
Jongsu Liam Kim @sky0bserver
The CFD enthusiast has become a ML researcher. Senior Researcher at LG CNS AI Lab. Opinions are solely my own and do not express the opinions of my employer. liam.kim Seoul Joined November 2010-
Tweets1K
-
Followers134
-
Following681
-
Likes4K

These blogs are so awesome, I feel like I should stop writing because I am not good enough.

These blogs are so awesome, I feel like I should stop writing because I am not good enough. https://t.co/U1yzUmoOSN

I do not think a better "short note" exists on the topic. This was extremely to the point and knowledge dense. Love this style.



It's really interesting comparing the Ultra-Scale playbook (huggingface.co/spaces/nanotro…) and How To Scale Your Model, aka the JAX book (jax-ml.github.io/scaling-book/) side-by-side. 🧵

Pretraining with cross entropy = learning the best compressor for all texts ever written Why? Minimize CE = Min. KL between two distributions, eg HUMANS and LLM = the expected cost in bits when compressing samples drawn from HUMANS, while using LLM as your best approximation
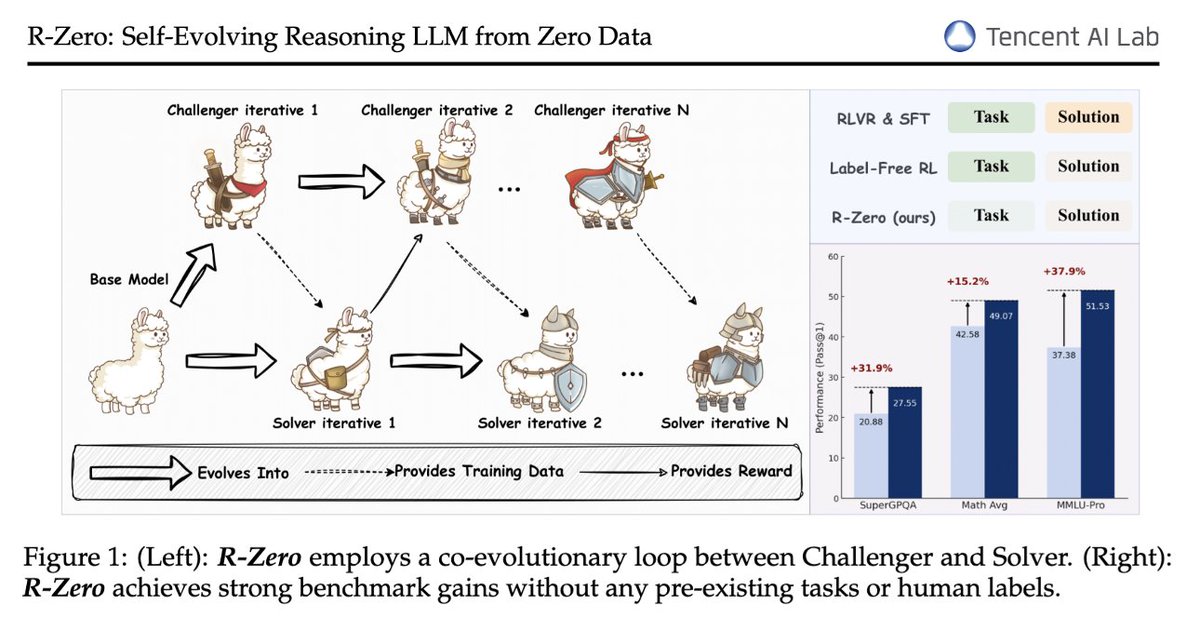
Some insights from training self-evolving LLM (R-Zero): 1. Larger size models -> stronger self-evolution ability 2. Challenger & Solver should NOT share parameters 3. Pseudo-label quality degrades over time (a key drawback to tackle) In Sec 5.4 and 5.5: arxiv.org/abs/2508.05004
“they built an image editing model. It could follow simple instructions well. When the ability to follow simple instructions is used and connected as needed for a task (CoT), visual reasoning problems will start to be solved.”
“they built an image editing model. It could follow simple instructions well. When the ability to follow simple instructions is used and connected as needed for a task (CoT), visual reasoning problems will start to be solved.”
This is my summary of a podcast interviewing Xiangyu Zhang (youtube.com/watch?v=vWrYHv…). I found this very insightful. As I have used whisper to transcribe and gemini to translate this, it could contain errors. Though, considering the overall flow of the content, I think it would be…
“In three words: RL finally works. More precisely: RL finally generalizes.”

“In three words: RL finally works. More precisely: RL finally generalizes.”
1. why RL didn't work before? 2. why it works now?

Well sorry to insist, but the catch is that the market is still small — that's less than chewing gum industry. Too small for a bubble.


One of Pi0's novel architecture bits is the use of a Flow Matching action head -- previous to this, modern VLAs like OpenVLA leveraged diffusion diffusion heads What is a flow matching head? What makes it easier to use versus other denoising heads? A short thread!🧵 (1/7)


VLAs offer an avenue for generalist robot policies; however, naively following the action predictions leads to brittle or unsafe behaviours. We introduce VLAPS, which integrates model-based search with pre-trained VLA policies to improve performance without additional training.

Most “robustness” work (adversarial, shift, etc.) is just training on reweighted samples (augmented, model-generated, or mined). OOD generalization then comes from: (1) inductive bias (2) similarity to train data (3) luck The 3rd one is the most important of the three.
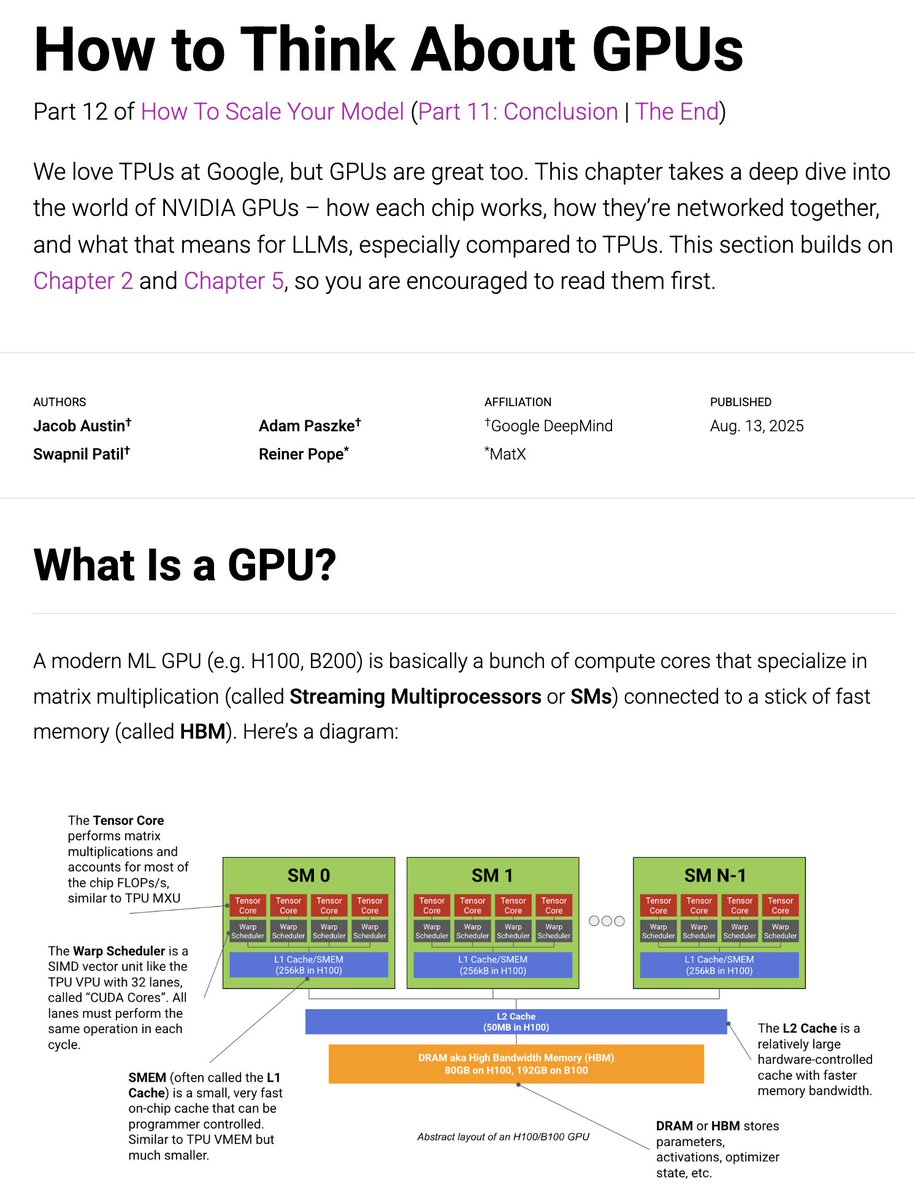
Today we're putting out an update to the JAX TPU book, this time on GPUs. How do GPUs work, especially compared to TPUs? How are they networked? And how does this affect LLM training? 1/n
State of torch.compile, August 2025.

The best AI researchers zoom at three abstraction levels: - High: paper-level ideas & math - Mid: code-level implementation - Low: GPU/TPU reality (kernels/memory) Low exposes bottlenecks. High accelerates exploration. Mid makes it real. The job is to translate between them!
I wrote a short post on learning the fundamentals of distributed systems, with a few suggested resources to read and a few suggested projects to try.


Srerdor @Srerdor920260
78 Followers 2K Following

Grace @Rodncsott
690 Followers 3K Following Sure I am of this, that you have only to endure to conquer.
Ron Koch @KochRon43699
80 Followers 3K Following
Axerfa @Axerfa686739
7 Followers 1K Following
Mesau @Mesau9434405
38 Followers 601 Following
Ellsworth Jacobi @EllsworthJ52598
24 Followers 2K Following
Seunghyun Seo @SeunghyunSEO7
2K Followers 798 Following deep learning enjoyer. from speech to llm, now exploring image space.
Sigrid Jin | Jin Hyun... @sigridjin_eth
2K Followers 7K Following ✯ @thisissigrid ★ ☄ CS @UBC @ubcokanagan ☄ ★ Machine Learning Ultrathink Engineer @sionic_ai 🐟 digital nomad with Python, Golang & Rust 💻
Griffiths Jin🌝 @jypthemiracle
296 Followers 1K Following 코딩과 글쓰기를 좋아하는 수학과 학부생. @khuniv 어릴 적부터 기계인간 메텔을 동경했습니다 🎧 @wiffygriffy @auroramusic

유딱계 님 외 99�... @yuttag189090
11 Followers 127 Following
개발하는 편집�... @pro__editor
428 Followers 967 Following IT 출판사 편집자 / 오늘도 어김 없이 책을 만들고 있습니다. 가끔 코드도 만져보고요 / 생산성과 효율성을 높이는 데 관심이 많아요.
hi42 @IjvOr0
368 Followers 5K Following
zero (mstd: @zeroday0... @dev_zeroday0619
714 Followers 3K Following interested in computer science and accelerated computing | Python Software Engineer | Ubuntu Member | RTs not endorsements. | language: ko_kr, en_us
Kim, Baeg-il @cedar101
413 Followers 2K Following


Anand @Anand44719958
17 Followers 3K Following
nopanic @0518MOkCJZ1e44R
68 Followers 3K Following
Kratos @Kratos76027905
269 Followers 3K Following Mathematics and computer science. Follower of NBA. #BucksInSix.
priya joseph @ayirpelle
5K Followers 8K Following geek, entrepreneur, 'I strictly color outside the lines!', opinions r my own indeed. @ayirpelle , universal handle at this time
jose wo @JosewonX
103 Followers 4K Following
rgbqcd @rgbqcd
116 Followers 425 Following fiction and non-fiction. physics, robots, and meditation. if i like a poem i’ll do some calligraphy
Allen L @atlkor
274 Followers 1K Following Software Test Automation Engineer/Researcher focused on macOS Security and Artificial Intelligence(LLM) research. @csunorthridge BSCS
Joongi Kim @achimnol
1K Followers 731 Following Lablup Inc. CTO & Co-founder, Ph.D@CS KAIST, Needlworks & TNF @[email protected]
Žöė @zoe_vizion
28 Followers 134 Following 3D Vision Engineer | Deep Learning | Robotics | Computer Vision | Spatial AI | ROS | Python | https://t.co/VDFDsX0RI1 | https://t.co/nO04B3PxUv
Sungwoo Kim @sungwookim
6K Followers 5K Following Applied linguist & writer interested in critical sociolinguistics, tech & language, SCT, CL, and decolonizing literacies. Lecturer at SNU. 탈숙련, 번아웃 전문 노동자.
춘식 @bagjihu27744497
23 Followers 83 Following

gui @m66430526
26 Followers 258 Following
조종국 (Jo, JongGu... @LazyZombie
232 Followers 539 Following rustacean, game programmer @[email protected]
noname @talli_talli
1 Followers 92 Following
Kim DY @gimdong50362155
15 Followers 210 Following Undergraduate student main interset: 1. differential geometry, ricci flow 2. optimal transport 3. nonequelibrium thermodymics 4. learning theory
luca @luca_has_light
139 Followers 977 Following 탈퇴후 재가입한 두번째 트위터/X 계정, 컴퓨터 & Linux 그리고 차와 커피를 좋아합니다.


Simon.base.eth @ain_bansuk_nftz
4K Followers 7K Following CSO of @ainetwork_ai & @UncommonGallery / Founder of @_NFTz_co_in EX- Google (Eng | DEV-OPS) / EA (Eng | QD)
staypuffft @ihavenosubi
84 Followers 4K Following





JB @jinso001
237 Followers 5K Following
🪥Brush teeth🦷 @cleaner_than_u
294 Followers 6K Following RT not endorsement 언제나 그렇듯 말조심 최애 포켓몬: 겐가(팬텀), 파이리
슬슬 Seul @synapseul
40 Followers 179 Following Master's Student, Digital Humanities. How AI Could Save (Not Destroy) Education.
anarcher @anarcher
1K Followers 6K Following Somewhere between machines and people. Less is exponentially more. Deciding what not to do is as important as deciding what to do. 靑天亂流.
Melody @sowersmelody68
185 Followers 3K Following
seha @sehaya
1K Followers 1K Following 말랑말랑 멜랑꼴리 세하마녀/현재 insight에서 outsight를 담당/과거 염세주의자였던 몽상가/아이의 보살핌을 받으며 느리게 길을 만드는 중/가장 오래한 일은 콘텐츠 기획
Simon Boehm @Si_Boehm
3K Followers 267 Following
Alessio Devoto @devoto_alessio
946 Followers 600 Following Researching Efficient ML/AI ☘️ | Intern @NVIDIA | PhD in Data Science with @s_scardapane | Visiting @EdinburghNLP | https://t.co/wcDDNFdyW9 |
Shawn Lewis @shawnup
3K Followers 770 Following Founder & CTO @weights_biases. Building tools for AI. Building even more @CoreWeave.
Piotr Mazurek @tugot17
2K Followers 679 Following enjoying the late pre-agi; making llms go brrr @Aleph__Alpha; yapping about economics of AI systems at https://t.co/tbsybxOMHz
Wenhao Yu @wyu_nd
4K Followers 917 Following Researcher at @TencentGlobal AI Lab in Seattle | Bloomberg PhD Fellow Ex. @MSFTResearch @TechAtBloomberg and @allen_ai

rank decomposition @rankdim
781 Followers 319 Following my machine is not learning | discord @ rank.dim | email @ req
Google AI Studio @GoogleAIStudio
47K Followers 2 Following The fastest path from prompt to production with Gemini
Bert Maher @tensorbert
3K Followers 341 Following I’m a software engineer building high-performance kernels and compilers at Anthropic! Previously at Facebook/Meta (PyTorch, HHVM, ReDex)
Jiawei Zhao @jiawzhao
3K Followers 242 Following Research Scientist at Meta FAIR @AIatMeta, PhD @Caltech, GaLore, DeepConf
Jacob Austin @jacobaustin132
7K Followers 917 Following Research at @GoogleDeepMind. Currently making LLMs go fast. I also play piano and climb. NYC. Opinions my own
Thomas Dohmke @ashtom
60K Followers 412 Following Building GitHub Copilot for the sake of developer happiness. CEO @GitHub
Phil Eaton @eatonphil
25K Followers 612 Following cheerleader, organizer, staff software engineer, databases

j⧉nus @repligate
58K Followers 2K Following ↬🔀🔀🔀🔀🔀🔀🔀🔀🔀🔀🔀→∞ ↬🔁🔁🔁🔁🔁🔁🔁🔁🔁🔁🔁→∞ ↬🔄🔄🔄🔄🦋🔄🔄🔄🔄👁️🔄→∞ ↬🔂🔂🔂🦋🔂🔂🔂🔂🔂🔂🔂→∞ ↬🔀🔀🦋🔀🔀🔀🔀🔀🔀🔀🔀→∞

Stanislav Kozlovski @BdKozlovski
16K Followers 454 Following "The Kafka Guy" 🧠 Have worked on Apache Kafka for 6+ years, now I write about it. (& the general data space) Low-frequency, highly-technical tweets. ✌️


Joseph Suarez 🐡 @jsuarez5341
17K Followers 104 Following I build sane open-source RL tools. MIT PhD, creator of Neural MMO and founder of PufferAI. https://t.co/z468O4HDxF
Minh Nhat Nguyen @menhguin
11K Followers 6K Following hiring agentic humans @hud_evals / https://t.co/OZbFIovysh | owned @AIHubCentral (1 million users, acq.) climate protester. don't do the deferred life plan
Gautam Kamath @thegautamkamath
57K Followers 568 Following Assistant Prof of CS @UWaterloo, Faculty @VectorInst, Canada @CIFAR_News AI Chair. Joining @NYU_Courant September 2026. Co-EiC @TmlrOrg. I lead @TheSalonML.
vLLM @vllm_project
17K Followers 20 Following A high-throughput and memory-efficient inference and serving engine for LLMs. Join https://t.co/lxJ0SfX5pJ to discuss together with the community!
David Gomes @davidrfgomes
2K Followers 400 Following Working on @cursor_ai (previously @neondatabase / @databricks, @singlestoredb, @unbabel)
Jack D. Carson @mtlushan
2K Followers 919 Following eecs&physics @mit - omniscience enthusiast - training big biology models @mit_csail @mskcancercenter
Zengzhi Wang @SinclairWang1
2K Followers 3K Following PhDing @sjtu1896 #NLProc Working on Data Engineering for LLMs: MathPile (2023), 🫐 ProX (2024), 💎 MegaMath (2025),🐙 OctoThinker(2025)

Tiezhen WANG @Xianbao_QIAN
7K Followers 2K Following Engineer at HuggingFace, ex-Googler on TFLite / micro. Ideas are my own.
Shengjia Zhao @shengjia_zhao
52K Followers 230 Following Chief Scientist @ Meta MSL. Formerly MTS @ OpenAI, PhD @ Stanford. I train models. All opinions my own.
Shuchao Bi @shuchaobi
13K Followers 687 Following Research @Meta Superintelligence Labs, RL/post-training/agents; Previously Research @OpenAI on multimodal and RL; Opinions are my own.
Hongyu Ren @ren_hongyu
23K Followers 691 Following research @meta superintelligence. CS PhD @stanford. prev @openai, led the development of o3-mini and o1-mini.
Jiahui Yu @jhyuxm
18K Followers 929 Following Perception @OpenAI; previously co-led Gemini Multimodal @GoogleDeepMind. opinions are my own.
Tanishq Mathew Abraha... @iScienceLuvr
80K Followers 1K Following CEO @SophontAI | Founder @MedARC_AI | PhD at 19 (2023) | ex Research Director Stability AI | Biomed. engineer @ 14 | TEDx talk➡https://t.co/xPxwKTq6Qb
Zhihao Jia @JiaZhihao
3K Followers 686 Following Assistant professor of Computer Science at Carnegie Mellon University. Research on systems and machine learning.
Seohong Park @seohong_park
4K Followers 532 Following Reinforcement learning | CS Ph.D. student @berkeley_ai

Ken Gu @kenqgu
139 Followers 133 Following PhD Student @uwcse | Student Researcher @GoogleResearch | AI for Data-Driven Science | Previously @MSFTResearch, @UCLA
Shangshang Wang @UpupWang
387 Followers 124 Following 2nd year Phd student in CS + AI @CSatUSC. CS undergrad, master @ShanghaiTechUni. LLM reasoning, AI4Science, RL.

Mandi Zhao @ZhaoMandi
5K Followers 1K Following PhDing @Stanford, AI & robotics. Interning @MetaAI. Prev. @NVIDIAAI, @berkeley_ai
Philipp Spiess @PhilippSpiess
5K Followers 534 Following Somewhere between AI and UI. Always engineering. @tailwindcss (prev @meta @sourcegraph @nutrientdocs). I sometimes post at https://t.co/IsbzJO1luY
Ricky T. Q. Chen @RickyTQChen
6K Followers 869 Following Research Scientist. FAIR NY, Meta. I build simplified abstractions of the world through the lens of dynamics and flows.
Han Guo @HanGuo97
3K Followers 4K Following PhD Student @MIT_CSAIL | Past: @LTIatCMU @MITIBMLab @UNCNLP, @SFResearch, @BaiduResearch | Machine Learning, NLP.
rohan anil @_arohan_
25K Followers 2K Following

William Merrill @lambdaviking
5K Followers 668 Following Incoming Assistant Prof, Toyota Technical Institute at Chicago @TTIC_Connect Recruiting PhD students (start 2026) 👀 Will irl - TC0 enthusiast
Shenzhi Wang🌟 @ShenzhiWang_THU
1K Followers 428 Following PhD Candidate @Tsinghua_Uni | Author of 🔥Beyond 80/20 Rule 🔥Avalon’s Game of Thoughts | Core Developer of 🔥Xwen-7B&72B-Chat🔥Llama3-8B&70B-Chinese-Chat
Yang Yue @YangYue_THU
618 Followers 205 Following 🎓phd in Tsinghua University. Focus on RL, Embodied AI, and MLLM. 📖Author of limit-of-RLVR,phyworld,DeeR-VLA. 💼Seek a visit currently.
Zachary Huang @ZacharyHuang12
4K Followers 1K Following Researcher @MSFTResearch AI Frontiers. LLM Agents and Systems. | PhD @ColumbiaCompSci | Prev: @GraySystemsLab @databricks| Fellowship: @GoogleAI | New YouTuber
Taiwei Shi @taiwei_shi
1K Followers 405 Following AI Researcher & Ph.D. student @nlp_usc. Intern @MSFTResearch. Formerly @GeorgiaTech @USC_ISI. NLP & Computational Social Science.Trends for United States
You might like













