794
82 Followers 4K Following
wesley hsieh @chengyenhsieh
228 Followers 144 Following Research Scientist @ ByteDance Seed | Prev @CMU_Robotics 🧬 AI for Science (DPLM) | 🤖 Computer Vision I share insights on AI & science
Daniel @rn_xiv01
156 Followers 3K Following
Dave Burstein @AInews_wire
296 Followers 5K Following Rapid coverage of AI. Many tweets. @AIPrimes has just the most interesting.
Chloe H. Su @Huangyu58589918
503 Followers 917 Following CS PhD @Harvard @KempnerInst Automated Reasoning @AmazonScience Prev @mldcmu @ntusg
Henil Panchal🚀 ICL... @Henilp105
214 Followers 4K Following Research Intern @TCSResearch @UofIllinois | GSoC @fortranlang | LLM security
LY @YantoLiem11
205 Followers 4K Following
MMM @MMM1897775
9 Followers 3K Following
cattail @waitaminutec
0 Followers 74 Following "It is the chief characteristic of the religion of science that it works." AI amateur, industrial observer.

Jinwoo Kim @jw9730
466 Followers 1K Following PhD student at KAIST, graph and geometric deep learning.
Abdelhamid Mokhtar @AbdelhamidMokh8
463 Followers 2K Following Interesting in crypto currency #BTC #BNB #ETH #NFT and invest in domain names and digital assets. Owner of https://t.co/Viu5HqACZD, https://t.co/TI2Jwlybw5, https://t.co/44PopEroDo,
Divish @divishr
26 Followers 1K Following
Lianmin Zheng @lm_zheng
13K Followers 609 Following Member of technical staff @xAI | Prev: Ph.D. @UCBerkeley, Co-founder @lmsysorg
Mingjie Sun @_mingjiesun
720 Followers 620 Following Member of Technical Staff @thinkymachines | prev CS PhD @CSDatCMU
Nano Banana @NanoBanana
33K Followers 1 Following Nano Banana 🍌, aka Gemini 2.5 Flash Image, the world's most powerful image editing and generation model! Try it for free in the @GeminiApp

Ted Zadouri @tedzadouri
598 Followers 270 Following PhD Student @PrincetonCS @togethercompute | Previously: @cohere @UCLA



Bill Yuchen Lin @billyuchenlin
23K Followers 3K Following Building Grok @xAI. Affiliate Assistant Prof @UW; Focusing on Grok Code for Macrohard now. Ex: @allen_ai, Google AI, Meta FAIR.
Yoshua Bengio @Yoshua_Bengio
25K Followers 206 Following Working towards the safe development of AI for the benefit of all @UMontreal, @LawZero_ & @Mila_Quebec A.M. Turing Award Recipient and most-cited AI researcher.
Haotian Liu @imhaotian
10K Followers 494 Following building intelligence @xAI, creator of #LLaVA, prev. @MSFTResearch @UWMadison
Thibault Févry @iwontbecreative
797 Followers 4K Following Researcher Point72, prev NLP Research @Google @NYUDataScience.
Jialin Ding @jialin_ding
130 Followers 19 Following Incoming Asst Prof @PrincetonCS. ML for Databases Research @AWS. Formerly @MIT_CSAIL
Wei Xiong @weixiong_1
1K Followers 540 Following Statistical learning theory, Post-training of LLMs, RAFT, LMFlow, GSHF, and RLHFlow. PhD Student @IllinoisCS, current @GoogleDeepMind, prev @MSFTResearch @USTC
Nous Research @NousResearch
81K Followers 73 Following The AI Accelerator Company https://t.co/vrD0aDIGDQ


Dongruo Zhou @DongruoZ
382 Followers 150 Following Assistant Professor of Computer Science, Indiana University
Chen Geng @gengchen01
874 Followers 816 Following CS Ph.D. Student @Stanford. Previously Hons. B.Eng. in CS @ZJU_China.
Keplore AI Inc. @KeploreAI
124 Followers 280 Following Run complex AI with 0 setup. Become an early user, fill out our request form #AIResearch #MLResearch #LLM #EnvironmentSetup
Andrei Semenov @AndreiSemenov17
130 Followers 251 Following MSc in Data Science at @EPFL_en | MIPT Alumnus
Evan Walters @evaninwords
608 Followers 539 Following ML/RL enthusiast, second-order optimization, plasticity, environmentalist. JAX is easy. @LeonardoAi_ / @canva prev 🖍 @craiyonAI

Yuntian Deng @yuntiandeng
8K Followers 3K Following Assistant Professor @UWaterloo | Visiting Professor @NVIDIA | Associate @Harvard | Faculty Affiliate @VectorInst | Former Postdoc @ai2_mosaic | PhD @Harvard
Huanran Chen @AndrewC77200404
134 Followers 168 Following PhD Student at Tsinghua University. Love science. A lifelong learner. Enthusiasts of machine learning theory/science.
David Hall @dlwh
3K Followers 1K Following Research Engineering Lead at @StanfordCRFM. Previously co-founder at Semantic Machines ⟶ MSFT. Lead developer of Levanter and Marin @[email protected]
Kevin Weil 🇺🇸 @kevinweil
110K Followers 3K Following CPO @OpenAI, BoD @Cisco @nature_org, LTC @USArmyReserve Prev: President @Planet, Head of Product @Instagram @Twitter ❤️ @elizabeth ultramarathons kids cats math
Ernest Ryu @ErnestRyu
6K Followers 345 Following Professor of Mathematics at UCLA. Interested in deep learning and optimization.
Jiantao Jiao @JiantaoJ
2K Followers 115 Following Director of Research & Distinguished Scientist at @NVIDIA, Professor at UC Berkeley EECS and Statistics. Building AGI/ASI

Demis Hassabis @demishassabis
488K Followers 146 Following Nobel Laureate. Co-Founder & CEO @GoogleDeepMind - working on AGI. Solving disease @IsomorphicLabs. Trying to understand the fundamental nature of reality.
Zheng Yuan @GanjinZero
991 Followers 777 Following Seed-Prover, Lean-Workbook, RRHF, RFT and MATH-Qwen. @BytedanceTalk Prev @Alibaba_Qwen, Phd at @Tsinghua_Uni

Tuo Zhao @tourzhao
2K Followers 438 Following Associate Professor at Georgia Tech, Ph.D. in Computer Science. Research Interests: Machine Learning
Kaiqing Zhang @KaiqingZhang
1K Followers 298 Following Assistant Prof. @UofMaryland; Prev. {@MIT, @SimonsInstitute, @ECEILLINOIS, @Tsinghua_Uni}; Interested in Control, Game Theory, Machine Learning, and Robotics
Alex Kontorovich @AlexKontorovich
29K Followers 806 Following Mathematician (Distinguished Professor of #Math at @RutgersU). Here to learn about research, education, and community. Let’s build something together.
Princeton Computer Sc... @PrincetonCS
6K Followers 195 Following The Department of Computer Science at Princeton University
Max Welling @wellingmax
39K Followers 472 Following
Princeton Alumni @princetonalumni
9K Followers 578 Following Stay connected with and be inspired by fellow #PrincetonAlumni from every generation in every corner of the globe. 🐅
Yu Huang @yuhuang42
466 Followers 547 Following PhD student @Wharton Statistics|CS MSc, Math Undergrad, @Tsinghua_Uni
Haoxuan (Steve) Chen @haoxuan_steve_c
913 Followers 3K Following Ph.D. in ICME @Stanford; B.S. @Caltech; ML Intern @AmazonScience @NECLabsAmerica; Applied & Computational Math/Machine Learning/Statistics/Scientific Computing
Fred Zhangzhi Peng @pengzhangzhi1
527 Followers 628 Following #ML & #ProteinDesign. PhD student @DukeU.
leloy! @leloykun
6K Followers 4K Following Math @ AdMU • NanoGPT speedrunner • Muon fan 🤍 • prev ML @ XPD • 2x IOI & 2x ICPC • https://t.co/nfO038itfn
Jia-Bin Huang @jbhuang0604
65K Followers 284 Following
Shizhe Diao @shizhediao
4K Followers 2K Following Research Scientist @NVIDIA focusing on efficient post-training of LLMs. Finetuning your own LLMs with LMFlow: https://t.co/UTykmQBwFr Views are my own.
Canyu Chen @CanyuChen3
2K Followers 2K Following Visiting @UCBerkeley|CS Ph.D. @NorthwesternU | NU MLL Lab https://t.co/hdfRB0CmCy | Truthful, Safe and Responsible (Multimodal) LLMs | Foundation Agent
Honam Wong @MH2023ML
405 Followers 1K Following CS PhD @Penn | Prev @HKUST🇭🇰 | Theory and Empirical Science of Deep Learning
Zhiyong Wang @Zhiyong16403503
782 Followers 4K Following Ph.D. candidate at CUHK. Former Visiting Scholar at Cornell. Working on reinforcement learning and multi-armed bandits.
Haoyu Xiong @Haoyu_Xiong_
3K Followers 2K Following PhD student @MIT_CSAIL | Prev @Stanford @CMU_Robotics #Robot_LearningTrends for United States
You might like



















