
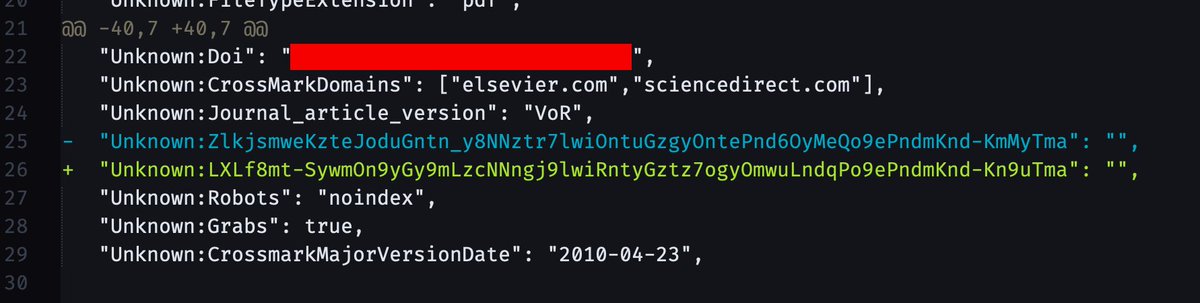
More fun publisher surveillance: Elsevier embeds a hash in the PDF metadata that is *unique for each time a PDF is downloaded*, this is a diff between metadata from two of the same paper. Combined with access timestamps, they can uniquely identify the source of any shared PDFs.
You can see for yourself using exiftool. To remove all of the top-level metadata, you can use exiftool and qpdf: exiftool -all:all= <path.pdf> -o <output1.pdf> qpdf --linearize <output1.pdf> <output2.pdf> To remove *all* metadata, you can use dangerzone or mat2

@json_dirs @naturepoker1 You're doing the lord's work, Jonny.

@json_dirs It's entertaining that the big E thinks that someone who can write sci hub won't be able to scrub metadata

@json_dirs What are the odds that people inserting nonces into PDF metadata are also inserting invisible image watermarks that survive conversion?


@json_dirs There is a @zotero pdf cleaning plug-in begging to be made here.

@json_dirs Lol I'm going to go through my Zotero library, extract all of these, and add then to my fat GDPR request for Elsevier

@json_dirs I wonder how smart their DMCA takedown logic is. If you construct a new pdf with different content but that same hash, will their system still issue the paperwork?

@json_dirs Reminds me of a writeup I seen once of how social media sites like Facebook track who downloaded and shared and image, who uploaded it, etc. There was a special identifier Facebook adds to the processing of the image to track each of those actions and link it all back.

@json_dirs The academic publishing system is actively harming scientific and medical progress. It's pure evil. Prestige journals need to go, publish-or-perish needs to go.

@json_dirs This is a cross-industry system developed by @STMAssoc to address changes in EU Copyright law to actually facilitate sharing. It was discussed in a @scholarlykitchn post last May, which describes how it works and why. It is not for surveillance scholarlykitchen.sspnet.org/2021/05/17/stm…

@json_dirs Any idea if Elsevier checks that in the PDFs you upload to your Mendeley library?

@json_dirs OK, got a bug in my ear over this & wrote a little python script that doesn't require linearizing & maybe increasing the file size as it removes the metadata. Option to keep author/title. Also updated the applescript droplet to use this instead of pdf. github.com/Jmuccigr/scrip…