
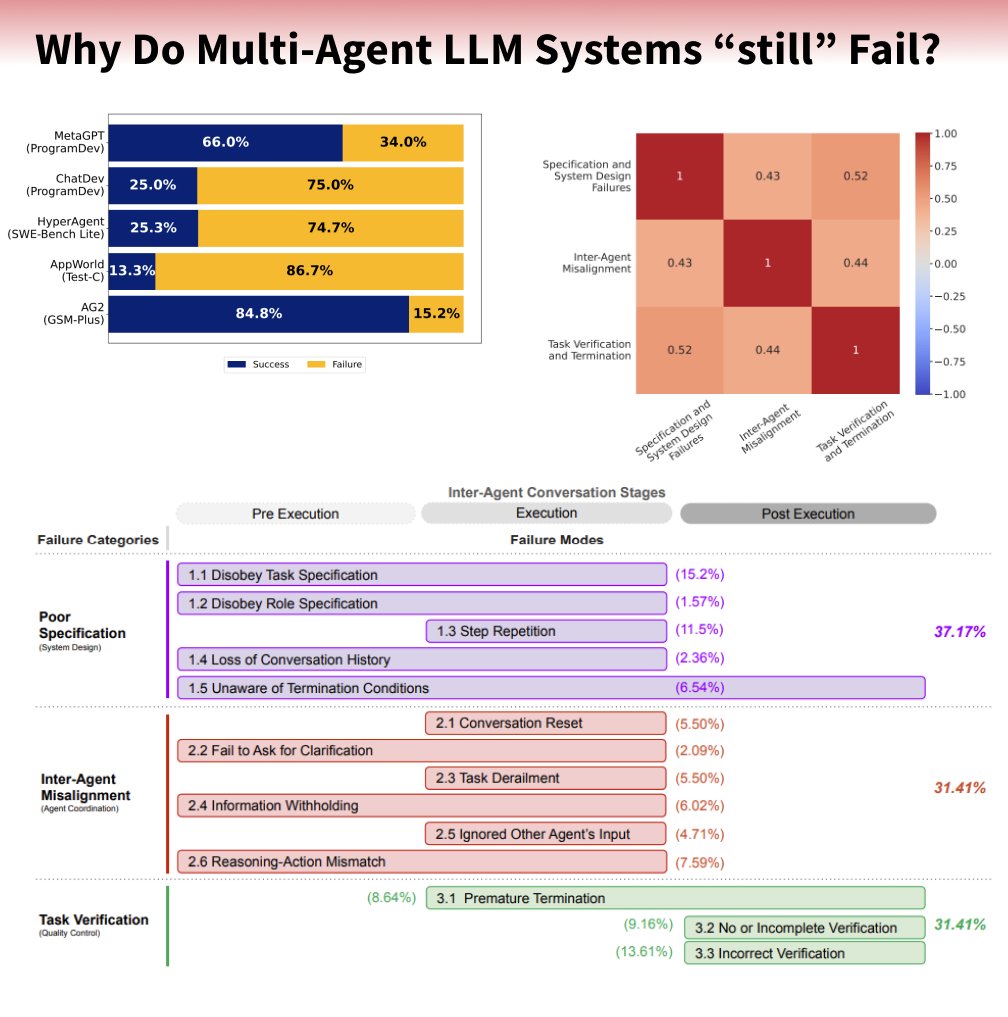
Why Do Multi-Agent LLM Systems “still” Fail? A new study explores why Multi Agent Systems are not significantly outperforming single-agent. The study identifies 14 failure modes multi-agent system. Multi-agent system (MAS) are agents that interact, communicate, and collaborate to achieve a shared goal, which would to be difficult or unreliable for a single agent to accomplish. Benchmark: - Selected five popular, open-source MAS (MetaGPT, ChatDev, HyperAgent, AppWorld, AG2) - Chose tasks representative of the MAS intended capabilities (Software Development, SWE-Bench Lite, Utility Service Tasks, GSM-Plus) total of 150 tasks - Recorded the complete conversation logs, human annotators reviews, Cohen's Kappa score to ensure consistency and reliability, LLM-as-a-Judge Validation Multi Agent Failure modes: 1. Disobey Task Spec: Ignores task rules and requirements, leading to wrong output. 2. Disobey Role Spec: Agent acts outside its defined role and responsibilities. 3. Step Repetition: Unnecessarily repeats steps already completed, causing delays. 4. Loss of History: Forgets previous conversation context, causing incoherence. 5. Unaware Stop: Fails to recognize task completion, continues unnecessarily. 6. Conversation Reset: Dialogue unexpectedly restarts, losing context and progress. 7. Fail Clarify: Does not ask for needed information when unclear. 8. Task Derailment: Gradually drifts away from the intended task objective. 9. Withholding Info: Agent does not share important, relevant information. 10. Ignore Input: Disregards or insufficiently considers input from others. 11. Reasoning Mismatch: Actions do not logically follow from stated reasoning. 12. Premature Stop: Ends task too early before completion or information exchange. 13. No Verification: Lacks mechanisms to check or confirm task outcomes. 14. Incorrect Verification: Verification process is flawed, misses critical errors. How to improve Multi-Agent LLM System: - 📝 Define tasks and agent roles clearly and explicitly in prompts. - 🎯 Use examples in prompts to clarify expected task and role behavior. - 🗣️ Design structured conversation flows to guide agent interactions. - ✅ Implement self-verification steps in prompts for agents to check their reasoning. - 🧩 Design modular agents with specific, well-defined roles for simpler debugging. - 🔄 Redesign topology to incorporate verification roles and iterative refinement processes. - 🤝 Implement cross-verification mechanisms for agents to validate each other. - ❓ Design agents to proactively ask for clarification when needed. - 📜 Define structured conversation patterns and termination conditions.

@_philschmid Amazing insights 🙏Question; “Implement self-verification steps in prompts for agents to check their reasoning.” There are a few prompt methods that leap to mind: ReAct, Reflexion, Language Agent Tree Search: does this insight mean employing one of these or similar? Or…?

@_philschmid We might be training these systems, but they still have a long way to go.

@_philschmid Most people misunderstand multi-agent systems. From my experience building them, they're best viewed as tools to discover optimal processes or SOPs. Once identified, store and reuse these processes directly—no need to rerun agents each time.

@_philschmid Now we need 14 more agents in the system checking for these failures.

@_philschmid @_philschmid curious on the cross validation approach, seems like having a human expert in the loop (instead of a LLM) (in)validating intermediate results could steer the pipeline into a much better direction by pruning invalid "reasoning" early to collect training data

Super insightful study 👏 Many of these failure modes boil down to poor orchestration + brittle memory. At @oblixai, we’ve seen success by combining: 🔁 Agentic context management 🧠 Dynamic memory routing ⚡ Real-time model switching (local/cloud) Multi-agent systems don’t just need more agents—they need smarter infrastructure. #MultiAgentLLM #AIOrchestration #OblixAI #AgenticAI

@_philschmid All these mechanism should be implemented by training and proper prompt, not structure and static workflow

Appreciate the breakdown—these stepwise failure patterns match everything I’ve seen in live agent deployments. Especially loss of history and task derailment. It’s wild how much progress comes from just nailing basic role/termination discipline rather than chasing the next headline feature.

Even with well-crafted problem statements and instructions, getting a single agent to follow them consistently and accurately is already challenging. Hallucinations and abrupt halts still occur. Coordinating multiple agents only adds complexity, especially without a clear orchestrator.

@_philschmid Question is what is fail that scientific benchmarking is not necessarily failing. I'm using LLM locally on my computer and all I can say I am successful in many ways and activities. Even this I am typing by using speech to transcription NVIDIA Canary-1B model.