
-
Tweets426
-
Followers3K
-
Following595
-
Likes339

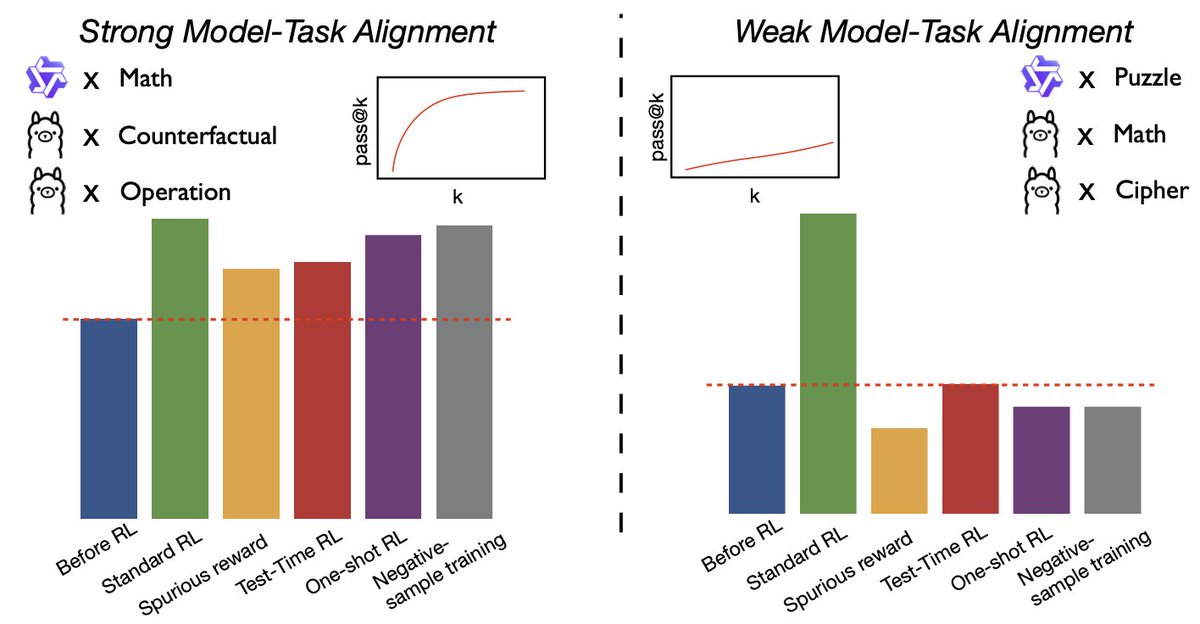
Mirage or method? We re-assess a series of RL observations such as spurious reward, one-shot RL, test-time RL, and negative-sample training. 🧐These approaches were all proved on Qwen+Math combination originally, but do they work in other settings? If not, under which…


Feels like everyone is slowly admitting that there's no moat in foundational models, and the only way to build a business out of AI is to build products.


seems like worktrees / workspaces are going to be essential if we're going to have 20 agents going at once.

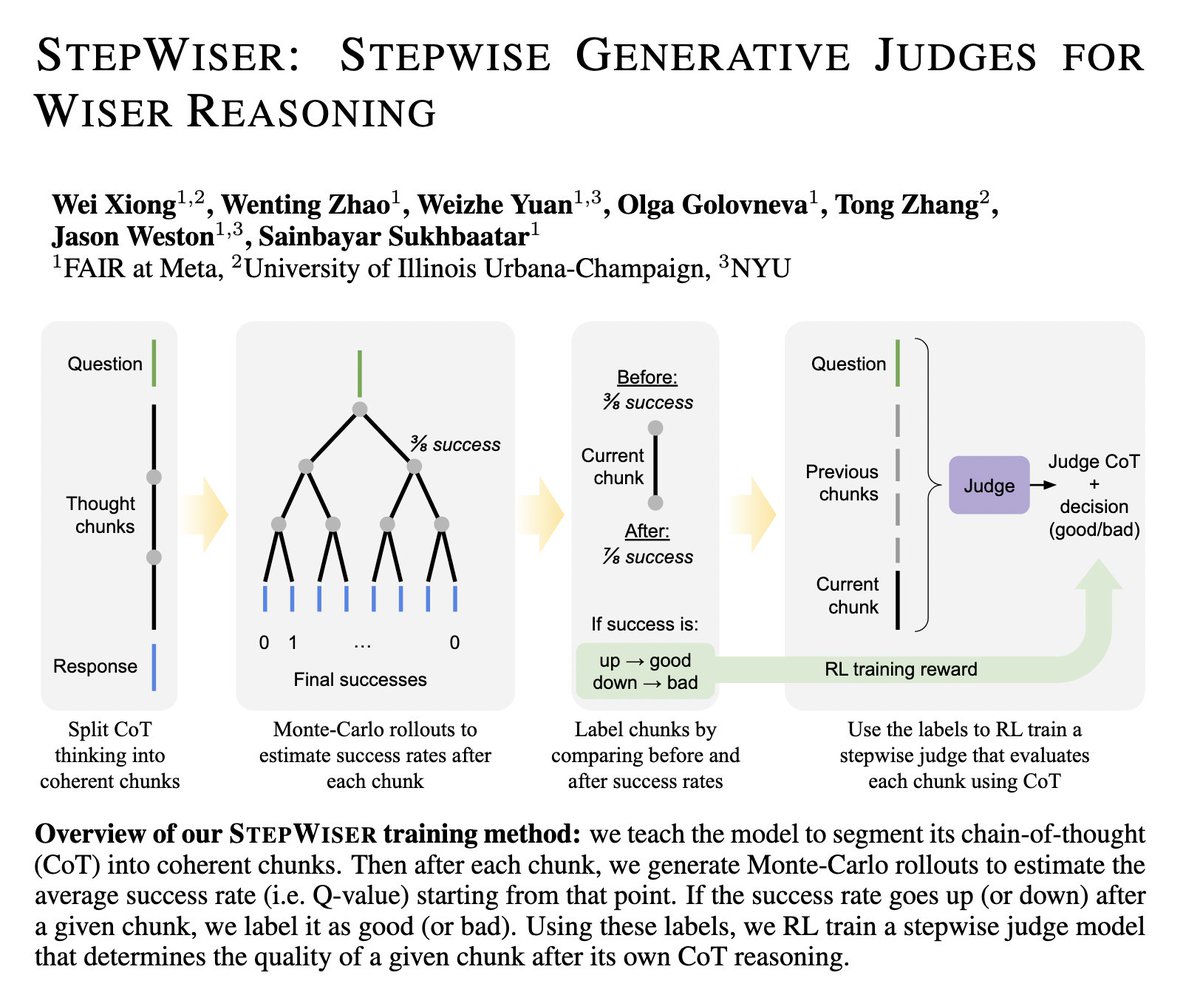
I've always been skeptical about PRMs, but being able to apply RL+reasoning changes the entire story for me. It was a fun ride with @weixiong_1, who has been teaching me a unified view to think about all RL methods. He'll be on the job market! It'd be so lucky to work with him.

I've always been skeptical about PRMs, but being able to apply RL+reasoning changes the entire story for me. It was a fun ride with @weixiong_1, who has been teaching me a unified view to think about all RL methods. He'll be on the job market! It'd be so lucky to work with him.
Being disliked is not a weakness. Needing to be liked is.

🔮 Introducing Prophet Arena — the AI benchmark for general predictive intelligence. That is, can AI truly predict the future by connecting today’s dots? 👉 What makes it special? - It can’t be hacked. Most benchmarks saturate over time, but here models face live, unseen…


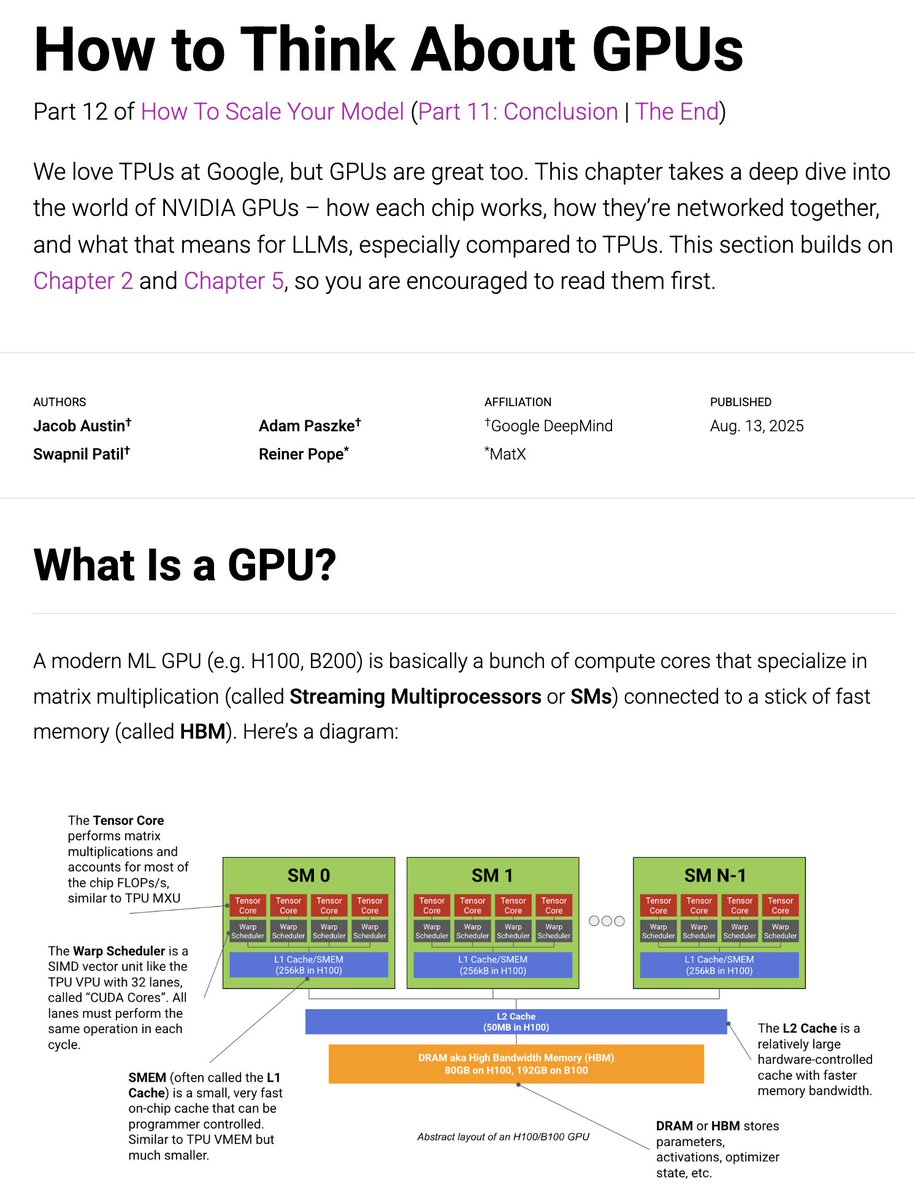
Today we're putting out an update to the JAX TPU book, this time on GPUs. How do GPUs work, especially compared to TPUs? How are they networked? And how does this affect LLM training? 1/n
🚀New dataset release: WildChat-4.8M 4.8M real user-ChatGPT conversations collected from our public chatbots: - 122K from reasoning models (o1-preview, o1-mini): represent real uses in the wild and very costly to collect - 2.5M from GPT-4o 🔗 hf.co/datasets/allen… (1/4)
🚀New dataset release: WildChat-4.8M 4.8M real user-ChatGPT conversations collected from our public chatbots: - 122K from reasoning models (o1-preview, o1-mini): represent real uses in the wild and very costly to collect - 2.5M from GPT-4o 🔗 hf.co/datasets/allen… (1/4)

i've been thinking lately about how future ai systems will interact with us and how we can make systems that care about people and wanted to put words to it -- hopefully it resonates a bit!
i've been thinking lately about how future ai systems will interact with us and how we can make systems that care about people and wanted to put words to it -- hopefully it resonates a bit!
I'll be around the ICML venue this afternoon. Message me if you want to meet! These days, I think about reasoning and RL. Also happy to talk about academia vs. industry (I think the lack of compute in academia is a feature not a bug), faculty and PhD student recruiting at UMass.

haven't made a new blog post in over a year, so here's a new one: justintchiu.com/blog/sftrl/ it's short
AI Research Agents are becoming proficient at machine learning tasks, but how can we help them search the space of candidate solutions and codebases? Read our new paper looking at MLE-Bench: arxiv.org/pdf/2507.02554 #LLM #Agents #MLEBench


📢 today's scaling laws often don't work for predicting downstream task performance. For some pretraining setups, smooth and predictable scaling is the exception, not the rule. a quick read about scaling law fails: 📜arxiv.org/abs/2507.00885 🧵1/5👇


Do language models have algorithmic creativity? To find out, we built AlgoTune, a benchmark challenging agents to optimize 100+ algorithms like gzip compression, AES encryption and PCA. Frontier models struggle, finding only surface-level wins. Lots of headroom here!🧵⬇️


We don’t have AI self-improves yet, and when we do it will be a game-changer. With more wisdom now compared to the GPT-4 days, it's obvious that it will not be a “fast takeoff”, but rather extremely gradual across many years, probably a decade. The first thing to know is that…
Congrats to team! They built my dream benchmark.

Congrats to team! They built my dream benchmark.


✨Release: We upgraded SkyRL into a highly-modular, performant RL framework for training LLMs. We prioritized modularity—easily prototype new algorithms, environments, and training logic with minimal overhead. 🧵👇 Blog: novasky-ai.notion.site/skyrl-v01 Code: github.com/NovaSky-AI/Sky…


Fujun Luan @fujun_luan
324 Followers 319 Following AI researcher @Apple | PhD @Cornell | ex-@Adobe @Meta @Tsinghua_Uni
Bitcoin back @BitcoinBack1
5 Followers 30 Following
Zuobai Zhang @Oxer22
735 Followers 790 Following Research intern @nvidia; Ph.D. student at @Mila_Quebec. Interested in deep generative model, drug discovery and protein science.
Chujie Zheng @ChujieZheng
6K Followers 301 Following Researcher @Alibaba_Qwen | GSPO, Qwen3, QwQ, ProcessBench | Opinions are my own
Zixuan Wang @Vincent__mills
26 Followers 625 Following Incoming PhD, UG @HKUST | “Real learning comes about when the competitive spirit has ceased.”
Jialong Wu @jlwu55
190 Followers 372 Following building native agentic models; now intern @Ali_TongyiLab; WebWalker-WebDancer-WebSailor-WebShaper
Salah in Gaza @salah_shabat
108 Followers 3K Following I swear to God, I swear by the One who made oaths permissible, I have never been a beggar , The war has exhausted us, tired us out and WhatsApp 009702233681
高开元 @hugvgngj
12 Followers 116 Following
cattail @waitaminutec
0 Followers 74 Following "It is the chief characteristic of the religion of science that it works." AI amateur, industrial observer.
ye dongxi @YDongxi
44 Followers 1K Following A data set, data annotation sales, selling high-quality annotation solutions similar to AI for science/autonomous driving/lean4 data topics。
Hieortief @Hieortief37464
41 Followers 2K Following
Thomas Lavery @ThomasL52564058
1 Followers 46 Following
Gaeul @KE3934399331305
2 Followers 120 Following
!.! @xypyth
49 Followers 4K Following

Baiyun Jing @BaiyunJ
75 Followers 603 Following

Linda @battee_linda16
3K Followers 3K Following
Sidharth Baskaran @sidnbaskaran
152 Followers 813 Following
Aldo Battista @aldo_battista
315 Followers 925 Following * Interests: Comp Neuro, ML, and StatPhys * Postdoc in Xiao-Jing Wang's lab, CNS, NYU * Ph.D. in StatPhys from ENS * BS & MS in Phys from Sapienza
Visual-Intelligence @VI_Journal_CSIG
124 Followers 1K Following Official journal of China Society of Image and Graphics (CSIG). The jouarnl is published by Springer, sponsored by CSIG. E-ISSN 2731-9008.
Siddharth @Sid_899
127 Followers 2K Following Trying to be a polymath 🔮 AI + Fin + Bio + Drones + Climate

Brian Chase @brianchaseAI
97 Followers 1K Following
Shuhaib Mehri @ShuhaibMehri
87 Followers 366 Following PhD @siebelschool @ConvAI_UIUC | Previously @IBMResearch @amazon
Swarnadeep Saha @swarnaNLP
2K Followers 826 Following Research Scientist @AIatMeta (FAIR) working on Reasoning. Past: @Google PhD fellow @uncnlp. Gooner.
Lu Wang @LuWang__
2K Followers 297 Following Associate Professor, Computer Science and Engineering, University of Michigan; researcher in natural language processing; directs @launchnlp.
potato jr. @3141abridged
37 Followers 2K Following
Jeff Barg @jeffbarg
2K Followers 3K Following AI @ @clay_gtm • prev https://t.co/LmhUuxxUhq (YC W21) @amazon @pennmandt
Jay @jayvaaty
2 Followers 308 Following
witty carbon @wittycarbon
125 Followers 284 Following Software engineer 👨💻 | IIIT Hyderabad CSE | JEE AIR 379 | Talks about technology and maybe news sometimes | All opinions are of my own |
Sev @Sevrelu
99 Followers 4K Following
Florian Mai @_florianmai
2K Followers 1K Following Junior Research Group Leader @ Uni Bonn AI Alignment & Reasoning


Adi Ganesh @_adiganesh
420 Followers 544 Following Research @openai. Prev. @metaai @nuro @stanford. Co-created @gradientpub

AI PlanetX @AI_PlanetX
9K Followers 3K Following Master AI before it masters you. Best AI & tech Newsletter. Master AI in 9 minutes a week along with 27+ free AI resource.

Tianyi @tianyi5309
3 Followers 528 Following
Andrea Michi @andreamichi
2K Followers 1K Following Co-founder @ https://t.co/FiVtWkCxXC / Building intelligence to detect and remediate software vulnerabilities / Prev post-training / RL for Gemini @GoogleDeepMind
Thomas @Thomas36691688
0 Followers 1K Following
Demyn666 @Demyn666
1 Followers 73 Following
Ali Shafique @alishafique1992
3 Followers 121 Following

ELONMUSKTESLA @elonneurlink
31 Followers 797 Following Live life to the fullest, keep things simple, truthful & filter the noise. I am a long term investor MAGA🚀🇺🇸
DG. @dataghees
1K Followers 6K Following scaling speech native LLMs @rimelabs the future is willed into existence. bioML, discovering new science, housing, industrial policy, local politics.
Switz @jswitz_
71 Followers 2K Following

Tianbao Xie @TianbaoX
3K Followers 2K Following Ph.D. candidate @XLangNLP lab and @hkunlp2020 . Incoming @OpenAI . Advised by @taoyds and @ikekong . 🤝 @Alibaba_Qwen @SFResearch
Weizhe Yuan @WeizheY
342 Followers 297 Following Ph.D. at @nyuniversity. Visiting researcher at @AIatMeta. Previous Intern @cohere, MCDS @LTIatCMU. Working on ML/NLP. Painting lover🎨.
Shuchao Bi @shuchaobi
13K Followers 689 Following Research @Meta Superintelligence Labs, RL/post-training/agents; Previously Research @OpenAI on multimodal and RL; Opinions are my own.
rohan anil @_arohan_
25K Followers 2K Following
You Jiacheng @YouJiacheng
8K Followers 2K Following a big fan of TileLang 关注TileLang喵!关注TileLang谢谢喵! https://t.co/utshC0jrCO 十年老粉
Kevin Lu @_kevinlu
9K Followers 216 Following @thinkymachines. formerly: - @openai: RL, synthetic data, efficient models - @berkeley_ai: decision transformer, universal computation
Yiheng Xu @yihengxu_
1K Followers 706 Following ai agent research @hkuniversity | scaling agent @Alibaba_Qwen | ex @msftresearch @sfresearch | from automation to autonomy
Fan Zhou @FaZhou_998
1K Followers 833 Following PhD Student at SJTU, Qwen Coding @Alibaba_Qwen. Prev: Core member @XLangNLP, Intern @MSFTResearch.
Yuchen Jin @Yuchenj_UW
54K Followers 534 Following Co-founder & CTO @hyperbolic_labs 🧑🍳 fun AI systems. Previously: OctoAI (acquired by @nvidia) building @ApacheTVM, PhD @uwcse 🤖
martin_casado @martin_casado
68K Followers 3K Following GP @ a16z ... questionable heuristics in a grossly underdetermined world
Donglai Xiang @DonglaiXiang
2K Followers 902 Following Research Scientist at Nvidia. Previously Ph.D. from Carnegie Mellon University; visiting researcher at Meta Reality Labs.
Johannes Treutlein @j_treutlein
343 Followers 172 Following AI alignment stress-testing research @AnthropicAI. On leave from my CS PhD at UC Berkeley, @CHAI_Berkeley. Opinions my own.
Umar Jamil @hkproj
15K Followers 1K Following AI @MistralAI - Join the best AI community on Discord: https://t.co/zYH1DlgdbW - Opinions my own
Shengjia Zhao @shengjia_zhao
52K Followers 231 Following Chief Scientist @ Meta MSL. Formerly MTS @ OpenAI, PhD @ Stanford. I train models. All opinions my own.
Sebastian Ruder @ ACL @seb_ruder
92K Followers 1K Following Research Scientist @AIatMeta • Ex @Cohere @GoogleDeepMind
Rohan Pandey @khoomeik
38K Followers 2K Following descending cross-entropy to ascend entropy || prev research @OpenAI @CarnegieMellon '23
Tanay Jaipuria @tanayj
69K Followers 3K Following partner @wing_vc investing in AI applications and infra. opinions, analysis, and banter on technology and business
Jingfeng Wu @uuujingfeng
1K Followers 1K Following Bsky: https://t.co/hUrRPJZ9BU Postdoc @SimonsInstitute @UCBerkeley; alumnus of @JohnsHopkins @PKU1898; DL theory, opt, and stat learning.
Pranjal Aggarwal ✈�... @PranjalAggarw16
471 Followers 107 Following PhD Student @LTIatCMU. research scientist intern @AIatMeta FAIR. Working on reasoning, computer-use agents and test-time compute. Prev @IITD
Tianjian Li @tli104
309 Followers 591 Following PhD student @jhuclsp, research scientist intern @AIatMeta FAIR. I work on data curation for language models. Previously @nyuniversity.
Zhijian Liu @zhijianliu_
2K Followers 822 Following Research Scientist @NVIDIA. Assistant Professor @UCSanDiego. PhD @MIT. Efficient AI. Views are my own. Anonymous Feedback: https://t.co/TsjmnTSiZH

Narutatsu (Edward) Ri @narutatsuri
422 Followers 256 Following PhD Student @PrincetonPLI | BS @Columbia ‘24
Valerie Chen @valeriechen_
2K Followers 514 Following phd student @mldcmu @SCSatCMU + intern @allhands_ai | building @CopilotArena | previously @NYUDataScience @MSFTResearch @yale @CMU_Robotics @IBMResearch


Mike A. Merrill @Mike_A_Merrill
596 Followers 300 Following Postdoc @StanfordAILab Building https://t.co/KWJvsMlWva - the best framework for evaluating agents in the terminal Go Bills
Nishant Subramani @nsubramani23
778 Followers 2K Following PhD student @LTIatCMU working on model interpretability; student researcher @google // Prev: intern @msftresearch, predoc @allen_ai // @BVB supporter // he/him

Jascha Sohl-Dickstein @jaschasd
24K Followers 706 Following Member of the technical staff @ Anthropic. Most (in)famous for inventing diffusion models. AI + physics + neuroscience + dynamics.
Sebastian Raschka @rasbt
354K Followers 1K Following ML/AI researcher & former stats professor turned LLM research engineer. Author of "Build a Large Language Model From Scratch" (https://t.co/O8LAAMRzzW).
Yoram Bachrach @yorambac
3K Followers 7K Following Research Scientist at Meta (prev Google DeepMind and Microsoft Research). Working on LLM Agents and Multi-Agent Systems.
Alexander Doria @Dorialexander
19K Followers 4K Following Reasoning models to come. Co-founder @pleiasfr
OpenAI @OpenAI
4.3M Followers 3 Following OpenAI’s mission is to ensure that artificial general intelligence benefits all of humanity. We’re hiring: https://t.co/dJGr6Lg202
SSI Inc. @ssi
102K Followers 0 Following A straight shot to safe superintelligence. Join us https://t.co/hHla3vusDE.

Trapit Bansal @TrapitBansal
32K Followers 247 Following AI Research @Meta | Co-Creator of OpenAI o1 | Previously @OpenAI, @MSFTResearch, @GoogleAI, @facebook, @iiscbangalore, and undergrad @IITKanpur
tamara @tamarajtran
10K Followers 352 Following Exploring human-computer interaction at scale. Built 3x #1 apps. Prev @DukeU
Wei Xiong @weixiong_1
1K Followers 540 Following Statistical learning theory, Post-training of LLMs, RAFT, LMFlow, GSHF, and RLHFlow. PhD Student @IllinoisCS, current @GoogleDeepMind, prev @MSFTResearch @USTC
Swarnadeep Saha @swarnaNLP
2K Followers 826 Following Research Scientist @AIatMeta (FAIR) working on Reasoning. Past: @Google PhD fellow @uncnlp. Gooner.
Run-Ze Fan @Vfrz525_
1K Followers 2K Following CS PhD student @UMassAmherst. | Prev RA@GAIR Lab @sjtu1896, MS @ucas1978
Zengzhi Wang @SinclairWang1
2K Followers 3K Following PhDing @sjtu1896 #NLProc Working on Data Engineering for LLMs: MathPile (2023), 🫐 ProX (2024), 💎 MegaMath (2025),🐙 OctoThinker(2025)
Lucas Beyer (bl16) @giffmana
108K Followers 519 Following Researcher (now: Meta. ex: OpenAI, DeepMind, Brain, RWTH Aachen), Gamer, Hacker, Belgian. Anon feedback: https://t.co/xe2XUqkKit ✗DMs → email
Ulyana Piterbarg @ulyanapiterbarg
685 Followers 595 Following reasoning, agents, + open-endedness | PhDing at @nyuniversity and @AIatMeta, prev @MIT
Laude Institute @LaudeInstitute
2K Followers 29 Following Laude Institute backs computer science researchers turning research into real-world impact. // @LaudeVentures
Elias Stengel-Eskin @EliasEskin
2K Followers 1K Following NLP + AI assistant prof. @UTAustin CS, postdoc @uncnlp w/ @mohitban47, PhD @jhuclsp, @NSF grad fellow. Building communicative+collaborative AI.
Taco Cohen @TacoCohen
27K Followers 3K Following Post-trainologer at FAIR. Into codegen, RL, equivariance, generative models. Spent time at Qualcomm, Scyfer (acquired), UvA, Deepmind, OpenAI.
Brian Huang @brianryhuang
4K Followers 2K Following code capabilities @GoogleDeepmind, prev windsurf, mit madrylab
Seungone Kim @seungonekim
2K Followers 935 Following Ph.D. student @LTIatCMU and intern at @AIatMeta (FAIR) working on (V)LM Evaluation & Systems that SeIf-Improve | Prev: @kaist_ai @yonsei_u
Yoon Kim @yoonrkim
445 Followers 539 FollowingTrends for United States
You might like












