
LLaMA Factory @llamafactory_ai
Towards easy and efficient fine-tuning of large language models github.com/hiyouga/LLaMA-… Joined February 2024-
Tweets378
-
Followers3K
-
Following179
-
Likes1K

Excited to see Orthogonal Finetuning (OFT) and Quantized OFT (QOFT) now merged into LLaMA-Factory! 🎉 OFT & QOFT are memory/time/parameter-efficient and excel at preserving pretraining knowledge. Try them in: 🔗 LLaMA-Factory: github.com/hiyouga/LLaMA-… 🔗 PEFT:…


SGLang is now officially supporting OpenAI’s new GPT-OSS model!

SGLang is now officially supporting OpenAI’s new GPT-OSS model!
MiniCPM-V 4.0 visual fine-tuning is available at LlamaFactory 🌟

MiniCPM-V 4.0 visual fine-tuning is available at LlamaFactory 🌟



Falcon-H1 technical report is now available! The latest open hybrid Transformer–Mamba model family. The 80+ page report details the key design decisions behind H1, from architecture innovations, data strategies to training recipes challenging conventional practices in the filed

New tech report out! 🚀 Scaling Up RL: Unlocking Diverse Reasoning in LLMs via Prolonged Training An expanded version of our ProRL paper — now with more training insights and experimental details. Read it here 👉 arxiv.org/abs/2507.12507
New tech report out! 🚀 Scaling Up RL: Unlocking Diverse Reasoning in LLMs via Prolonged Training An expanded version of our ProRL paper — now with more training insights and experimental details. Read it here 👉 arxiv.org/abs/2507.12507


That would be so 🔥🔥🔥 @Alibaba_Qwen @Kimi_Moonshot

That would be so 🔥🔥🔥 @Alibaba_Qwen @Kimi_Moonshot

📢📢📢 Releasing OpenThinker3-1.5B, the top-performing SFT-only model at the 1B scale! 🚀 OpenThinker3-1.5B is a smaller version of our previous 7B model, trained on the same OpenThoughts3-1.2M dataset.

Introduce Easy Dataset No-code framework for synthesizing fine-tuning data from unstructured documents using LLMs/Ollamas Supports OCR, chunking, QA augmentation, and export to LlamaFactory/Unsloth fine-tuning frameworks huggingface.co/papers/2507.04…
LLaMA-Factory supported the multi-modal fine-tuning of the open-source GLM-4.1V-Thinking model at Day0 🔥

LLaMA-Factory supported the multi-modal fine-tuning of the open-source GLM-4.1V-Thinking model at Day0 🔥


PPO and GRPO — a workflow breakdown of the most popular reinforcement learning algorithms ➡️ Proximal Policy Optimization (PPO): The Stable Learner It’s used everywhere from dialogue agents to instruction tuning as it balances between learning fast and staying safe. ▪️ How PPO…
LLaMA Factory on ROCm 🔥
Fine-tune Llama-3.1 8B with Llama-Factory on AMD GPUs with this step-by-step guide: bit.ly/4k14ORL Discover more fine-tuning tutorials on the ROCm AI Developer Hub: bit.ly/4kLQiOQ

LLaMA-Factory now supports fine-tuning the Falcon H1 family of models using Full-FineTune or LoRA, kudos @DhiaRhayem
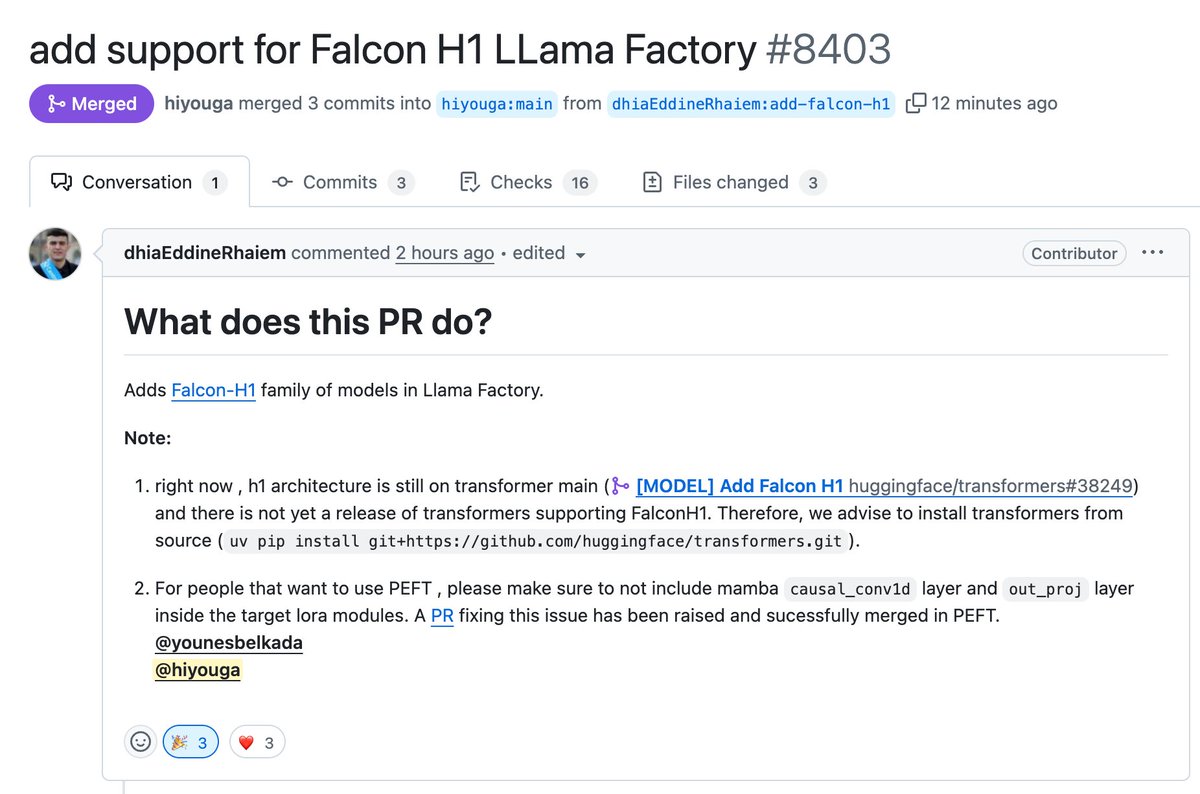

Insane milestone for Llama Factory!
Insane milestone for Llama Factory!

DeepSeek 671b and Qwen3 236b support with Megatron backend is now available as preview in verl v0.4.0 🔥🔥🔥 We will continue optimizing MoE model performance down the road. DeepSeek 671b: verl.readthedocs.io/en/latest/perf… verl v0.4: github.com/volcengine/ver…

Open weights, Open data, Open code -- SOTA reasoning model with only 7B parameters. Excited to see LlamaFactory powering its training 🥳

Open weights, Open data, Open code -- SOTA reasoning model with only 7B parameters. Excited to see LlamaFactory powering its training 🥳
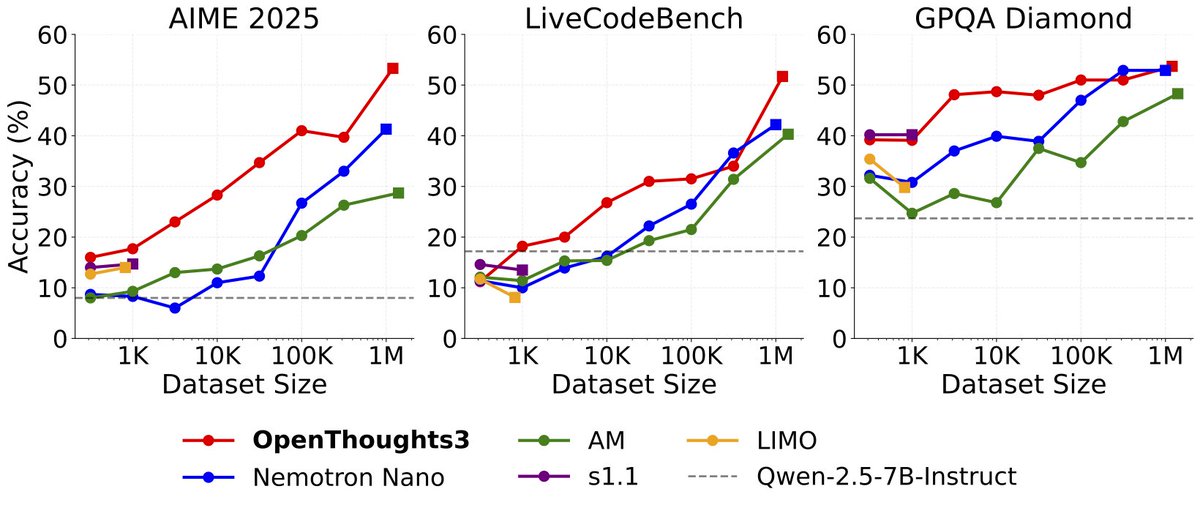
Paper: arxiv.org/abs/2506.04178 Model: huggingface.co/open-thoughts/… Dataset: huggingface.co/datasets/open-… Code: github.com/open-thoughts/… Blog: openthoughts.ai/blog/ot3 (10/N)


Jax Mengyuan Han @MengyuanHanPro
33 Followers 387 Following
Christian @AtThePrecipice
47 Followers 152 Following
Jourdain-Alexander Ca... @headertag
763 Followers 262 Following
Gin.AI @ginbitcoin
530 Followers 1K Following 手艺人${Build and Sell} 👩💻https://t.co/bbcms7zzaV 🎵https://t.co/0eA4oqyCux ¥1k/m 🌍https://t.co/XUNkYm2zq1 ¥10k/m Run, don't walk 心存善念,每个人都在打一场人生硬仗

Menoncio 🏀 @oiciruamnonem
205 Followers 941 Following
Castani @arteyco
946 Followers 6K Following ⚡ CryptoCulture, GenArt, https://t.co/wNYahEqvq2, https://t.co/O7hbKOV7C8……, https://t.co/pqoXZraF05, https://t.co/o8y25YKUNr, DecaGlyph #127:)!


frybox @frybox123
0 Followers 134 Following

Campbell @CoolTianti7916
4 Followers 96 Following I am from China and I am a scientific and technological researcher
Eddy Liang @eddymliang
34 Followers 158 Following
briquet black @briquetblack
1 Followers 80 Following
Distincto Apps @aionthespectrum
102 Followers 442 Following Father. Founder and CEO. ASD Advocate. Distincto: AI-First Apps from an AI-First Company, Delivering Big for the Global Neurodiverse Community
陈文雅 @Alya_wenya
0 Followers 25 Following
CuteRobot @lukeNukemAI
517 Followers 2K Following 🤖 AI enthusiast | 💻 Tech lover | 🐍 Python learner | Exploring innovation & the future of AI


ゆず @yo0237
101 Followers 1K Following


Yiping Wang @ypwang61
1K Followers 1K Following Ph.D. @uwcse. undergraduate @ZJU_China. I'm interested in mathematics, agi, and physics.

Misaki Wang @Misaki42031
0 Followers 120 Following
Understanding the wor... @ds_goer
18 Followers 767 Following
inhell @hahazhi123
33 Followers 330 Following

Haoling Li @v6Xk3l9VW2jAmoR
9 Followers 178 Following M.S. @Tsinghua_Uni; Intern @MSFTResearch. Focus on LLMs.
Ryan @Ryan7bot
3 Followers 87 Following
r3tsina @0xr3tsina
17 Followers 581 Following

Sigrid Jin | Jin Hyun... @sigridjin_eth
2K Followers 7K Following ✯ @thisissigrid ★ ☄ CS @UBC @ubcokanagan ☄ ★ Machine Learning Ultrathink Engineer @sionic_ai 🐟 digital nomad with Python, Golang & Rust 💻

newx @newx1115736
1 Followers 6 Following
Adaline.eth | OBYC | ... @ChrisAdaline
1K Followers 6K Following (that/it) #SQL #SQLServer #Workday 🐸#NotoriousFrogs of #Frogland 💊#CryptoPills 🐒#CHIMP https://t.co/aMtgQEOA4d 💀 #METAPUNKZ ☠ #SKULLY 🐻 #OBYC 🐵 #TRIBΞ
KSA + Ocean Lab Desig... @wukexiu2
18 Followers 133 Following opensea, akaswap, NFT, Architecture Design, Interior Design, Art ig: oceanlabdesign
Approach Zero @approach0
169 Followers 865 Following A math-aware search engine, searching Mathematics Stack Exchange and more.
DMResearch @DMResearch1
1 Followers 29 Following
Zhiqiu Xia @zqxia_rutgers
4 Followers 78 Following
viishwavijay @viishwavijay
162 Followers 6K Following This profile is digital library for me - Learn, Save, Share, repost

Turi👨💻 @QubeeGen
4K Followers 828 Following Graduate student @Tsinghua_uni @UESTC1956 alumnus "There is no elevator to success, you have to take all the stairs."
Dr.Dre @JCDenton09
182 Followers 5K Following
Volt @Volt42420709
27 Followers 812 Following
Tannhäuser Gate @chalomeon
134 Followers 2K Following
Terexitarius.tgn Δ (... @Terexitarius
628 Followers 821 Following Environmental Techno Anarchist Dinosaur BkWxsE9MH6cSdFikvuV3JsWyYXd8dBQXg38JqfudpQJr
Kevin @_kevinpictor
2K Followers 3K Following Founder @pictor_network - the decentralized GPU aggregator for 3D rendering and AI workloads. Enthusiast in AI & Blockchain | making moves on @Aptos
Ruu 10.10 Sonnet @ruu_1010
842 Followers 2K Following Information Engineering UGM | Candidate master titled chess player | AI Enthusiast https://t.co/LAT1G46Qf6

Less Wright @lessw2020
146 Followers 15 Following @PyTorch, Large Scale Distributed AI Training, Object Detection, Optimizers, Stock Indexes


Binyuan Hui @huybery
34K Followers 649 Following 🥝 Building Qwen @Alibaba_Qwen. Focus on CodeLLM (Pre-training and Post-training) / Reasoning / Agent. Ideas my own.
👋 Jan @jandotai
11K Followers 975 Following Jan is an open source ChatGPT-alternative that runs 100% offline. Built by @menloresearch. Community: https://t.co/gXXor3poY5
Shengjia Zhao @shengjia_zhao
52K Followers 231 Following Chief Scientist @ Meta MSL. Formerly MTS @ OpenAI, PhD @ Stanford. I train models. All opinions my own.
Shawn Shen @shawnshenjx
3K Followers 273 Following Co-Founder @memories_ai | 🥊 rookie | Cambridge PhD | Prev Meta Reality Labs
Yana Wei @yanawei_
82 Followers 52 Following PhD student@Johns Hopkins University; Multimodal Understanding, Embodied Agent, Image Editing
Yasmine @CyouSakura
2K Followers 788 Following Researcher @StepFun_ai. Working on scalable RL methods in #LLM. she/her/hers. 守护最好的猫猫@biliacat_public
ES-FoMo@ICML2025 @ESFoMo
357 Followers 37 Following Efficient Systems for Foundation Models Workshop, ICML2025. Join us if you are interested in the challenges associated with large models training & inference!
Wanchao Liang @wanchao_
1K Followers 225 Following building @thinkymachines ex-PyTorch @ Meta. Author of PyTorch DTensor and TorchTitan. Opinions are my own
vLLM @vllm_project
17K Followers 20 Following A high-throughput and memory-efficient inference and serving engine for LLMs. Join https://t.co/lxJ0SfX5pJ to discuss together with the community!
Haojun Zhao @Haojun_Zhao14
902 Followers 358 Following Research engineer @huggingface prev @Polytechnique
Saining Xie @sainingxie
23K Followers 1K Following researcher in #deeplearning #computervision | assistant prof at @nyu_courant | rs @googledeepmind | past: rs @meta (FAIR) @ucsandiego | ynwa
zR @zRdianjiao
455 Followers 46 Following 👨💻 Working at the @Zai_org 🧠 Focused on LLM algorithms & open-source 🔧 Bringing GLM model series to open-source frameworks
Quentin Gallouédec @QGallouedec
3K Followers 663 Following PhD - Research @huggingface 🤗 TRL lead maintainer 🇫🇷 in 🇨🇦
AI at AMD @AIatAMD
47K Followers 106 Following Advancing AI innovation together. Built with devs, for devs. Supported through an open ecosystem. Powered by AMD. #TogetherWeAdvance
Songlin Yang @SonglinYang4
12K Followers 3K Following research @MIT_CSAIL @thinkymachines. working on scalable and principled algorithms in #LLM and #MLSys. in open-sourcing I trust 🐳. she/her/hers
Ludwig Schmidt @lschmidt3
6K Followers 426 Following Assistant professor at @Stanford and member of the technical staff at @AnthropicAI.
Iris @irisyang_iris
30 Followers 248 Following
Zengzhi Wang @SinclairWang1
2K Followers 3K Following PhDing @sjtu1896 #NLProc Working on Data Engineering for LLMs: MathPile (2023), 🫐 ProX (2024), 💎 MegaMath (2025),🐙 OctoThinker(2025)
Akshay 🚀 @akshay_pachaar
227K Followers 484 Following Simplifying LLMs, AI Agents, RAGs and Machine Learning for you! • Co-founder @dailydoseofds_• BITS Pilani • 3 Patents • ex-AI Engineer @ LightningAI


Avi Chawla @_avichawla
51K Followers 134 Following Daily tutorials and insights on DS, ML, LLMs, and RAGs • Co-founder @dailydoseofds_ • IIT Varanasi • ex-AI Engineer @ MastercardAI

ZenHuifer @fer_hui14457
2K Followers 82 Following Founder of the world's first Rust IoT development platform 🐶 #Rust #Golang #IoT
Remek Kinas @KinasRemek
5K Followers 714 Following AI Researcher | Bielk LLM co-creator | Kaggle Grand Master

熊布朗 @Stephen4171127
7K Followers 707 Following INTP / AIGC 产品经理 超过2000 小时AI 学习实践 沉迷于 Vibe Coding,每个月产出 1 个有用的项目 🤖业务重点在 AI Agent 和 Character AI 📋积极分享 AI 特种兵小团队作战经验 24年法国人才签证定居巴黎,可提供免费咨询
🇺🇦 Dzmitry Bahd... @DBahdanau
10K Followers 37 Following Team member at something young. Adjunct Prof @ McGill. Member of Mila, Quebec AI Institute. Stream of consciousness is my own.
Axolotl AI @axolotl_ai
2K Followers 56 Following Axolotl is the premier open source LLM fine tuning framework. find us on discord https://t.co/wlcE2wlJa9 or email us at [email protected]
Shangshang Wang @UpupWang
387 Followers 124 Following 2nd year Phd student in CS + AI @CSatUSC. CS undergrad, master @ShanghaiTechUni. LLM reasoning, AI4Science, RL.
Dify @dify_ai
19K Followers 164 Following Build Production-Ready AI Agent GitHub: https://t.co/MfnJ29Agzj Discord: https://t.co/DJmS3kYvYZ Reddit: https://t.co/EneVBsKTzR
Chujie Zheng @ChujieZheng
6K Followers 301 Following Researcher @Alibaba_Qwen | GSPO, Qwen3, QwQ, ProcessBench | Opinions are my own
GOSIM Foundation @gosimfoundation
280 Followers 88 Following Discover and grow global open-source projects for various technology areas. GOSIM Hangzhou 2025: Sept 13–14|Hangzhou, China
Nadav Timor @NadavTimor
729 Followers 7K Following LLM inference, speculative decoding, open source. Built novel decoding algorithms – default in Hugging Face Transformers (147k+ ⭐). Making LLMs faster + cheaper
Yi Wu @jxwuyi
1K Followers 103 Following AI/RL researcher, Assistant Prof. at @Tsinghua_Uni, leading the RL lab at @AntResearch_, PhD at @berkeley_ai, frequent flyer and milk tea lover.

Lianmin Zheng @lm_zheng
13K Followers 609 Following Member of technical staff @xAI | Prev: Ph.D. @UCBerkeley, Co-founder @lmsysorg
Ying Sheng @ying11231
12K Followers 716 Following @lmsysorg | Prev. @xAI @Stanford | Assist Prof @UCLA. (Fall 2026) | Do it anyway | Live to fight another day
Sumanth @Sumanth_077
72K Followers 865 Following Simplifying LLMs, RAG, Machine Learning & AI Agents for you! • ML Developer Advocate • Shipping Open Source AI apps
Sicong @Leon_L_S_C
263 Followers 630 Following CS Graduate, Ph.D. majoring in Multi-Modality AI Research, Alibaba-NTU Talent Programme.
Wei Xiong @weixiong_1
1K Followers 540 Following Statistical learning theory, Post-training of LLMs, RAFT, LMFlow, GSHF, and RLHFlow. PhD Student @IllinoisCS, current @GoogleDeepMind, prev @MSFTResearch @USTC
TRAE @Trae_ai
27K Followers 26 Following The Real AI Engineer. Download now: https://t.co/kapduuwttm Join SOLO waitlist: https://t.co/UXvS3gZnw7


Quanquan Gu @QuanquanGu
16K Followers 2K Following Professor @UCLA, Pretraining and Scaling at ByteDance Seed | Recent work: Build AGI | Opinions are my own
Ariel @redtachyon
750 Followers 203 Following p/hd | Big RL energy | 0.71 |research⟩ + 0.71 |engineer⟩ @ Meta, but never speaking on behalf of the company | Prev. lead maintainer of GymnasiumTrends for United States
You might like



















