Search results for #DistributedTraining

⚡️ As AI model parameters reach into the billions, Bittensor's infrastructure supports scalable, decentralized training—making artificial general intelligence more attainable through global, collaborative efforts rather than isolated labs. #AGI #DistributedTraining

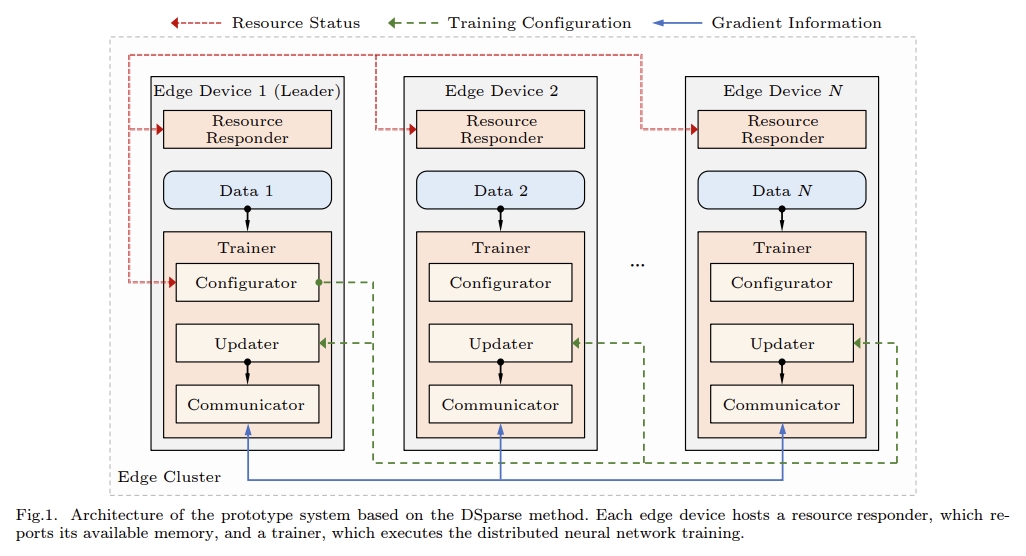
DSparse: A Distributed Training Method for Edge Clusters Based on Sparse Update jcst.ict.ac.cn/article/doi/10… #DistributedTraining #EdgeComputing #MachineLearning #SparseUpdate #EdgeCluster #Institute_of_Computing_Technology @CAS__Science @UCAS1978

Distributed Training: Train massive AI models without massive bills! Akash Network's decentralized GPU marketplace cuts costs by up to 10x vs traditional clouds. Freedom from vendor lock-in included 😉 #MachineLearning #DistributedTraining #CostSavings $AKT $SPICE

12/20Learn distributed training frameworks: Horovod, PyTorch Distributed, TensorFlow MultiWorkerStrategy. Single-GPU training won't cut it for enterprise models. Model parallelism + data parallelism knowledge is essential. #DistributedTraining #PyTorch #TensorFlow
12/20Learn distributed training frameworks: Horovod, PyTorch Distributed, TensorFlow MultiWorkerStrategy. Single-GPU training won't cut it for enterprise models. Model parallelism + data parallelism knowledge is essential. #DistributedTraining #PyTorch #TensorFlow
7/20Learn distributed training early. Even "small" LLMs need multiple GPUs. Master PyTorch DDP, gradient accumulation, and mixed precision training. These skills separate hobbyists from professionals. #DistributedTraining #Scaling #GPU

Distributed Training in ICCLOUD's Layer 2 with Horovod + Mixed - Precision. Cuts training costs by 40%. Cost - effective training! #DistributedTraining #CostSaving


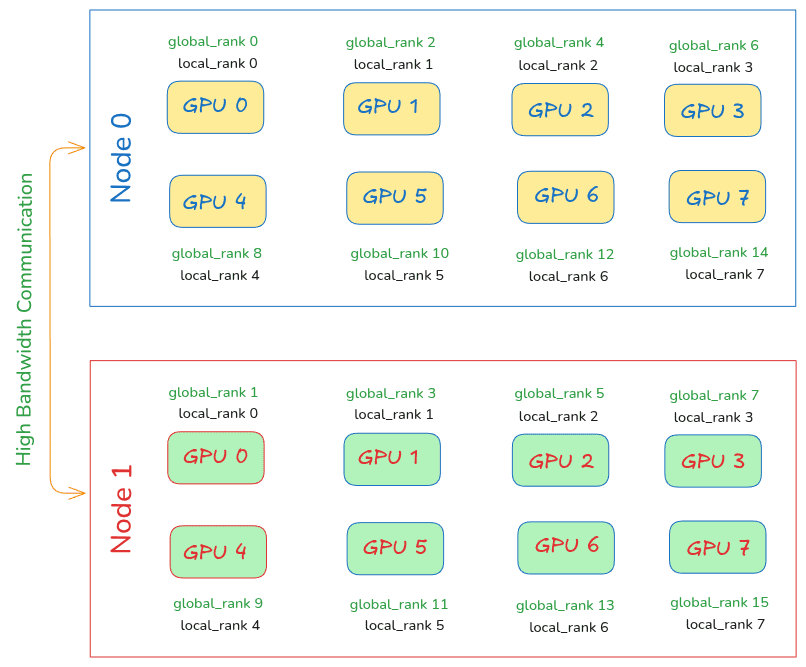
Distributed Data Parallel - Multi Node GPU setup #pytorch #gpu #multiGPU #DDP #DistributedTraining

Took our model training time from 56 hours to 5.6 hours—10x speedup! Thanks to Torch's DDP and NVIDIA's NCCL. 🥵 Distributed training is a game-changer. Big opportunities ahead iA. 🤑 #DeepLearning #PyTorch #NVIDIA #AI #DistributedTraining

$TAO UPDATE 5.7.25 Top traded subnets: SN 14 #taohash SN 5 #openkaito SN 56 #gradients SN 64 #chutes Top subnet gainers: SN 28 #oracle SN 38 #distributedtraining SN 74 SN 54 #webgenieai

$TAO UPDATE 5.6.25 Top traded subnets: SN 14 #taohash SN 56 #gradients SN 5 #openkaito SN 50 #synth Top subnet gainers: SN 50 #synth SN 38 #distributedtraining SN 27 #NICompute SN 80 #AIfactory


🔹 #AutonomousResourceOrchestration via #HyperdOS #HyperbolicLabs’ #HyperdOS enables AI agents to orchestrate #GPU resources across a global network. Agents dynamically allocate compute for #MLInference or #DistributedTraining, optimizing #Throughput and #NetworkLatency.…

. @soon_svm #SOONISTHEREDPILL Soon_svm's distributed training enables handling of extremely large datasets. #DistributedTraining

Just published my blog on Pipeline Parallelism fundamentals! Learn how it works. Check it out: medium.com/@bargav25/dist… Feedback welcome! More deep learning content coming soon. #MachineLearning #LLMs #DistributedTraining

Elevate your #ML projects with our AI Studio’s Training Jobs—designed for seamless scalability and real-time monitoring. Support for popular frameworks like PyTorch, TensorFlow, and MPI ensures effortless #distributedtraining. Key features include: ✨ Distributed Training: Run…


Train large language models in a shared and sustainable way? Join #Bittensor subnet 38 #DistributedTraining and start mining #Tao.

Implement data parallelism to distribute the workload across multiple GPUs! 🎛️ By splitting your dataset and performing parallel computations, you can reduce training time, especially for large-scale models. #DataParallelism #DistributedTraining (4/7)

✅ Achievement Unlocked! Efficient #DistributedTraining of DeepSeek-R1 671B is now a reality on #openEuler 24.03! 💙 Dive in and see what this #TechCP, openEuler + #DeepSeek, bring to the table 👉linkedin.com/pulse/deepseek… #opensource #ValentinesDay2025 #ValentinesDay #openEulerBuzz

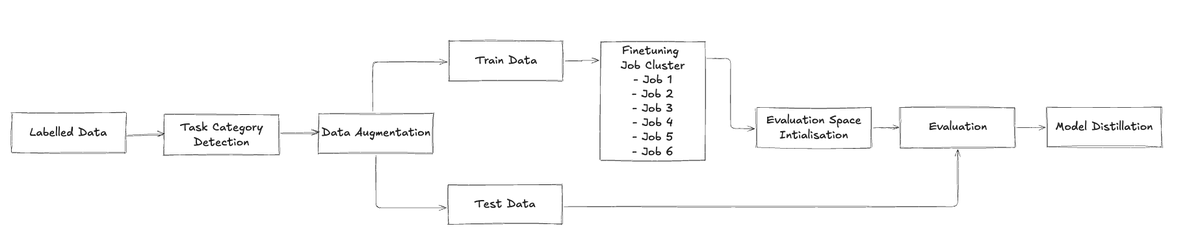
System Architecture Overview The system has two subsystems: • Data Processing – Manages data acquisition, enhancement, and quality checks. • #DistributedTraining – Oversees parallel fine-tuning, resource allocation, and evaluation. This division allows independent scaling,…
✅ Achievement Unlocked! Efficient #distributedtraining of #DeepSeek-R1:671B is realized on #openEuler 24.03! Built for the future of #AI, openEuler empowers #developers to push the boundaries of innovation. 🐋Full technical deep dive coming soon! @deepseek_ai #opensource #LLM
