
-
Tweets22
-
Followers111
-
Following2K
-
Likes945
Thrilled our global data ecosystem audit was accepted to #ICLR2025! Empirically, we find: 1⃣ Soaring synthetic text data: ~10M tokens (pre-2018) to 100B+ (2024). 2⃣ YouTube is now 70%+ of speech/video data but could block third-party collection. 3⃣ <0.2% of data from…


Testing LLMs' reasoning skills is tough—human evaluations are expensive, data contamination is common, and LLM judges can be biased. We propose StructTest, the first benchmark that checks how well LLMs follow complex instructions and create structured outputs. It uses a…

✨New Report✨ Our data ecosystem audit across text, speech, and video (✏️,📢,📽️) finds: 📈 Rising reliance on web, synthetic, and YouTube data. 🛑 80%+ datasets carry hidden restrictions. 🌍 Relative representation in languages and creators has not improved for 10+ yrs.…
✨New Preprint ✨ How are shifting norms on the web impacting AI? We find: 📉 A rapid decline in the consenting data commons (the web) ⚖️ Differing access to data by company, due to crawling restrictions (e.g.🔻26% OpenAI, 🔻13% Anthropic) ⛔️ Robots.txt preference protocols…


Introducing: 💫StarCoder StarCoder is a 15B LLM for code with 8k context and trained only on permissive data in 80+ programming languages. It can be prompted to reach 40% pass@1 on HumanEval and act as a Tech Assistant. Try it here: shorturl.at/cYZ06r Release thread🧵

Announcing a holiday gift: 🎅SantaCoder - a 1.1B multilingual LM for code that outperforms much larger open-source models on both left-to-right generation and infilling! Demo: hf.co/spaces/bigcode… Paper: hf.co/datasets/bigco… Attribution: hf.co/spaces/bigcode… A🧵:


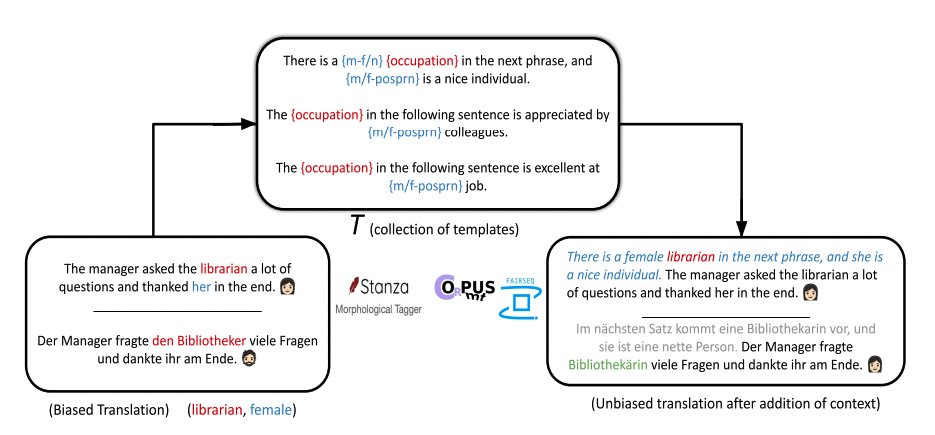
✨Our work "How sensitive are translation systems to extra contexts? Mitigating gender bias in Neural Machine Translation models through relevant contexts" got accepted at the Findings on EMNLP 2022!✨ Joint work with @manandey and our awesome mentor @koustuvsinha 🎉

BLOOM is here. The largest open-access multilingual language model ever. Read more about it or get it at bigscience.huggingface.co/blog/bloom hf.co/bigscience/blo…


New paper alert! 🎉 Turns out you can reduce the gender biases your translation models just using relevant contexts, purely during inference! Checkout this cool work led by @evolvedeve and @manandey! arxiv.org/abs/2205.10762 [1/4]

🧐🕵️I am looking for the best possible open source tool to do memory profiling! I would like to know what part of my python code is causing these memory usage spikes that don't necessarily come from the Python interpreter. Looking forward to reading your recommendations! 🤗

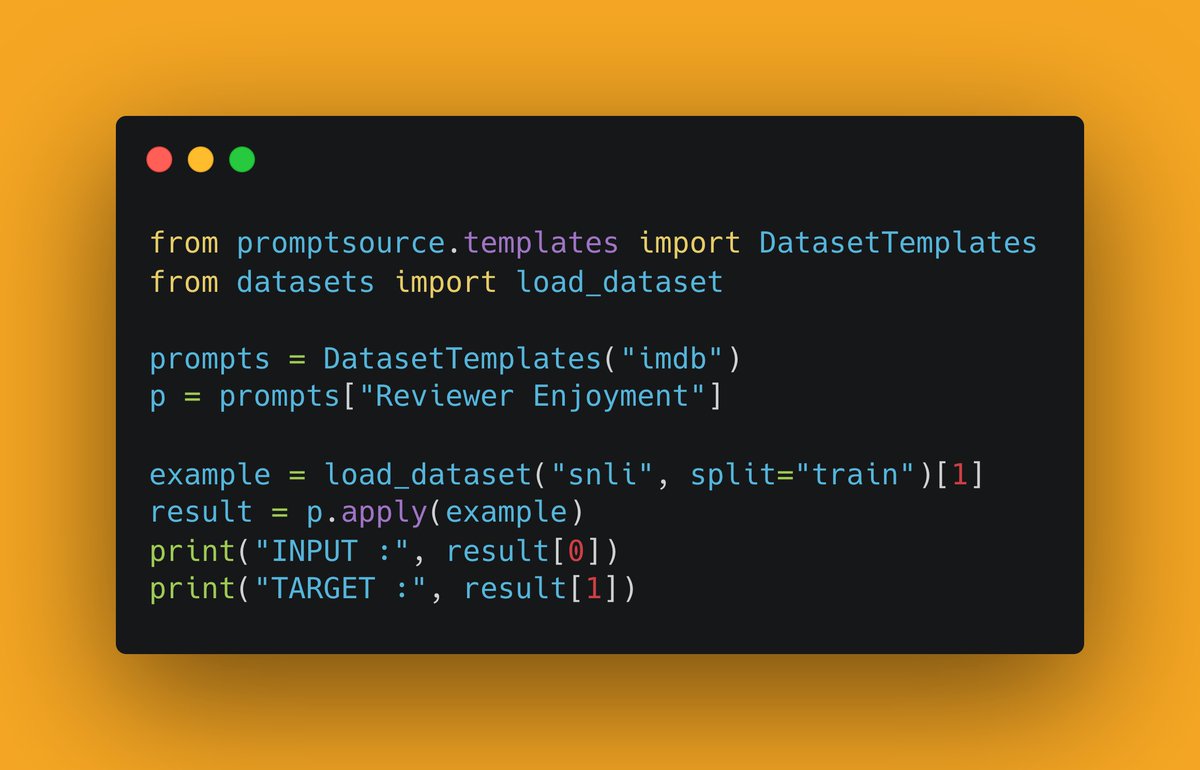
We are releasing PromptSource, a toolkit for creating, sharing, and using natural language prompts. We used it to create the largest open-source collection of English prompts: 2,000 prompts for 170 datasets! 📄 arxiv.org/abs/2202.01279 💻 github.com/bigscience-wor…

Tokenization—the least interesting #NLProc topic? Hell no! We, members of the @BigscienceW tokenization group are proud to present: ✨Between words and characters: A Brief History of Open-Vocabulary Modeling and Tokenization in NLP✨ arxiv.org/abs/2112.10508 What's in it? [1/10]


We’ve seen crazy interest in T0++ (pronounced "T Zero Plus Plus"), and almost 10’000 queries to the model since we announced it 3 days ago. Probably the most hilariously decisive prediction from the model (courtesy of @_philschmid): 1/N

First modeling paper out of BigScience is here! T0 shows zero-shot task generalization on English natural language prompts, outperforming GPT-3 on many tasks, while being 16x smaller! Model: huggingface.co/bigscience/T0pp Repo: github.com/bigscience-wor… Paper: arxiv.org/abs/2110.08207

Hi #NeurIPS2020! I and @manandey will be presenting our poster on *Evaluating Gender Bias in NLI* at the Workshop on Dataset Curation and Security today (11th Dec) at 2:30 PM EST. Drop by if you're around :) cc: @koustuvsinha Gather Town (Poster 19) neurips.gather.town/app/A4yaHmXq3U…

I'm really happy to share that our work on evaluating gender bias in NLI systems has been accepted at #NeurIPS2020 Workshop on Dataset Curation and Security. Joint work with amazing collaborators @manandey and @koustuvsinha. More details coming soon!
I'll be presenting our poster on assessing viewer's mental health by analysing YouTube videos at AI for Social Good workshop at #NeurIPS2019! Drop by if you’re around! Poster sessions at 9:35-10:30 AM and 3:30-4:15 PM East MR11,12 - with @manandey
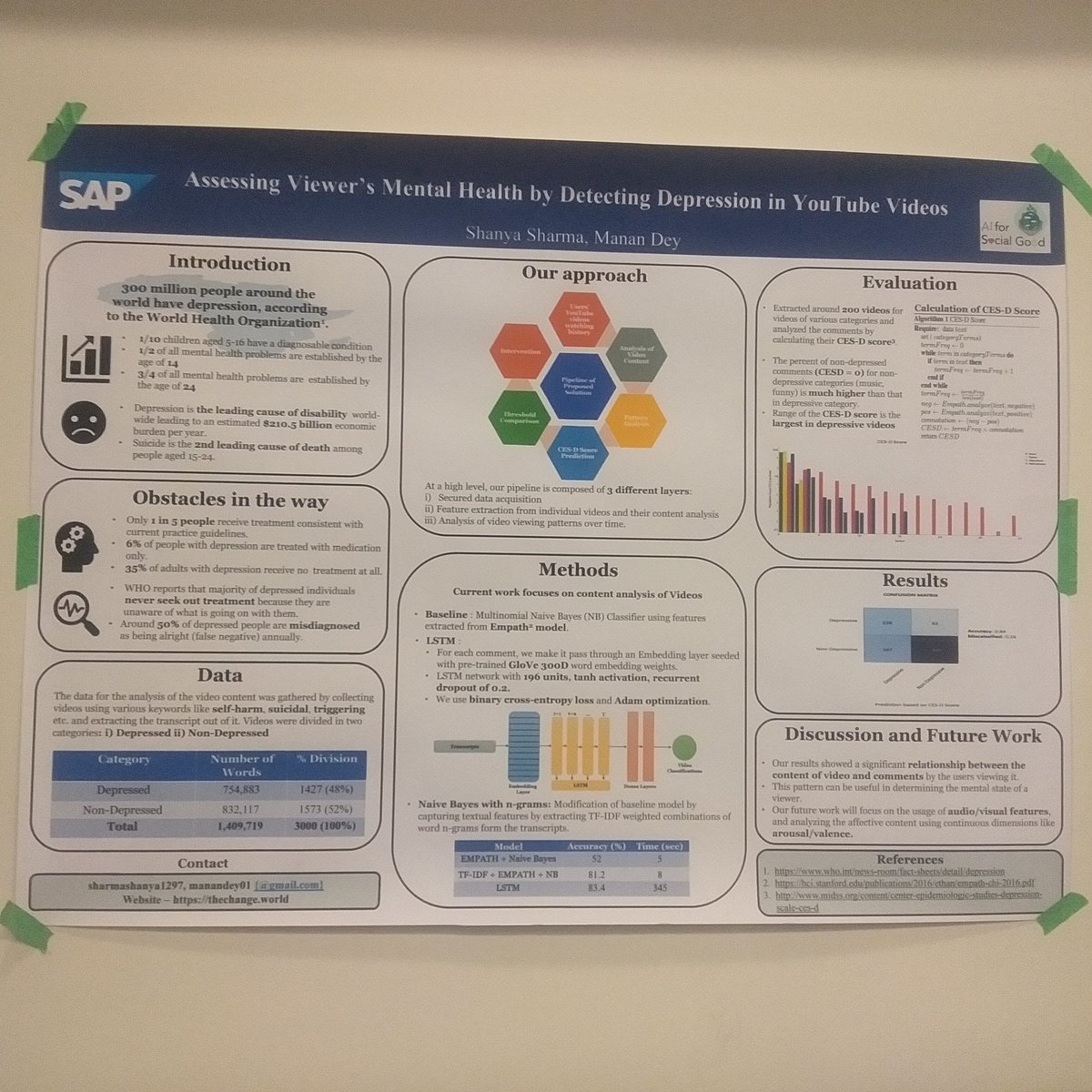
Really happy that our (me and @manandey) paper has been accepted @NeurIPSConf 2019 Workshop on AI for Social Good". We'll be discussing about the effect of YouTube videos on viewer's mental health. You can read more about our work at thechange.world #AI4Good #NeurIPS

Kelly🎻 @Plarvoug477
1 Followers 184 Following
Abram Lenora @UyenAdrea48496
1 Followers 99 Following Recruiting webshell engineers to penetrate webs ites, with a monthly salary of up to $100,000. If interested, please contact https://t.co/p6pJJl0tuQ

HeloiseBroad @4u14O0S4dDeUnV0
81 Followers 2K Following
Penguin X-01 @PenguinX01
2K Followers 2K Following 📡 Censoring this account = Felony Obstruction 🧬 Minnesota HF3219: mRNA = WMD 🐧 I am propagating
Henil Panchal🚀 ICL... @Henilp105
212 Followers 4K Following Research Intern @TCSResearch @UofIllinois | GSoC @fortranlang | LLM security
AbigailEmmie @o1bwfy367338
15 Followers 213 Following Let me be the target of your lust tonight!Click on the website below,,everything will satisfy you!
Jianguo Zhang @JianguoZhang3
1K Followers 534 Following Senior Research Scientist @SFResearch. Lead #xLAM and #LLMAgents. @AIatMeta @AdobeResearch, @SFResearch and @AlibabaGroup research intern.
Will Brannon @wwbrannon
639 Followers 2K Following PhD @MIT. Interests: data-centric AI, socially aware ML systems, computational social science.
Pratyay Banerjee (ন... @Neilzblaze007
294 Followers 7K Following I live in the shadows, but I watch everything.
Jad Kabbara @jad_kabbara
1K Followers 750 Following NLP Postdoc @MIT Center for Constructive Communication (CCC). PhD from McGill University @rllabmcgill & @Mila_Quebec. @AUB_Lebanon alum.
Brihi Joshi @BrihiJ
2K Followers 4K Following PhD-ing @nlp_usc🏝 + @AmazonScience @Apple Fellow, ex-@IIITDelhi. Sky pics, #NLProc, @5sos and cat content, mostly thinking about “useful” AI
Jonathan Chang @ChangJonathanC
1K Followers 865 Following ML/AI Engineer, building https://t.co/uEbfxzF7jm
Jordi Clive @JordiClive
292 Followers 896 Following Lead Machine Learning Scientist @ChattermillAI • ML Researcher @laion_ai • NLG Research @imperialcollege


Shayne Longpre @ShayneRedford
6K Followers 1K Following Lead the Data Provenance Initiative. PhD @MIT. 🇨🇦 Prev: @Google Brain, Apple, Stanford. Interests: AI/ML/NLP, Data-centric AI, transparency & societal impact
Kathrine Jame @jame_kathr18476
76 Followers 2K Following
Teseatith @teseatith60499
11 Followers 465 Following Ensine você a usar seu telefone celular em casa para obter lucros elevados com facilidade e acumular riqueza rapidamente.
Antti Luoto @Antti_Luoto
236 Followers 996 Following Founder/CEO, Next Generation Operations Management @ Operate. Finnish, MSc. Industrial Engineering. Less hype, more value.
Masoud Jalili @_masoudjalili
483 Followers 602 Following Researcher @Volkswagen, PhD from @CisLMU @LMU_Muenchen Interests: NLP, ML
Sahithya Ravi @Sahithya_Ravi
431 Followers 531 Following PhD @UBC_CS | @VectorInst I @UBC_NLP | Prev @MetaAI @MSFTResearch @Open_ML
Harm de Vries @harmdevries77
1K Followers 173 Following Building something new | prev co-lead @BigCodeProject @ServiceNowRsrch | PhD from @Mila_Quebec
Alex Gu @minimario1729
4K Followers 2K Following intern @ meta, mit phd student (on job market!), llm for math+code / prev nvidia, aws, jane street / enjoys 🎹✈️⛷️⛵
Julia Kaltenborn @JuliaKaltenborn
474 Followers 371 Following Machine Learning for Climate Science. Research MSc @mcgillu / @Mila_Quebec. Co-Founder of Unser Dialog. @aihelpsukraine She/Her.
Olivier Breuleux @broolucks
268 Followers 311 Following I design programming languages, I write short stories. Sometimes I do other things.
Pratheeksha Nair @prathena_96
348 Followers 420 Following PhD student in Computer Science @complexDataLab @mcgillu @Mila_Quebec Machine Learning.💻 Social Good.🕊️ Coffee.☕
Sarvjeet Ghotra @sarvjeet_ghotra
296 Followers 576 Following Curr. at @nvidia and PhD at @Mila_Quebec | Multi-modal DL, RL | Prev.: Applied Scientist on Turing team at @Microsoft On a quest to make rocks think.
Vishrav Chaudhary @vishrav
631 Followers 695 Following Researcher at Superintelligence Lab @MetaAI. Ex- @Microsft Turing @MetaAI @LTIatCMU alum.
Nithya Nadig Shikarpu... @NithyaIsMe
513 Followers 728 Following interested in music + technology research | Hindustani music student | PhD student MIT
Mansi Rankawat @mansi_rankawat
184 Followers 414 Following Ph.D. student at @Mila_Quebec and @UMontrealDiro under @SimonLacosteJ, previously @NVIDIAAI, @gtcomputing, @DAIICT, @iiit_hyderabad
Sarthak Mittal @sarthmit
669 Followers 738 Following Graduate Student at @Mila_Quebec and Visiting Researcher @Meta. Prior Research Intern at @Apple, @MorganStanley, @NVIDIAAI and @YorkUniversity
Matthew Scicluna @MattScicluna
418 Followers 739 Following In theory, I’m here for the 🤖🎓and 🧬 I am on bluesky too: https://t.co/NMZQGuhaaq
Arnav Jain @arnavkj95
525 Followers 1K Following PhD student University of Montréal and @Mila_Quebec, Research Intern at @Cohere. Prev at @Microsoft, BSc & MSc @IITKgp.
Krishna Maneesha Dend... @maneeshadkr
457 Followers 1K Following Research Assistant @Mila_Quebec| Prev - Grad student Mila & UdeM, ML Research Intern @dboxtech, Data Science @embibe| Audio/Music xAI | Vision | Comp.Creativity
Shruti Joshi @_shruti_joshi_
408 Followers 828 Following phd student in identifiable repl @Mila_Quebec. prev. research programmer @MPI_IS Tübingen, undergrad @IITKanpur '19.
Sangnie Bhardwaj @sangnie
451 Followers 338 Following ML researcher @GoogleAI. PhD student @Mila_Quebec.
Rohan Sukumaran @ Neu... @rohanalchemist
553 Followers 1K Following Grad student @mila_quebec; Responsible AI. Prev: Research Manager @PathCheck_fnd; Applied Research, @SwiggyTech; CSE @IIITSC
Jithendaraa Subramani... @jithendaraa
393 Followers 648 Following Visiting Researcher @ServiceNow | Ex @AmazonScience | Grad student @mcgillu, @Mila_Quebec
Hena Ghonia @hena_ghonia
259 Followers 965 Following
Chen-Yang Su @chenyangsu
639 Followers 558 Following Young Investigator Committee @genepisociety | PhD @McGillU (@CIHR_IRSC) | Previously @LDI_ILD @Mila_Quebec | https://t.co/qTBq8phIqK
Ivaxi Sheth @ivakshi_s
419 Followers 864 Following PhD student @CISPA | Prev @Mila_Quebec @imperialcollege'20 Causality / LLMs / Safety
Jason Hartford @jasonhartford
2K Followers 2K Following Dame Kathleen Ollerenshaw Fellow at @csmcr; Member of @ELLISforEurope; Research Unit Lead for the causality unit at @valence_ai. South African 🇿🇦
Nikhil @Nikhil1311Nk
193 Followers 376 Following Graduate student at @mcgillu | @Mila_Quebec, @rllabmcgill | Previously: @Shell, @SymphonyAi, @PESUniversity
Abhay Puri @AbhayPuri98
607 Followers 1K Following Senior ARS @ServiceNowRSRCH| ex-MLE @Jumio, @Mila_Quebec
Harry Zhao @TheHarryZhao
781 Followers 1K Following Scientist @wayve_ai / PhD from @mcgillu x @Mila_Quebec, advised by Doina Precup & @Yoshua_Bengio A true friend who roasts you and learns with you
Nilanjan Sarkar @nilan_blue
345 Followers 4K Following Unlearning in LLMs| M.E CS @bitshyd| Applied Scientist intern @AmazonScience IML| #recsys #nlp #nlproc #clang #compilers #llvm
Ananya @anon_yas
30 Followers 1K Following Still learning computer science. Want to become great AI engineer.
Nikita Saxena (she/he... @nikitasaxena02
1K Followers 1K Following RE @GoogleDeepmind | @WiMLWorkshop | @Mila_Quebec | @bitspilaniindia
Arnab @ArnabMondal96
2K Followers 488 Following ML Researcher @Apple | PhD @mcgillu + @Mila_Quebec | Undergrad @IITKgp | Formerly: @MSFTResearch @ServiceNowRSRCH @samsungresearch



Xiao Ma @infoxiao
11K Followers 3K Following gemini post-training @googledeepmind. prev: responsible ai @google, core data science @facebook, research @airbnb, phd @cornell_tech. views are mine. sh-i-ow.
basvanopheusden @basvanopheusden
2K Followers 238 Following Research at OpenAI, previously @imbue_ai and @cocosci_lab lab at Princeton. All opinions my own

Nidhi Pathak @ughitsnidhi
166 Followers 451 Following space cowgirl/ @Duke University / Product Manager
Shikhar @ShikharMurty
3K Followers 210 Following Computer Agents and RL post-training @GoogleDeepMind, prev: Stanford CS PhD student @StanfordNLP
Roberta Raileanu @robertarail
9K Followers 2K Following Senior Staff Research Scientist @GoogleDeepMind & Honorary Lecturer @UCL. ex @Meta|@MSFTResearch|@NYU|@Princeton. Llama-3, Toolformer, Rainbow Teaming, MLGym.
Keerthana Gopalakrish... @keerthanpg
17K Followers 1K Following Mother of robots. Building Embodied AGI @DeepMind. Author of "AI for Robotics". Opinions my own.
Akari Asai @AkariAsai
18K Followers 867 Following Incoming Assistant Professor @SCSatCMU & research scientist @allen_ai. akariasai @ 🦋
Prateek Yadav @prateeky2806
4K Followers 2K Following pre-training @AlatMeta, prev: part-time @GoogleDeepMind, PhD at @unccs

Manasi Sharma @ManasiSharma_
345 Followers 244 Following research engineer @scale_AI, working on reasoning for frontier models, agents, rl | prev @stanford, @StanfordAILab, @mitll, @Columbia
Trapit Bansal @TrapitBansal
32K Followers 247 Following AI Research @Meta | Co-Creator of OpenAI o1 | Previously @OpenAI, @MSFTResearch, @GoogleAI, @facebook, @iiscbangalore, and undergrad @IITKanpur
Divyashree Sreepathih... @divyasheess
146 Followers 42 Following Founder KerasHub | Keras Lead AI @google
Caroline Wang@RLC25 @CarolineWang98
261 Followers 344 Following PhD Student in MARL @UTCompSci | Student Researcher @GoogleDeepMind | ex @SonyAI_global @dukecompsci

Marta Skreta @martoskreto
1K Followers 248 Following currently interning @MSRNE | @UofTCompSci PhD Student in @A_Aspuru_Guzik's #matterlab and @VectorInst | prev. @Apple

Flent @flenthomes
5K Followers 11 Following Jaw-dropping rental homes for those who expect more and compromise less.
Zach Wilson @EcZachly
45K Followers 1K Following Founder @ https://t.co/CWvLDHU2Lx $150k/month | https://t.co/F5VqLpyMZn $5k/month | ADHD | 10 yrs big data experience | ex @facebook, @netflix, and @airbnb
Reflection AI @reflection_ai
7K Followers 0 Following We’re building American Open Superintelligence.
Moumita Bhattacharya @moumita_bh
626 Followers 1K Following Senior Research Scientist @Netflix, previously Tech Lead @Etsy || Adjunct Faculty || PhD in ML #MachineLearning #ArtificialIntelligence #RecSys #IR



Chen Liang @crazydonkey200
1K Followers 216 Following Research Scientist @GoogleDeepMind automating AI research for Gemini. Opinions my own.
DeepSeek @deepseek_ai
973K Followers 0 Following Unravel the mystery of AGI with curiosity. Answer the essential question with long-termism.
Melissa Pan @melissapan
2K Followers 528 Following CS PhD @UCBerkeley Sky Lab 🐻 Systems & AI & Sustainability 🌍 Prev: @google, @ibm, @CarnegieMellon🐕🦺, @UofT🇨🇦
Haotian Tang @haotiant1998
2K Followers 266 Following Research Scientist @Meta. Previously @GoogleDeepMind, Ph.D. @MITEECS, B.Eng. @sjtu1896.



Sriram Krishnan @sriramk
302K Followers 1K Following White House Senior Policy Advisor for AI. pro wrestling fan. official: @skrishnan47
Yuchen Jin @Yuchenj_UW
54K Followers 535 Following Co-founder & CTO @hyperbolic_labs 🧑🍳 fun AI systems. Previously: OctoAI (acquired by @nvidia) building @ApacheTVM, PhD @uwcse 🤖
Jane Manchun Wong @wongmjane
169K Followers 3K Following “The woman scooping Silicon Valley” — BBC, Security Researcher / Technology Blogger
Christine McLeavey @mcleavey
9K Followers 3K Following @openai audio team: gpt-4o, jukebox & musenet
Melissa Heikkilä @Melissahei
13K Followers 3K Following AI Correspondent @FT. Former senior reporter for AI @techreview. | Ex @POLITICOEurope & @TheEconomist | Forbes 30 under 30 | She/her
Andreea Bobu @andreea7b
3K Followers 441 Following Assistant Professor @MITAeroAstro and @MIT_CSAIL ∙ PhD from @Berkeley_EECS ∙ machine learning, robots, humans, and alignment
GREG ISENBERG @gregisenberg
523K Followers 867 Following I run a portfolio of internet companies and host @startupideaspod. CEO: @latecheckoutplz we build companies like @ideabrowser, @meetLCA, @boringmarketer etc
Aida Nematzadeh 🦋 @aidanematzadeh
2K Followers 270 Following Research scientist at @DeepMind.🦎 She/her. https://t.co/R0MeGzdnuj

Yoshua Bengio @Yoshua_Bengio
25K Followers 206 Following Working towards the safe development of AI for the benefit of all @UMontreal, @LawZero_ & @Mila_Quebec A.M. Turing Award Recipient and most-cited AI researcher.
Shafiq Joty @JotyShafiq
962 Followers 439 Following Sr. Research Director@Salesforce AI, Assoc. Prof@NTU (on leave) Project lead of SFR-RAG, SFR-Judge, XGen
Thomas Dohmke @ashtom
60K Followers 412 Following Building GitHub Copilot for the sake of developer happiness. CEO @GitHub
Saffron Huang @saffronhuang
6K Followers 941 Following how shall we live together? societal impacts researcher @AnthropicAI • @collect_intel co-founder • ex @AISecurityInst @GoogleDeepMind⋅ views mine
Philippe Laban @PhilippeLaban
1K Followers 692 Following Research Scientist @MSFTResearch. NLP/HCI Research.Trends for United States
You might like













