
🚀 Introducing EpiCoder: a hierarchical feature tree-based framework for diverse and intricate code generation. 🔍 Outperforming benchmarks, it handles everything from simple functions to multi-file projects deftly. 📢 Open source release soon! 🔗 arxiv.org/abs/2501.04694




@TeamCodeLLM_AI Please release the dataset and code too? Love you! 💖

@TeamCodeLLM_AI 6/6: 🧐Definitions from software engineering principles and the LLM-as-a-judge methodology were employed to evaluate the complexity of the data. 🔍In addition, we constructed feature trees to assess data diversity to highlight the advantages of our approach.
@TeamCodeLLM_AI 📢 Get ready for open source! Stay tuned for updates.💻
@TeamCodeLLM_AI 5/6:🌟We pushed the limit by generating complex real-world code repositories using feature trees from popular open-source GitHub projects, like LLaMA-Factory, creating a repository with over 50 files. 🏗️Paving the way for future research in repository-level code synthesis.

@TeamCodeLLM_AI 4/6: 🌟Our synthesis framework scales efficiently from function-level to file-level by adjusting tree depth and width, integrating extensive feature info for sophisticated file-level code. 🔥Example and XFileDep benchmark show sophisticated file-level code and performance.


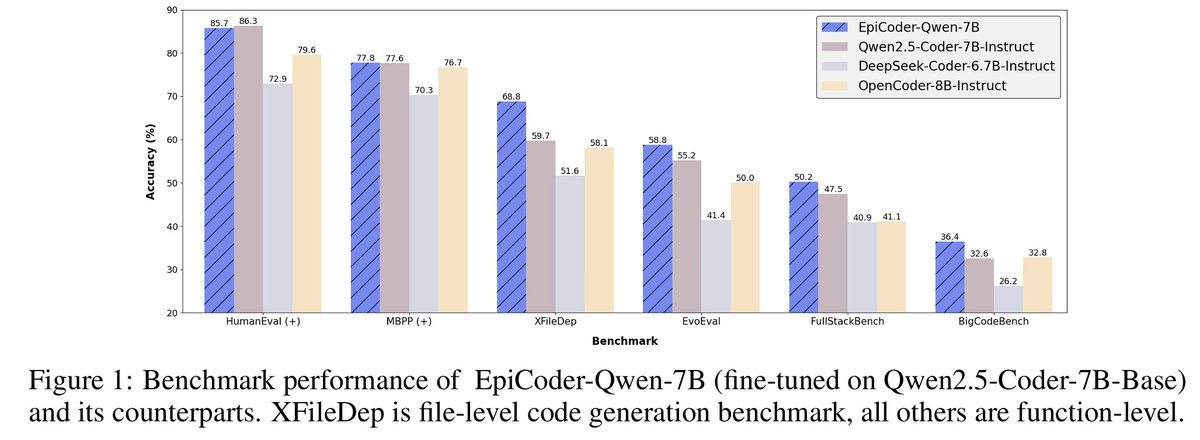
@TeamCodeLLM_AI 3/6:🔥Top Performing EpiCoder-Qwen-7B! 🚀Achieving SOTA average performance in function-level benchmarks. Covers areas like basic programming (HumanEval, MBPP), specific task domains (EvoEval), realistic scenarios (BidCodeBench), and full-stack capabilities (FullStackBench).




@TeamCodeLLM_AI 2/6:🌳Our feature tree-based synthesis, inspired by AST, captures code's semantic relationships. 🔍Hierarchical clustering and feature expansion ensure comprehensive real-world coverage. 🔝Advantages: Scalable Complexity & Targeted Learning for balanced and efficient training.

@TeamCodeLLM_AI 1/6: 🔍Optimizing Code LLMs! 🎯 Effective instruction tuning aligns LLMs with user needs and boosts performance. 📈 Current methods limit complexity and diversity, failing to capture real-world programming intricacies. Highlighting the need for more flexible code data synthesis.