
Jiarui Yao @ExplainMiracles
UIUC CS PhD, 24 Joined May 2023-
Tweets19
-
Followers84
-
Following510
-
Likes53

🤝 Can LLM agents really understand us? We introduce UserBench: a user-centric gym environment for benchmarking how well agents align with nuanced human intent, not just follow commands. 📄 arxiv.org/pdf/2507.22034 💻 github.com/SalesforceAIRe…


(1/4)🚨 Introducing Goedel-Prover V2 🚨 🔥🔥🔥 The strongest open-source theorem prover to date. 🥇 #1 on PutnamBench: Solves 64 problems—with far less compute. 🧠 New SOTA on MiniF2F: * 32B model hits 90.4% at Pass@32, beating DeepSeek-Prover-V2-671B’s 82.4%. * 8B > 671B: Our 8B…



Reward models (RMs) are key to language model post-training and inference pipelines. But, little is known about the relative pros and cons of different RM types. 📰 We investigate why RMs implicitly defined by language models (LMs) often generalize worse than explicit RMs 🧵 1/6


🎥 Video is already a tough modality for reasoning. Egocentric video? Even tougher! It is longer, messier, and harder. 💡 How do we tackle these extremely long, information-dense sequences without exhausting GPU memory or hitting API limits? We introduce 👓Ego-R1: A framework…
Can LLMs make rational decisions like human experts? 📖Introducing DecisionFlow: Advancing Large Language Model as Principled Decision Maker We introduce a novel framework that constructs a semantically grounded decision space to evaluate trade-offs in hard decision-making…


(1/5) Want to make your LLM a skilled persuader? Check out our latest paper: "ToMAP: Training Opponent-Aware LLM Persuaders with Theory of Mind"! For details: 📄Arxiv: arxiv.org/pdf/2505.22961 🛠️GitHub: github.com/ulab-uiuc/ToMAP

📢 New Paper Drop: From Solving to Modeling! LLMs can solve math problems — but can they model the real world? 🌍 📄 arXiv: arxiv.org/pdf/2505.15068 💻 Code: github.com/qiancheng0/Mod… Introducing ModelingAgent, a breakthrough system for real-world mathematical modeling with LLMs.



How to improve the test-time scalability? - Separate thinking & solution phases to control performance under budget constraint - Budget-Constrained Rollout + GRPO - Outperforms baselines on math/code. - Cuts token 30% usage without hurting performance huggingface.co/papers/2505.05…
🚀 Can we cast reward modeling as a reasoning task? 📖 Introducing our new paper: RM-R1: Reward Modeling as Reasoning 📑 Paper: arxiv.org/pdf/2505.02387 💻 Code: github.com/RM-R1-UIUC/RM-… Inspired by recent advances of long chain-of-thought (CoT) on reasoning-intensive tasks, we…


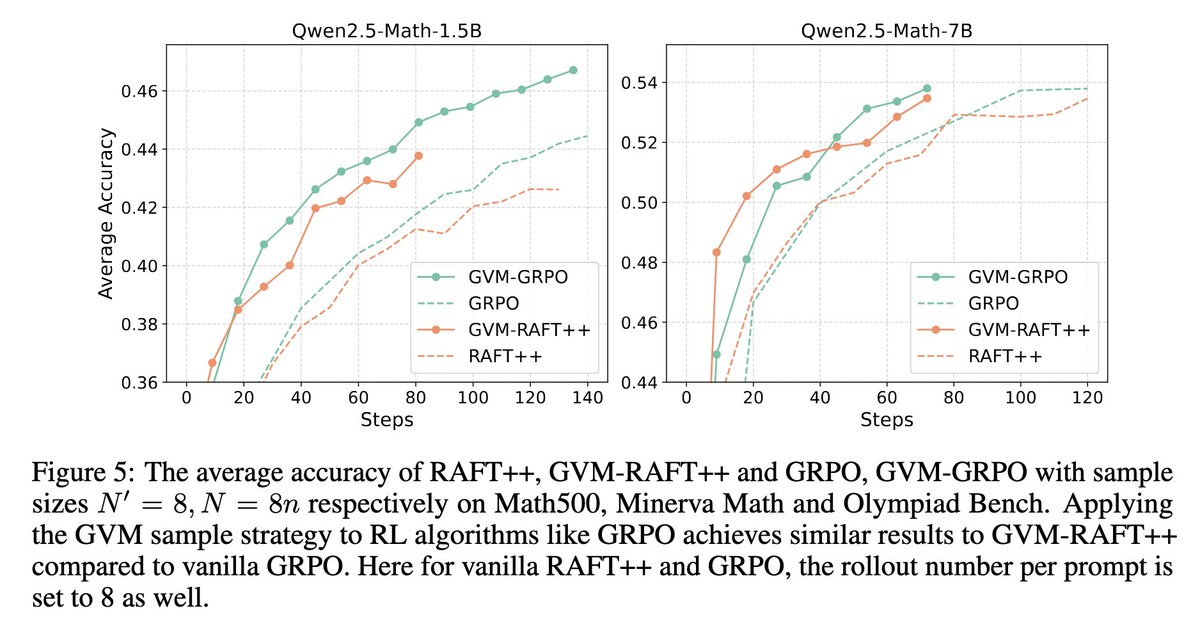
We introduce Gradient Variance Minimization (GVM)-RAFT, a principled dynamic sampling strategy that minimizes gradient variance to improve the efficiency of chain-of-thought (CoT) training in LLMs. – Achieves 2–4× faster convergence than RAFT – Improves accuracy on math…



Thrilled to announce that our paper Sparse VideoGen got into #ICML2025! 🎉 Our new approach to speedup Video Generation by 2×. Details in the thread/paper. Huge thanks to my collaborators! Blog: svg-project.github.io Paper: arxiv.org/abs/2502.01776 Code:…
Thrilled to announce that our paper Sparse VideoGen got into #ICML2025! 🎉 Our new approach to speedup Video Generation by 2×. Details in the thread/paper. Huge thanks to my collaborators! Blog: svg-project.github.io Paper: arxiv.org/abs/2502.01776 Code:…

Welcome to join our Tutorial on Foundation Models Meet Embodied Agents, with @YunzhuLiYZ @maojiayuan @wenlong_huang ! Website: …models-meet-embodied-agents.github.io


Thrilled to share my first project at NVIDIA! ✨ Today’s language models are pre-trained on vast and chaotic Internet texts, but these texts are unstructured and poorly understood. We propose CLIMB — Clustering-based Iterative Data Mixture Bootstrapping — a fully automated…

Negative samples are "not that important", while removing samples with all negative outputs is "important". 🤣
Negative samples are "not that important", while removing samples with all negative outputs is "important". 🤣
🚀Can your language model think strategically? 🧠 SMART: Boosting LM self-awareness to reduce Tool Overuse & optimize reasoning! 🌐 arxiv.org/pdf/2502.11435 📊 github.com/qiancheng0/Ope… Smaller models, bigger brains. Smarter tool use, better results! 🔥 #AI #LLM


🚀 Excited to share our latest work on Iterative-DPO for math reasoning! Inspired by DeepSeek-R1 & rule-based PPO, we trained Qwen2.5-MATH-7B on Numina-Math prompts. Our model achieves 47.0% pass@1 on AIME24, MATH500, AMC, Minerva-Math, OlympiadBench—outperforming…



Yunsheng Tian @YunshengTian
888 Followers 698 Following 🤖 Applied Scientist @Amazon FAR (Frontier AI & Robotics) | PhD @MIT_CSAIL

Sansa Gong @sansa19739319
464 Followers 285 Following Text Diffusion Models; PhD @hkunlp2020 Prev. @sjtu1896
Shangchen Zhou @ShangchenZhou
1K Followers 514 Following Research Assistant Professor at NTU @MMLabNTU - Computer Vision
Lingdong Kong @ldkong1205
1K Followers 480 Following - PhD Candidate @NUSComputing 🦁 - 2025 @Apple PhD Scholar in AI/ML - 3D Scene Perception, Generation, and World Modeling
Yusu Qian @sueqian111
1K Followers 450 Following multimodal research at Apple, previously at NYU @nyuniversity and NJU @njuniversity

Glooji @Glooji89061
24 Followers 2K Following
Shanyong Wang @Swimmingwang04
9 Followers 71 Following Now visiting at @RutgersU | Exchange @UofIllinois | Undergraduate @ShanghaiTechUni
Zhaoxi Chen @Frozen_Burning
1K Followers 918 Following Ph.D. student @MMLabNTU | Neural Rendering & 3D Generation | Ex Intern @RealityLabs | Undergrad @Tsinghua_Uni
HUANG Qichang @huang85993
356 Followers 8K Following
Kaiyu Yang @KaiyuYang4
4K Followers 2K Following Research Scientist at @Meta Fundamental AI Research (FAIR), New York. Previously: Postdoc @Caltech, PhD @PrincetonCS, Undergrad @Tsinghua_Uni.
Howard @howzzz213
33 Followers 932 Following
Mr. Jack Tung @MrJackTung
294 Followers 6K Following
Jovan Carter @JovanC64207
105 Followers 4K Following
Zhiyong Wang @Zhiyong16403503
782 Followers 4K Following Ph.D. candidate at CUHK. Former Visiting Scholar at Cornell. Working on reinforcement learning and multi-armed bandits.
Sweedaur @Sweedaur477
13 Followers 780 Following
Deeksha Varshney @Deeksha63834527
266 Followers 1K Following Assistant Professor @IIT Jodhpur; Research Fellow @NUS; PhD @IITPatna; Working on LLM's and their interpretabilty.
Zijia Liu @xwzliuzijia
12 Followers 29 Following Visiting @uiuc_nlp | PhD Candidate @Tongji_Uni | #LLM #AI4S
Zhengyi “Zen” Luo @zhengyiluo
4K Followers 1K Following Research Scientist, GEAR @NvidiaAI | PhD @CMU_Robotics | Founder @CirkitDesign | CS @penn

Tianbao (TB) Yang @yang_ML
613 Followers 1K Following Professor at Texas A&M University; ML/AI researcher; optimization for ML/AI; large reasoning models, developing LibAUC library for training deep neural nets.
XYP @XP_research
14 Followers 47 Following Applied Scientist @ Amazon AGI, prev UIUC CS, Interested in Data-centric AI, LLM, Data Attribution
Johan Obando-Ceron �... @johanobandoc
2K Followers 4K Following Graduate student @Mila_Quebec @UMontrealDIRO | RL/Deep Learning/AI | De Cali/Colombia pal’ Mundo 🇨🇴 | #JuntosProsperamos⚡#TogetherWeThrive| 🌱🌎

harpreet singh @harpree67826976
3 Followers 400 Following
Young @younqchan
327 Followers 5K Following Researcher working on Out-of-Distribution Generalizable Reasoning and AI Scientist from causality perspective.
Zhanpeng Zhou @zhanpeng_zhou
274 Followers 382 Following Ph.D. candidate @sjtu1896 | Exploring the theoretical foundations of deep learning.
B @bbbb_bb_b
0 Followers 4K Following
Xuheng Li @xuhengli_
955 Followers 2K Following CS PhD candidate @UCLA, supervised by @QuanquanGu | RL, deep learning theory, diffusion model | Previously BSc @PKU1898 | Stargazer
MASSIL @Massilabatna
0 Followers 0 Following
Quanquan Gu @QuanquanGu
16K Followers 2K Following Professor @UCLA, Pretraining and Scaling at ByteDance Seed | Recent work: Build AGI | Opinions are my own

Chloe H. Su @Huangyu58589918
504 Followers 917 Following CS PhD @Harvard @KempnerInst Automated Reasoning @AmazonScience Prev @mldcmu @ntusg
juxiliu789 @juxiliu789
79 Followers 8K Following

Regret @ImperialistsL
382 Followers 718 Following guess how long ill stay jobless until my phd application gets accepted
isomorphicat @isomorphicneko
32 Followers 677 Following PhD student in Statistics; doing machine learning related research
Alexandre Borghi @_Alex_Borghi_
458 Followers 4K Following ML @SambaNovaAI | Prev. ML research @graphcoreai and @ImaginationTech.
I07XNbUI4 @DeepFeed2
76 Followers 5K Following
Gracelyn @coderlin3
85 Followers 3K Following
Runxin Xu @pigjunebaba
7K Followers 3K Following AI researcher @deepseek_ai | @PKU1898 | @SJTU1896 Opinions are my own.
Tim @Glorious_Tim
126 Followers 3K Following
Simon Shaolei Du @SimonShaoleiDu
8K Followers 2K Following Assistant Professor @uwcse. Postdoc @the_IAS. PhD in machine learning @mldcmu.
Masoud @alborz_esf
124 Followers 2K Following
Xiusi Chen @xiusi_chen
614 Followers 457 Following Postdoc @UofIllinois @uiuc_nlp, Ph.D. @UCLA, BS @PKU1898. RM-R1. Ex-Intern @AmazonScience (x2),@NECLabsAmerica. LLM, Neuro-Symbolic AI.
Peixuan Han @peixuanhakhan
85 Followers 79 Following 2nd year Ph.D. student at UIUC @IllinoisCS LLM Researcher Prev: Tsinghua @Tsinghua_Uni CS Undergrad Amazon @amazon 25Summer Intern
Hongru Wang @HongruWang007
449 Followers 805 Following Ph.D @CUHKofficial, Prev @EdinburghNLP @uiuc_nlp, Intern: ByteDance-Seed @BytedanceTalk, Work: Self-DC, OTC-PO, Theory of Agent
Haocheng Xi @HaochengXiUCB
596 Followers 1K Following First-year PhD in @berkeley_ai. Prev: Yao Class, @Tsinghua_Uni | Efficient Machine Learning & ML sys

Sharon Zhou @realSharonZhou
25K Followers 0 Following Building & teaching AI | VP of AI, @AMD | Prev: Founder & CEO, Lamini. CS Faculty & PhD @Stanford. @Google. @Harvard | @MIT 35 under 35. Angel investor.
Lifan Yuan @lifan__yuan
2K Followers 137 Following PhD student @uiuc_nlp @GoogleDeepMind. Prev: @TsinghuaNLP
Yining Ye(叶奕宁) @Yining_Ye
317 Followers 227 Following Working on LLM/VLM Tool Learning and Reasoning at Tsinghua and Bytedance, reading at least one paper a day — The future will not invent itself.
Jure Leskovec @jure
44K Followers 394 Following Professor of #computerscience @Stanford; Co-founder at https://t.co/hhm1j5wP0f #machinelearning #graphs.
Zhi Su @ZhiSu22
2K Followers 137 Following Undergrad @Tsinghua_IIIS | 🤖 Robot Learning | Looking for PhD position
Princeton NLP Group @princeton_nlp
5K Followers 61 Following Princeton NLP Group led by @prfsanjeevarora @danqi_chen @karthik_r_n
Princeton PLI @PrincetonPLI
2K Followers 32 Following Princeton University initiative enhancing fundamental understanding of AI, enabling its use in academic disciplines, and examining AI's societal implications.
He Wang @HughWang19
2K Followers 153 Following Assistant Professor of Computer Science at Peking University, Founder and CTO of Galbot.
Fan Nie @FanNie1208
749 Followers 353 Following AI @Stanford | Prev. @EPFL @SJTU1886 |Research in Reliable AI & Large Language Models
Jiayi Geng @JiayiiGeng
1K Followers 204 Following PhD @LTIatCMU | MSE @Princeton_nlp @PrincetonPLI @cocosci_lab @PrincetonCS. Working on Multi-agent / Cognitive science & LLMs
Wei-Chiu Ma @weichiuma
2K Followers 208 Following Assistant Professor @Cornell @CornellCIS Prev: Postdoc @allen_ai @uwcse; PhD @MIT_CSAIL; Sr. Research Scientist @UberATG @Waabi_ai
Yunsheng Tian @YunshengTian
888 Followers 698 Following 🤖 Applied Scientist @Amazon FAR (Frontier AI & Robotics) | PhD @MIT_CSAIL
Rocky Duan @rocky_duan
3K Followers 97 Following Research Lead @ Amazon FAR (Frontier AI & Robotics). Previously @CovariantAI CTO, @OpenAI, @UCBerkeley PhD. 2024 Forbes 30 Under 30.
zhyncs @zhyncs42
3K Followers 520 Following 🌁 OPINIONS ARE MY OWN, Homepage https://t.co/saCowtppUm, Just for fun @lmsysorg SGLang, Prev @basetenco @meituan @Baidu_Inc
a16z @a16z
874K Followers 52 Following we invest in software eating the world https://t.co/A9eTFq6plZ https://t.co/MXGUBJoesw Watch "The Ben & Marc Show": https://t.co/eRuDhx7kpe

Fangru Lin @FangruLin99
3K Followers 459 Following DPhil student @UniofOxford; Clarendon Scholar; Prev Research @MSFTResearch, Engineer @Microsoft, Student @turinginst; Computational Linguist
Richard Sutton @RichardSSutton
45K Followers 64 Following Student of mind and nature, libertarian, chess player, cancer survivor. @ Keen, UAlberta, Amii, https://t.co/u8za2Kod54, The Royal Society, Turing Award
Zhijian Liu @zhijianliu_
2K Followers 822 Following Research Scientist @NVIDIA. Assistant Professor @UCSanDiego. PhD @MIT. Efficient AI. Views are my own. Anonymous Feedback: https://t.co/TsjmnTSiZH
HKUNLP @hkunlp2020
104 Followers 85 Following We are a group of researchers working on natural language processing in the Department of Computer Science at the University of Hong Kong.
Qianqian Wang @QianqianWang5
3K Followers 434 Following Postdoc at UC Berkeley and Visiting Researcher at Google. Former Ph.D. student at Cornell Tech. https://t.co/LyIdb5HmM9

Yushi Hu @huyushi98
3K Followers 1K Following 🎓PhD student @uwnlp | Prev. @AIatMeta @allen_ai @GoogleAI @UChicago | Building multimodal intelligence
Skywork @Skywork_ai
6K Followers 150 Following Skywork Super Agents: the Originator of Al Workspace Agents, turns your 8 hours of work into 8 minutes. Support: https://t.co/Zvze6mFI6E
Chuan Wen @ChuanWen15
425 Followers 321 Following Assistant Professor @sjtu1896. Prev PhD student @Tsinghua_IIIS w/ @gao_young. Prev visitor @berkeley_ai w/ @pabbeel .
Jiahui Yu @jhyuxm
18K Followers 929 Following Perception @OpenAI; previously co-led Gemini Multimodal @GoogleDeepMind. opinions are my own.
Shuchao Bi @shuchaobi
13K Followers 689 Following Research @Meta Superintelligence Labs, RL/post-training/agents; Previously Research @OpenAI on multimodal and RL; Opinions are my own.
Hongyu Ren @ren_hongyu
23K Followers 693 Following research @meta superintelligence. CS PhD @stanford. prev @openai, led the development of o3-mini and o1-mini.
Dylan Foster 🐢 @canondetortugas
3K Followers 1K Following Foundations of RL/AI @MSFTResearch. Previously @MIT @Cornell_CS https://t.co/vQIdUzsw8B RL Theory Lecture Notes: https://t.co/bhgL3aKIk0

Feng Yao @fengyao1909
1K Followers 634 Following Ph.D. student @UCSD_CSE | Intern @Amazon Rufus Foundation Model Ex. @MSFTResearch @TsinghuaNLP


Yuhuai (Tony) Wu @Yuhu_ai_
38K Followers 452 Following Co-Founder @xAI. Grok Reasoning, STaR, Minerva, AlphaGeometry, Autoformalization, AlphaStar, Memorizing transformer.
Jinjie Ni @NiJinjie
1K Followers 518 Following AI researcher building foundation models. Making some contributions to human progress.
Sansa Gong @sansa19739319
464 Followers 285 Following Text Diffusion Models; PhD @hkunlp2020 Prev. @sjtu1896
Fuxiao Liu @FuxiaoL
744 Followers 638 Following Research Scientist @Nvidia | CS PhD @UMDCSI, working on LLM, Multimodal Stuff
Xiang Yue @xiangyue96
5K Followers 828 Following Postdoc @LTIatCMU. PhD from Ohio State @osunlp. Author of MMMU, MAmmoTH. Training & evaluating foundation models. Opinions are my own.
jianlin.su @Jianlin_S
3K Followers 14 Following Grad is all you need @Kimi_Moonshot Blog: https://t.co/YVxsWylklA , Cool Papers: https://t.co/scS1n1oyaO
Shangchen Zhou @ShangchenZhou
1K Followers 514 Following Research Assistant Professor at NTU @MMLabNTU - Computer Vision

MMLab@NTU @MMLabNTU
1K Followers 18 Following Multimedia Laboratory @NTUsg, affiliated with S-Lab. Large Multimodal Models, Computer Vision, Image Processing, Computer Graphics, Deep Learning
Lingdong Kong @ldkong1205
1K Followers 480 Following - PhD Candidate @NUSComputing 🦁 - 2025 @Apple PhD Scholar in AI/ML - 3D Scene Perception, Generation, and World Modeling
Leon Liangyu Chen @cliangyu_
867 Followers 2K Following PhD student @stanfordailab, intern @Meta Superintelligence Labs


Chris Lu @_chris_lu_
4K Followers 616 Following Research @OpenAI Prev: DPhil Student @UniofOxford, RS Intern @SakanaAILabs @DeepMind and RS @CovariantAI
You Jiacheng @YouJiacheng
8K Followers 2K Following a big fan of TileLang 关注TileLang喵!关注TileLang谢谢喵! https://t.co/utshC0jrCO 十年老粉

Hexiang Hu @hexianghu
2K Followers 672 Following Grokkng @xAI: Multimodal pre-training / native image gen; Prev: gemini 1 / 2 & imagen 3 @GoogleDeepMind.Trends for United States
You might like



















