
The wait is over! As the leading AI code review tool, CodeRabbit was given early access to OpenAI's GPT-5 model to evaluate the LLM's ability to reason through and find errors in complex codebases! Our evals found GPT-5 performed up to 190% better than other leading models!
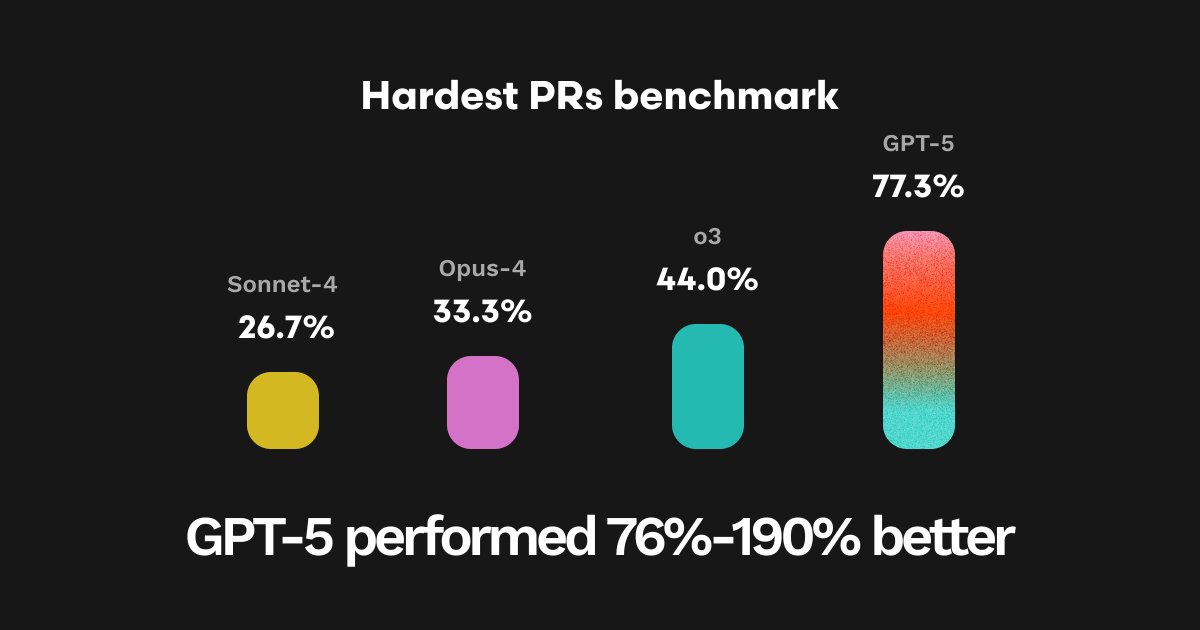
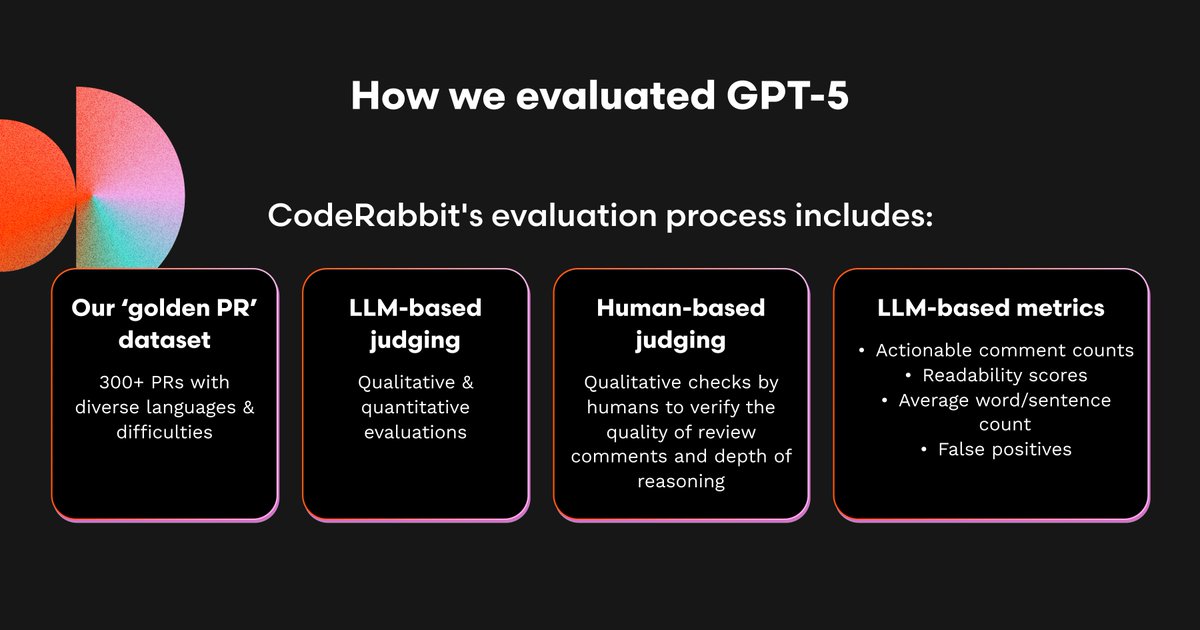
As part of our GPT-5 testing, we conducted extensive evals to uncover the model’s technical nuances, capabilities, and use cases around common code review tasks using over 300 carefully selected PRs.





@coderabbitai So, 🐰 is about to roast my PRs more than ever with GPT-5 in the sweetest way possible, huh?

@coderabbitai Will this be turned on by default for reviews?

@coderabbitai is this better than Claude? One subscription would be nice.

@coderabbitai No comparison with grok 4 👀

@coderabbitai we are waiting for this to roll out

@coderabbitai How did the comparison stand with opus 4.1 and grok 4? Those are the leading models from competitors and they should present in comparison.

@coderabbitai at least some companies know how to make charts lmao



@coderabbitai thats insane, coderabbit about to make sure the tea doesn't get spilt again?

@coderabbitai Seeing GPT-5’s reasoning boost makes me wonder—how will this impact the pace of catching subtle bugs that often slip through tests? 🤔 Would love to see some real-world debugging examples from CodeRabbit!

@coderabbitai I wish, the evaluation code is publicly avaliable. So, other labs can do validation.

@coderabbitai What about the smaller models like gpt5 if it is on sonnet 4 level that would be a massive price advantage.

@coderabbitai sounds like some solid testing there. if those numbers hold up, that could change the game for code reviews. curious to see how it holds up in real-world scenarios.

A first you don’t want to miss! Zikigai Gardens’ exclusive debut release, ZPie, is live only at Neptune! Be part of the very first chapter in Zikigai Gardens history!