
Zhiyong Wang @Zhiyong16403503
Ph.D. candidate at CUHK. Former Visiting Scholar at Cornell. Working on reinforcement learning and multi-armed bandits. zhiyongwangwzy.github.io Hong Kong Joined September 2021-
Tweets135
-
Followers782
-
Following4K
-
Likes2K

New in the #DeeperLearningBlog: @GaoZhaolin and collaborators including the #KempnerInstitute's Kianté Brantley presents a powerful new #RL algorithm tailored for reasoning tasks with #LLMs that updates using only one generation per prompt. bit.ly/44US1Mt @xkianteb #AI

Delighted to announce that the 2nd edition of our workshop has been accepted to #NeurIPS2025! We have an amazing lineup of speakers: @WenSun1, @ajwagenmaker, @yayitsamyzhang, @MengdiWang10, @nanjiang_cs, Alessandro Lazaric, and a special guest!

How can small LLMs match or even surpass frontier models like DeepSeek R1 and o3 Mini in math competition (AIME & HMMT) reasoning? Prior work seems to suggest that ideas like PRMs do not really work or scale well for long context reasoning. @kaiwenw_ai will reveal how a novel…

How can small LLMs match or even surpass frontier models like DeepSeek R1 and o3 Mini in math competition (AIME & HMMT) reasoning? Prior work seems to suggest that ideas like PRMs do not really work or scale well for long context reasoning. @kaiwenw_ai will reveal how a novel…
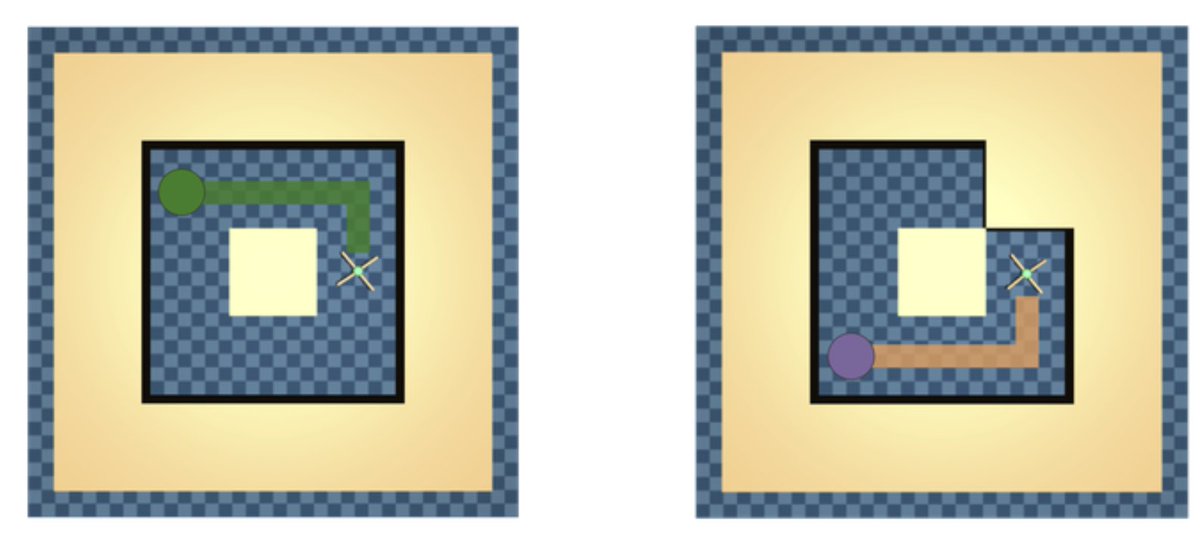
Happy to share our work "Provable Zero-Shot Generalization in Offline Reinforcement Learning" at ICML 2025! 📍 Poster | 🗓️July 16, 11:00 AM – 1:30 PM 📌 West Exhibition Hall B2-B3 #W-1012 🤖 How can offline RL agents generalize zero-shot to unseen environments? We introduce…
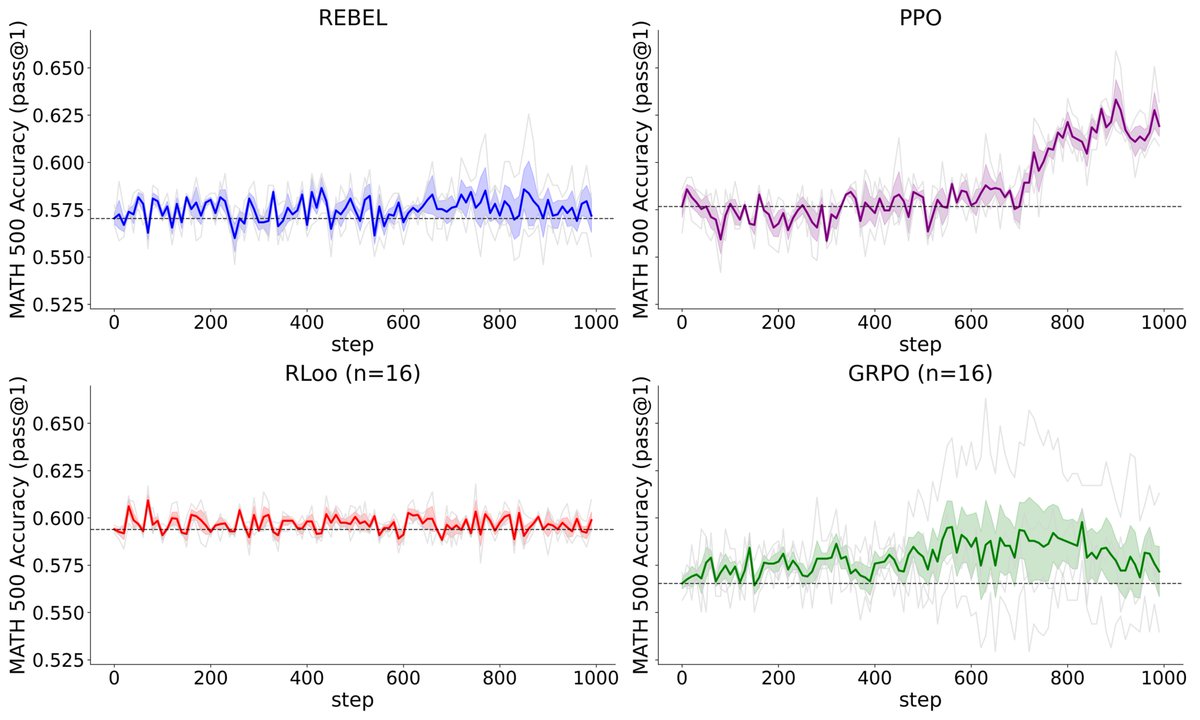
Does RL actually learn positively under random rewards when optimizing Qwen on MATH? Is Qwen really that magical such that even RLing on random rewards can make it reason better? Following prior work on spurious rewards on RL, we ablated algorithms. It turns out that if you…

Does RL actually learn positively under random rewards when optimizing Qwen on MATH? Is Qwen really that magical such that even RLing on random rewards can make it reason better? Following prior work on spurious rewards on RL, we ablated algorithms. It turns out that if you…
Curious how to combine federated learning and in-context learning for QA tasks — with privacy preservation, efficiency, and boosting performance round by round? 🚀 Meet Fed-ICL — our framework collaboratively refines answers without transmitting model weights or sharing raw…

Tired of over-optimized generations that stray too far from the base distribution? We present SLCD: Supervised Learning based Controllable Diffusion, which (provably) solves the KL constrained reward maximization problem for diffusion through supervised learning! (1/n)


by incorporating self-consistency during offline RL training, we unlock three orthogonal directions of scaling: 1. efficient training (i.e. limit backprop through time) 2. expressive model classes (e.g. flow matching) 3. inference-time scaling (sequential and parallel) which,…

Excellently written paper

I won't be at #ICLR2025 myself this time around but please go talk to lead authors @nico_espinosa_d, @GaoZhaolin, and @runzhe_wu about their bleeding-edge algorithms for imitation learning and RLHF!


Heading to #ICLR2025 🇸🇬! Excited to connect with friends and chat about RL: theory, LLM reasoning and robotics! I will present our Oral paper on LLM self-improvement📍4:18pm Sat. Join me if you want to learn about its scaling laws, iterative training and test-time improvement.


What is the place of exploration in today's AI landscape and in which settings can exploration algorithms address current open challenges? Join us to discuss this at our exciting workshop at @icmlconf 2025: EXAIT! exait-workshop.github.io #ICML2025

I think of misspecification (embodiment / sensory gaps) as the fundamental reason behavioral cloning isn't "all you need" for imitation as matching actions != matching outcomes. Introducing @nico_espinosa_d's #ICLR2025 paper proving that "local search" *is* all you need! [1/n]

Meet the recipients of the 2024 ACM A.M. Turing Award, Andrew G. Barto and Richard S. Sutton! They are recognized for developing the conceptual and algorithmic foundations of reinforcement learning. Please join us in congratulating the two recipients! bit.ly/4hpdsbD

🚀 Rising Star Workshops for Junior/Senior PhDs, and Postdocs! 🌟 Don't miss these career-boosting opportunities! notion.so/List-of-Rising… Please share with your peers, students, and anyone who might benefit! #PhD #Postdoc #Academia #RisingStars


There are multiple postdoc positions available as part of an exciting new AI-agent initiative at Columbia that tackles challenges at the frontier of agentic systems and sequential decision-making. I am not very active here so please help me spread the word!
Extremely honored to receive this award. Credit goes to my collaborators, mentors, and especially my amazing students! #SloanFellow

Extremely honored to receive this award. Credit goes to my collaborators, mentors, and especially my amazing students! #SloanFellow


List of accepted papers for AISTATS 2025 is now available. aistats.org/aistats2025/ Congratulations to the authors and thanks to the reviewers, AC, and SACs for their help. Thanks to my co-chair @ashipra & workflow chairs: Christopher Anders (RIKEN) & Tingting Ou (Columbia).

check this out: new postdoc program for AI-related research in Catalunya! our group is looking to hire within this program, ideally to work on topics related to RL theory. in case you're interested, pls DM or email me. (retweets appreciated!) ramonllull-aira.eu/application

SMILING😊 is accepted to #ICLR2025! Do not miss it if you're seeking an imitation learning algorithm with rigorous theory and strong empirical results!
SMILING😊 is accepted to #ICLR2025! Do not miss it if you're seeking an imitation learning algorithm with rigorous theory and strong empirical results!

殘缺的溫柔🌸 @MileySwagJDB
4 Followers 421 Following ( ´ ▽ ` )ノ哈嘍~這裡是殘柔 來自臺北 ε(*・ω・)_/゚:・☆ 興趣愛好是打高爾夫球🏌🏻♀️,游泳🏊🏻♀️,騎行🚴🏻♀️,瑜伽🧘🏻♀️,潛水🤿

Tiffany @tiffany86villan
264 Followers 3K Following
Yifan Zhang @yifan_zhang_
319 Followers 343 Following Ph.D. student at Princeton University, focusing on LLMs.
EveMill @4C530dtJO3FkKyk
17 Followers 406 Following


Holly @Mweesalp16030
29 Followers 1K Following
Jason Liu @JasonLiu106968
76 Followers 71 Following
River @Asulip865636
25 Followers 1K Following

Yifan WANG @ywangpa2004
18 Followers 358 Following UG@HKUST working on Sim-to-real Video generation, currently supervised by Prof. Qifeng CHEN
Vlirkiec @Vlirkiec583
79 Followers 1K Following
Iemouvo @Iemouvo942
13 Followers 918 Following

🌎 @ascetic_one
34 Followers 1K Following
Ryan Chan @ryanchankh
353 Followers 1K Following Machine Learning PhD at @penn. Interested in the theory and practice of interpretable and interactive machine learning.
Marpee @Marpee251
23 Followers 590 Following
Peng Zhao @ZhaoPeng_NJU
156 Followers 225 Following online learning, optimization, machine learning.


WeiCUI6 @Cui6Wei
35 Followers 746 Following Systems Software Engineer @NVIDIA. Prev @UofT @UCLA @KITE_UHN @Tesla @Samsung @Apple. Working on @NVIDIAGFN
Zijie Huang@ACL2025(v... @HuangZi71008374
1K Followers 703 Following Research Scientist @GoogleDeepMind. Prev @UCLA @SJTU1896 @Amazon @Nvidia @Netflix; Work on #LLM, #AI4Science, #GraphML.
Shangzhe Li @DVA13304
78 Followers 217 Following CS PhD student @UNC. Reinforcement Learning Researcher. Previously interned @UICCS, @TU_Muenchen, @HaoSuLabUCSD.
Avery Ma @avery__ma
19 Followers 47 Following
Yuki Wang @YukiWang_hw
94 Followers 122 Following Third Year CS Ph.D. Student at Cornell University @CornellCIS A member of the PoRTaL group @PortalCornell!
Bradley Guo @BradleyZGuo
10 Followers 104 Following cs undergrad @cornell | reinforcement learning / generative models
Yoram Bachrach @yorambac
3K Followers 7K Following Research Scientist at Meta (prev Google DeepMind and Microsoft Research). Working on LLM Agents and Multi-Agent Systems.
DividendAristo🇺�... @Awhatil7958
42 Followers 2K Following 15-30% Monthly | 2 High-Conviction Stocks.Short-Term Gains: 15-20% in Days/Weeks.DM "JOIN" for WhatsApp Alerts. Live Trade Signals • Market Analysis
Oskar Weinfurtner @oskarwein
6 Followers 527 Following
Audruiehir @Audruiehir559
28 Followers 554 Following
Pierfrancesco Beneven... @PierBeneventano
520 Followers 817 Following Postdoc at @MIT | ex PhD student @Princeton | Exploring how to train AIs and their interaction with the world, while brewing my espresso.

Fengzhuo Zhang @FengzhuoZhang
88 Followers 315 Following ECE PhD student @NUSingapore | Previous: EE undergrad @Tsinghua_Uni
Chuanming @ChuanmingLiu
326 Followers 7K Following Ex-PhD student and alumni @sjtu1896 . Global citizen. Bootstrapping silicon-based life. Lifelong learning practitioner. Amateur triathlete and marathoner.
Sara Gh @gh_sara90433
8 Followers 472 Following

Tianbao (TB) Yang @yang_ML
613 Followers 1K Following Professor at Texas A&M University; ML/AI researcher; optimization for ML/AI; large reasoning models, developing LibAUC library for training deep neural nets.
Hongru Wang @HongruWang007
449 Followers 805 Following Ph.D @CUHKofficial, Prev @EdinburghNLP @uiuc_nlp, Intern: ByteDance-Seed @BytedanceTalk, Work: Self-DC, OTC-PO, Theory of Agent
GailNewton @5x2I530x3rcidcW
117 Followers 3K Following

Cuong Dang @ ACL24 @CaptainCuong
140 Followers 2K Following x-Research Resident @fpt_software, VietNam. Incoming CE PhD Student @virginia_tech. Working on Machine Learning, Fair AI, Explainable AI, Robust AI, NLP
Jintian靳天@Earn Da... @angelheavenzzz
448 Followers 4K Following CTO of @earn_dao_ I forgive this world. 我赦免这个世界。
Ziniu Li @ZiniuLi
501 Followers 511 Following Ph.D. student @ CUHK, Shenzhen. Intern @Bytedance (Seed-Horizon) Working on RL and LLMs. Prev: Intern @Tencent (AI Lab)
Shawn/Yuxuan TONG @tongyx361
316 Followers 357 Following Senior undergraduate @thudcst. Research intern @LTIatCMU (previously:@HKUST-NLP, @thukeg). Interested in LLM & AI for Education/Research/Software Eng.
Xutong (James) Liu @XutongLiu_CMU
5 Followers 100 Following Postdoc @CMU_ECE & @UMassAmherst. Working on reinforcement learning to make optimal decisions in AI computing and communication systems.
Peilun @PEILUN10
5 Followers 82 Following A Doctoral student || Medical AI, M.Res @imperialcollege || B.Eng @unibirmingham

Joann @joann_ortiz91
188 Followers 3K Following
Mengyue Yang @Mengyue_Yang_
2K Followers 840 Following Assistant Professor at @BristolUni, PhD from @UCL, prev. intern in @TikTok & @Microsoft. ✨ Reinforcement Learning, Causality, World Models.
Jason Liu @JasonLiu106968
76 Followers 71 Following
KShivendu 👨🚀... @KShivendu_
996 Followers 1K Following building the future of search @qdrant_engine I love search, distributed systems, and llms · Creator of SmolDB
Shuchao Bi @shuchaobi
13K Followers 689 Following Research @Meta Superintelligence Labs, RL/post-training/agents; Previously Research @OpenAI on multimodal and RL; Opinions are my own.
tao terrence @terrence_tao
5K Followers 1 Following Tao's my name and math is my thing:) I could say my greatest quality is that I have my own theorem, you know the green-tao theorem, everyone's heard of that:)
ChengSong Huang @ChengsongH31219
103 Followers 80 Following @WUSTL CSE PhD candidate . Former B.Eng. in Software Engineering @FudanUni AI researcher. Interested in LLM efficiency and reasoning.
Wenxuan Zhang @Wenxuan__Zhang
514 Followers 196 Following Assistant Professor @ SUTD | Inclusive + Trustworthy AI | Multilingual LLMs #LLM4Everyone
Feng Yao @fengyao1909
1K Followers 634 Following Ph.D. student @UCSD_CSE | Intern @Amazon Rufus Foundation Model Ex. @MSFTResearch @TsinghuaNLP

Zhaofeng Wu @zhaofeng_wu
2K Followers 263 Following PhD student @MIT_CSAIL | Previously @allen_ai | MS'21 BS'19 BA'19 @uwnlp
verl project @verl_project
1K Followers 5 Following Open RL library for LLMs. https://t.co/Xpaq0thhgi Join us on https://t.co/uWI5Zbd6IH
Andrew Wagenmaker @ajwagenmaker
459 Followers 106 Following Postdoc @ UC Berkeley with Sergey Levine | PhD @ UW.

Chuan Meng @ChuanMg
298 Followers 279 Following PhD at University of Amsterdam, working on Information Retrieval and Natural Language Processing | Former Applied Scientist Intern at Amazon
Chujie Zheng @ChujieZheng
6K Followers 301 Following Researcher @Alibaba_Qwen | GSPO, Qwen3, QwQ, ProcessBench | Opinions are my own
Delta Institute @DeltaInstitutes
1K Followers 39 Following Supporting exceptional researchers/engineers, from academia to industry and beyond.
Alexander Wei @alexwei_
24K Followers 193 Following Reasoning @OpenAI. Co-built CICERO @MetaAI | @Berkeley_AI PhD '23 | @Harvard '20

AI for Math Workshop ... @ai4mathworkshop
110 Followers 21 Following 2nd AI for Math Workshop @ ICML 2025 West Ballroom C, Vancouver Convention Center July 18th, 2025 @ Vancouver, Canada (Hybrid)
Jie M. Zhang @JieMarinaZhang
671 Followers 298 Following Lecturer of Computer Science at King's College London
Yuxiao Qu @QuYuxiao
315 Followers 111 Following PhD @mldcmu, advised by @aviral_kumar2 and @rsalakhu Interests: Reasoning & RL & FMs Prev: @UWMadison, @UW, @CUHKofficial
Shangzhe Li @DVA13304
78 Followers 217 Following CS PhD student @UNC. Reinforcement Learning Researcher. Previously interned @UICCS, @TU_Muenchen, @HaoSuLabUCSD.
Ruhan Wang @iu_ruhan
5 Followers 7 Following Ph.D. Candidate in Computer Engineering at Indiana University
Gugan Thoppe @GThoppe
237 Followers 125 Following Asst. Prof. @IIScCSA PhD @TIFRScience Postdocs @TechnionLive, @DukeU Part of @Indiaacm eminent speaker panel #ReinforcementLearning #RLTheory
Avery Ma @avery__ma
19 Followers 47 Following
Daniel Kang @daniel_d_kang
5K Followers 92 Following Asst. professor at UIUC CS. Formerly in the Stanford DAWN lab and the Berkeley Sky Lab.

Yue Feng @YueFeng__
557 Followers 406 Following Assistant Professor @unibirmingham, PhD @ucl, working on NLP and IR.
Giuseppe Loianno @loiannog
910 Followers 374 Following Professor of Robotics @UCBerkeley. Director of the ARPL Agile Robotics and Perception Lab

Xiang Yue @xiangyue96
5K Followers 828 Following Postdoc @LTIatCMU. PhD from Ohio State @osunlp. Author of MMMU, MAmmoTH. Training & evaluating foundation models. Opinions are my own.
Yoram Bachrach @yorambac
3K Followers 7K Following Research Scientist at Meta (prev Google DeepMind and Microsoft Research). Working on LLM Agents and Multi-Agent Systems.
Sean Xuefeng Du @xuefeng_du
2K Followers 3K Following Incoming Assistant Professor @NTUsg | Ph.D. @WisconsinCS, fellow @JaneStreetGroup | reliable machine learning 🤖️ ⛑️

Yatao Bian-Prof@NUS C... @yataobian
195 Followers 412 Following Incoming Prof. at NUS Computer Science on AI4Sci & Machine Learning. Currently recruiting students (PhDs, Postdocs, RAs, interns etc). Email me if interested!
Brian @yep_its_brian1
281 Followers 5K Following There's always another great trade out there somewhere. It's just a matter of seeing it
Bradley Guo @BradleyZGuo
10 Followers 104 Following cs undergrad @cornell | reinforcement learning / generative models

Lukasz Szpruch @LSzpruch
90 Followers 375 Following Professor of Maths at @EdinburghUni, Programme Director for Finance and Economics at @turinginst, co-founder of @simtopia_ai
Tong Wu @TongWu_Pton
500 Followers 2K Following Princeton; LLM safety reasoning; Google; Zoom; Microsoft; Looking for full- time research opportunities
Pierfrancesco Beneven... @PierBeneventano
520 Followers 817 Following Postdoc at @MIT | ex PhD student @Princeton | Exploring how to train AIs and their interaction with the world, while brewing my espresso.

Penghui Qi @QPHutu
120 Followers 105 Following Senior Research Engineer @SeaAIL PhD student @NUSingapore Working on RL, LLM Reasoning, and MLSys.
Fengzhuo Zhang @FengzhuoZhang
88 Followers 315 Following ECE PhD student @NUSingapore | Previous: EE undergrad @Tsinghua_Uni
Cheng Deng @davendw
42 Followers 193 Following
Zhaowei Wang @ZhaoweiWang4
984 Followers 779 Following Visiting @EdinburghNLP with Mark Steedman | PhD student @hkustNLP with @yqsong | @NVIDIAAI and @TencentGlobal
ML@CMU @mlcmublog
2K Followers 20 Following Official twitter account for the ML@CMU blog @mldcmu @SCSatCMU
Stella Li @StellaLisy
3K Followers 443 Following PhD student @uwnlp | visiting researcher @AIatMeta | undergrad @jhuclsp #NLProc
FoPt 2025 @FoPt2025
11 Followers 7 Following Workshop on the Foundations of Post-training at COLT 2025 @AssocCompLearn. A deep dive into the theoretical and practical aspects of the post-training of LLMs.Trends for United States
You might like



















