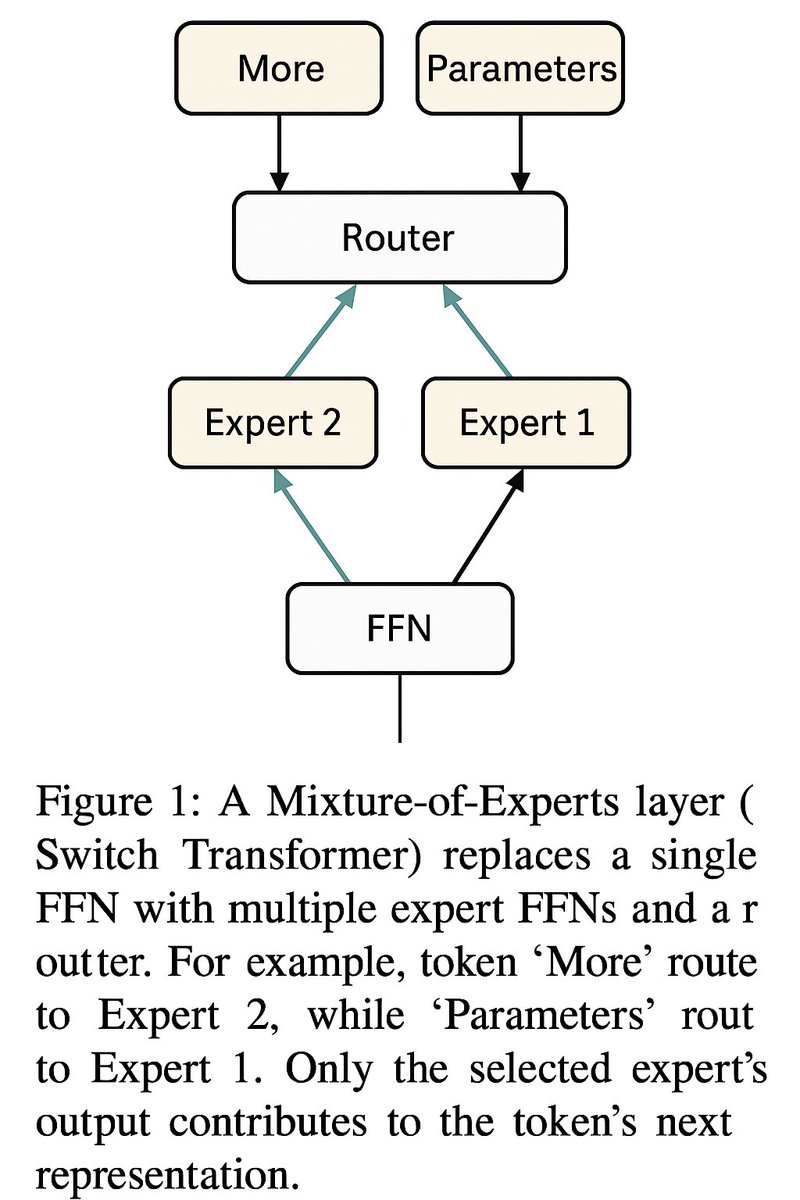
**Mixture-of-Experts (MoE) Architecture: Basics and Motivation and how GPT 5 implements it** **What are MoEs?** In a Mixture-of-Experts model, the dense subnetwork (typically the feed-forward network in a Transformer layer) is replaced by multiple parallel “expert” networks with identical structures (e.g., multiple FFNs). A router (gating network) selects a sparse subset of experts for each input token, activating only their parameters. This maintains compute efficiency similar to a smaller dense model while boosting capacity (e.g., for factual knowledge) without proportional inference slowdown. **Why use MoEs?** MoEs scale efficiently, achieving lower loss or perplexity than dense models at a fixed FLOP budget. Adding experts (while keeping per-token compute constant) speeds training and improves accuracy on language tasks. For example, an MoE model with many experts reached target perplexity ~7× faster than a dense model with the same compute. At inference, only a fraction of parameters (e.g., ~5B of 117B in GPT-OSS-120B) are active per token, matching the speed of a smaller model while retaining large-model knowledge. **How do MoEs work?** In each MoE layer, the router assigns a token to K experts (typically K=1 or 2) via a probability score (e.g., softmax over experts). Only selected experts process the token, and their outputs are combined (often a weighted sum) for the layer’s output. Figure 1 shows a Transformer layer with an MoE: the router selects one of four expert FFNs per token, activating only that expert’s parameters. **Figure 1:** A Mixture-of-Experts layer (Switch Transformer) replaces a single FFN with multiple expert FFNs and a router. For example, token “More” routes to Expert 2, while “Parameters” routes to Expert 1. Only the selected expert’s output contributes to the token’s next representation. The router, typically a single-layer linear projection, computes scores via a dot product between the token’s hidden state and each expert’s router weight vector. A softmax yields affinity scores, and Top-K selection picks the highest-scoring experts. Their outputs are scaled by these scores and summed, ensuring compute efficiency through sparse gating (e.g., 2 of 100 experts). **Benefits and trade-offs:** MoEs increase model capacity by adding experts without raising per-token computation, improving performance on knowledge-intensive tasks. They enable expert parallelism, distributing tokens across devices. However, discrete routing complicates training, risking load imbalance where some experts dominate. Training requires load-balancing strategies (e.g., loss terms or constraints). MoEs also demand more memory and complex infrastructure for sharding experts across machines. **GPT-5’s MoE Architecture and Router Mechanism** **GPT-5’s use of MoE:** GPT-5 uses a hierarchical MoE system with multiple expert subsystems coordinated by a top-level router. A “fast” expert (gpt-5-main) handles most queries with low latency, while a “deep reasoning” expert (gpt-5-thinking) tackles complex tasks. The router dynamically assigns queries based on context, complexity, or user instructions, ensuring efficient compute allocation. **GPT-5’s router behavior:** The router uses signals like conversation context or explicit instructions (e.g., “think step by step”) to select the appropriate expert. Simple queries go to gpt-5-main, while complex ones invoke gpt-5-thinking, which may use chain-of-thought reasoning. Trained on real usage data, the router adapts via online reinforcement learning, optimizing expert selection. **Sparse activation in GPT-5:** Both gpt-5-main and gpt-5-thinking are MoE-based Transformers, routing tokens to a subset of feed-forward experts per layer. Only a fraction of parameters (e.g., ~5.1B of 117B) are active per token, achieving high sparsity (20× or more), reducing computation and energy use while maintaining vast capacity. **Expert selection logic in GPT-5:** Each MoE layer uses Top-K routing (likely K=2). The router computes affinity scores via a linear projection of the token’s hidden state, applies softmax, and selects the top experts. Their outputs are combined (typically a weighted sum) and passed to the next layer. Unselected experts remain inactive, enabling sparse computation. **Pseudocode for an MoE layer:** 1. Compute gating scores: For token hidden state \( h \), compute \( z_i = w_i \cdot h \) per expert \( i \). 2. Select top experts: Pick indices of the top-K scores in \( z \) (e.g., K=2 of 64 experts). 3. Compute expert outputs: Feed \( h \) to each selected expert’s FFN to get \( y_{i_j} = \text{Expert}_{i_j}(h) \). 4. Combine outputs: Compute softmax over top-K logits to get probabilities \( p_{i_j} \), then sum \( y_{\text{MoE}} = \sum_{j=1}^K p_{i_j} \cdot y_{i_j} \). 5. Output: Return \( y_{\text{MoE}} \) for the next layer. **Load balancing and sparsity in GPT-5:** To prevent expert imbalance, GPT-5 uses an auxiliary load-balancing loss (e.g., dot product of token fraction \( F \) and router probabilities \( P \)) to distribute tokens evenly. It may also impose expert capacity limits or use learned bias factors to adjust routing probabilities dynamically. Stabilization techniques, like router z-loss and high-precision gating, ensure training stability. **GPT-5’s Router vs. Switch Transformer and GShard** **GShard (2020):** Used Top-2 routing with a balancing loss and capacity limits. GPT-5 inherits this framework but operates at a larger scale with refined techniques (e.g., learned bias factors). Unlike GShard’s single-model focus, GPT-5’s hierarchical MoE routes between distinct model types. **Switch Transformer (2021/22):** Simplified to Top-1 routing for efficiency, introducing a balancing loss and z-loss. GPT-5 adopts this approach but reintroduces multi-expert routing (K>1) and hierarchical routing across models, trained with user feedback for real-time adaptation. **Summary of innovations:** GPT-5 extends Switch Transformer’s Top-K routing with hierarchical model-level routing, continuous feedback training, and advanced load-balancing (e.g., bias factors). It maintains sparse activation for efficiency while scaling to unprecedented capacity, unifying multiple experts into an adaptive, high-performing system.