Search results for #30daysofMachineLearning

Day 4 of #30DaysOfMachineLearning 🚀 • OOP PyTorch: Dataset, DataLoader, Model • Optimizers + Training Loop • Model evaluation metrics Gaining confidence in building robust deep learning 🔗 github.com/Bishal-Stha/Py… #PyTorch #DeepLearning @OpenAI @huggingface #LearnInPublic

Starting a #30DaysOfMachineLearning challenge today 💪 Here's a Kaggle notebook I threw together with the Fast AI library -> kaggle.com/code/joemuller…

Kernel bandwidth in Kernel Density Estimation - balancing detail and smoothness. Smaller bandwidth - more variability but may overfit Larger one - smoother estimates but can oversmooth. 🔧Cross-validation & Silverman's rule aid bias-variance trade-off. #30daysofMachineLearning
Nonparametric Density Estimation - a powerful statistical tool for estimating probability density functions without assuming specific distributions. Kernel Density Estimation, Histogram methods help unveil complex data patterns (informed decision-making). #30daysofMachineLearning
📈Evaluating grouping of data points within clusters & separated across clusters is key in assessing clustering quality. Fowlkes-Mallows index, quantify effectiveness of clustering by examining relationships in data points based on clustering assignments. #30daysofMachineLearning
📊Pairwise measures in clustering evaluation analyze similarity of cluster assignments by comparing pairs of data points within and across clusters. Metrics, Jaccard coeff. & Rand index, offer insights between clustering outcomes & ground truth labels. #30daysofMachineLearning
Mutual Information in clustering evaluation assesses the dependency between observed and expected joint probabilities of clusters and ground truth. #ClusteringEvaluation #30daysofMachineLearning
📊 Conditional Entropy in clustering evaluation measures the cluster-specific entropy, revealing how ground truth is distributed within each cluster. #ClusteringEvaluation #DataAnalysis #30daysofMachineLearning
📊 Maximum Matching in clustering evaluation ensures one cluster is matched to one partition, maximizing purity under the one-to-one matching constraint. It is essential for assessing clustering performance effectively. #ClusteringEvaluation #30daysofMachineLearning
📊 Purity in clustering quantifies the extent to which a cluster contains points exclusively from one ground truth partition. It is a crucial measure for evaluating the quality of clustering results accurately. #ClusteringEvaluation #DataAnalysis #30daysofMachineLearning
🤖 Exploring clustering evaluation in #30daysofMachineLearning! Did you know there are two main categories of measures? External measures rely on external ground-truth, while internal measures derive goodness from the data itself. 💡
The Davies-Bouldin Index is critical in cluster evaluation, it captures trade-off between cluster compactness & separation. A lower index value : more cohesive and well-separated clusters, showcasing its significance in optimizing clustering algorithms. #30daysofMachineLearning
Epsilon (eps) plays a pivotal role in density-based clustering, the Elbow effect shedding light on its impact. 🔧 Manipulating epsilon values, we can observe clusters merging or outliers emerging, offering valuable insights into data patterns. #30daysofMachineLearning
A cluster in density-based clustering revolves around density-connected points forming dense regions. Identifying maximal sets of points with density-reachable relationships, we pinpoint clusters amidst varying densities -> precise clustering analysis. #30daysofMachineLearning
Direct density reachability in DBSCAN highlights the direct connection between core objects, essential for clustering and outlier detection. The path of direct density reachability, unveils intricate relationships within dense regions in the data space. #30daysofMachineLearning
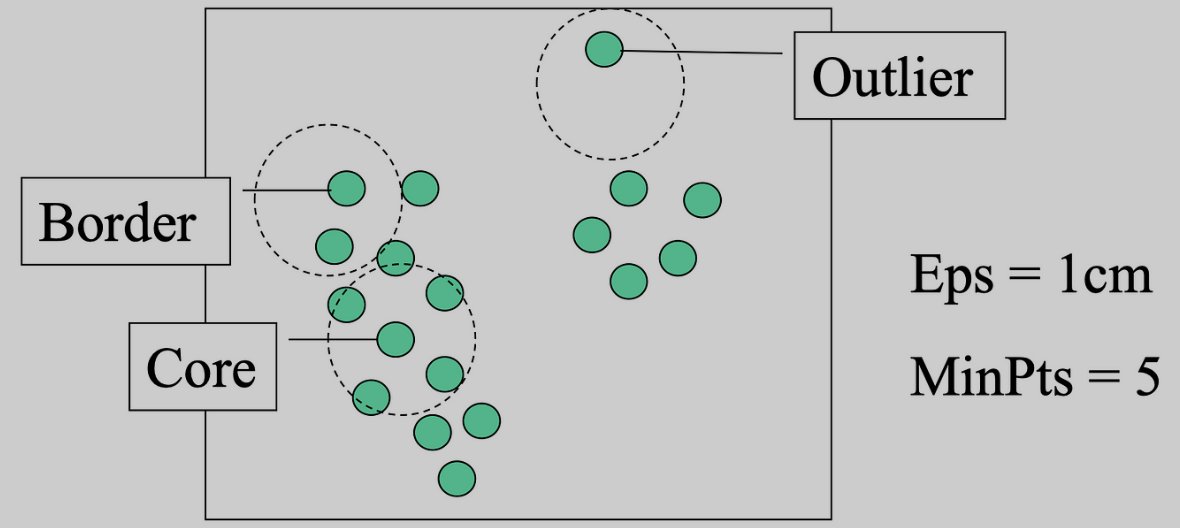
Epsilon and minPts are the dynamic duo in density-based clustering algorithms like DBSCAN. 🪩Epsilon controls the reachability distance, 🪩minPts determines the density threshold for defining clusters. These parameters enable accurate clustering. #30daysofMachineLearning
Understanding core points, border points, and outliers is crucial in density-based clustering like DBSCAN. Core points form the heart of clusters, while border points lie on the edges, and outliers stand alone. #30daysofMachineLearning
Delve into the world of Beta-CV in #MachineLearning during #30daysofMachineLearning! 🌟 This measure evaluates the quality of clustering by analyzing intra-cluster and inter-cluster edges, providing valuable insights into the cohesion and separation of data points. 🧩
Bottom-up agglomerative clustering is a powerful technique in #MachineLearning that begins with each object as a separate cluster and iteratively combines the closest pairs. 🤖 Witness how this method uncovers relationships and groupings in your data! 📊 #30daysofMachineLearning
Unveil the power of clustering evaluation in #30daysofMachineLearning! 🌐 Explore metrics like Rand Index and Fowlkes-Mallows Index to quantify the similarity between true and predicted clusters, enabling you to fine-tune your algorithms for better results. 📊