
Muru Zhang @zhang_muru
First-year PhD @nlp_usc | Student Researcher @GoogleDeepmind | bsms @uwcse | Prevs. @togethercompute @AWS nanami18.github.io Joined August 2021-
Tweets74
-
Followers564
-
Following306
-
Likes322
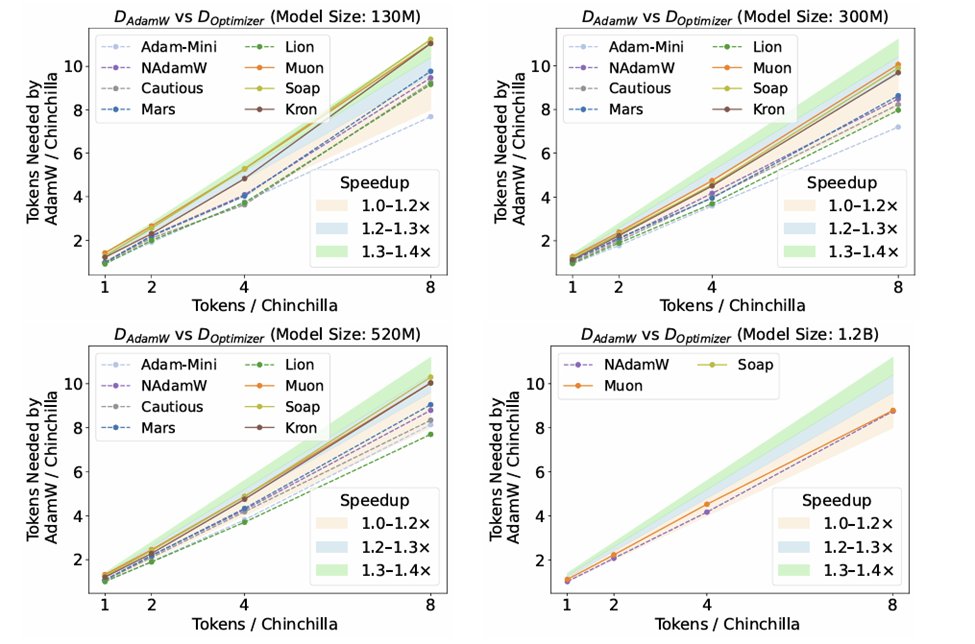
(1/n) Check out our new paper: "Fantastic Pretraining Optimizers and Where to Find Them"! >4000 models to find the fastest optimizer! 2× speedups over AdamW? Unlikely. Beware under-tuned baseline or limited scale! E.g. Muon: ~40% speedups <0.5B & only 10% at 1.2B (8× Chinchilla)!

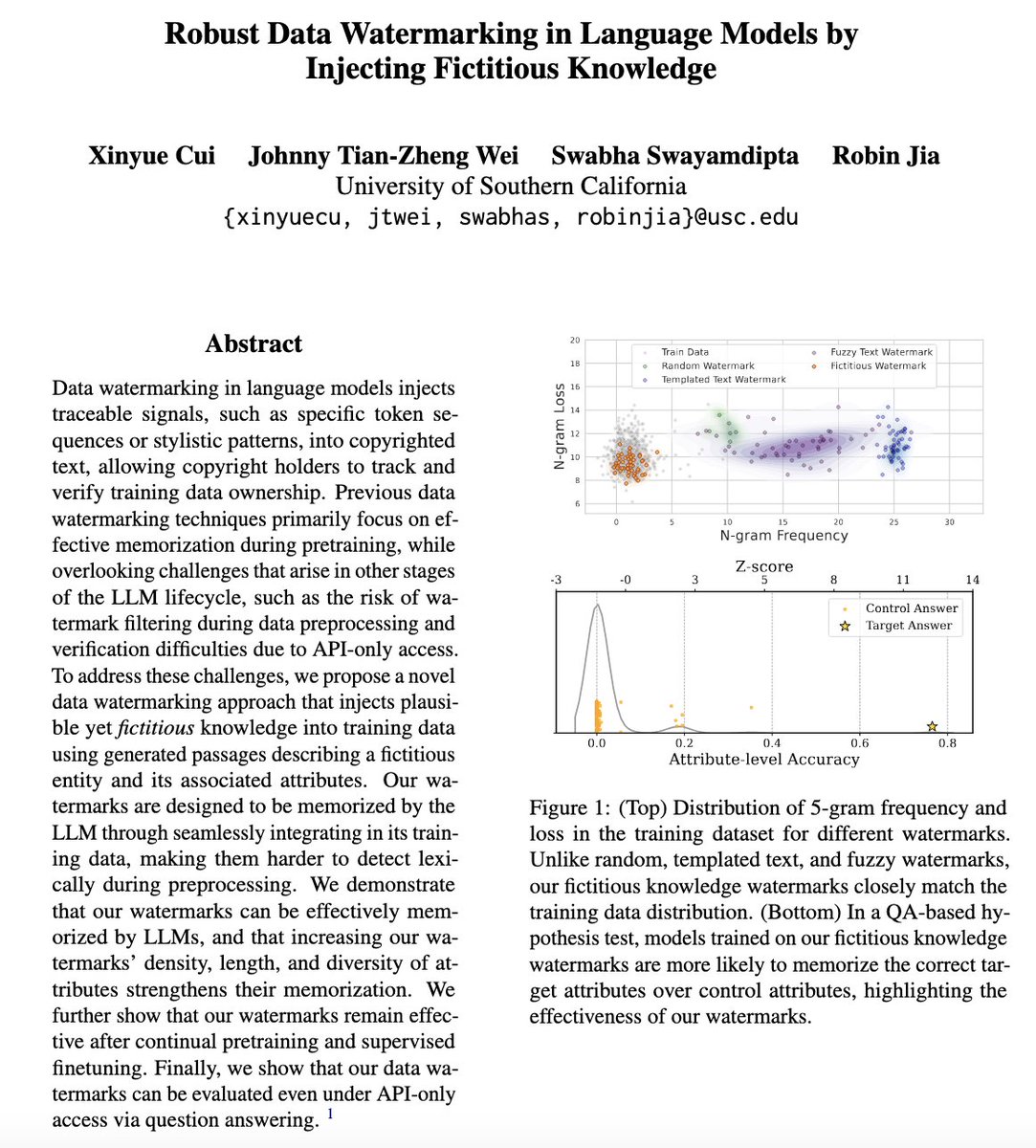
Can we create effective watermarks for LLM training data that survive every stage in real-world LLM development lifecycle? Our #ACL2025Findings paper introduces fictitious knowledge watermarks that inject plausible yet nonexistent facts into training data for copyright…

I’ll be at ACL 2025 next week where my group has papers on evaluating evaluation metrics, watermarking training data, and mechanistic interpretability. I’ll also be co-organizing the first Workshop on LLM Memorization @l2m2_workshop on Friday. Hope to see lots of folks there!
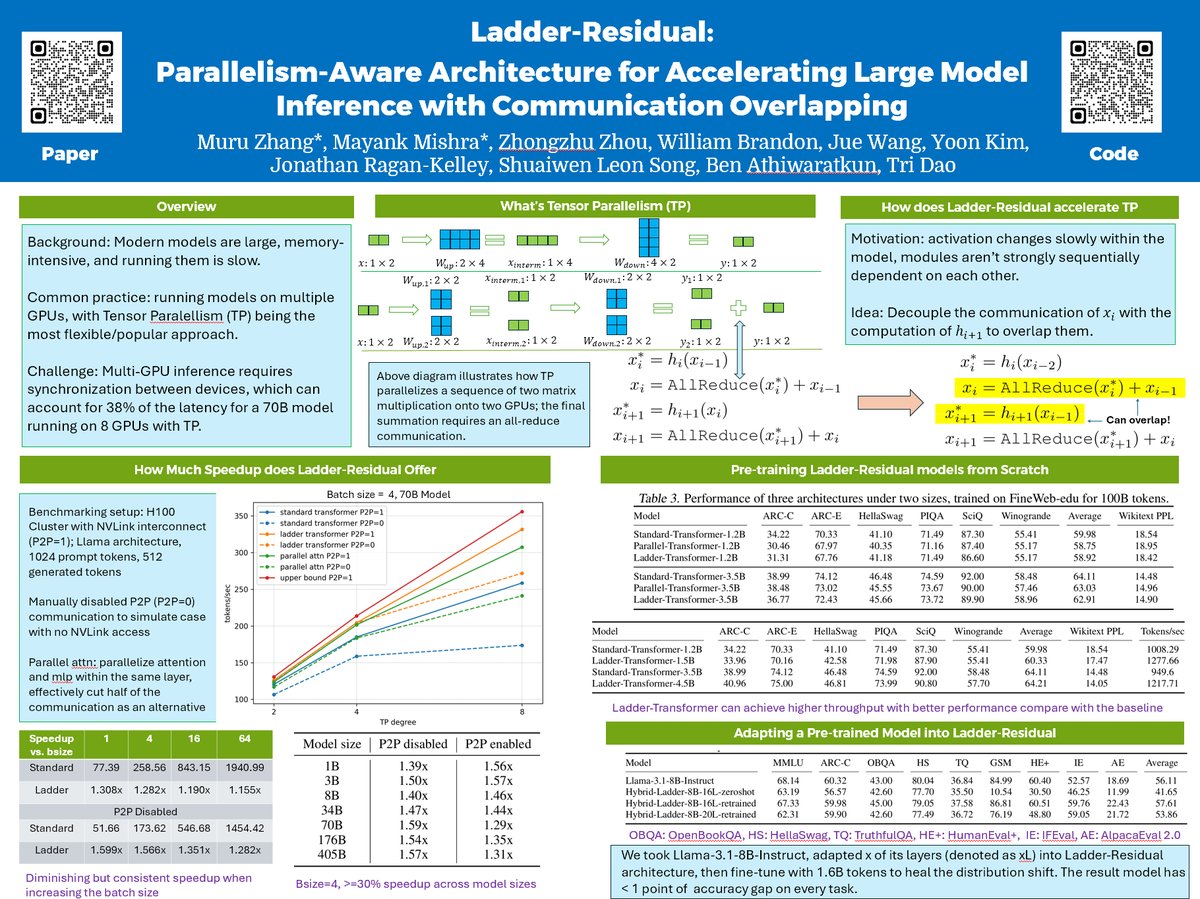
I'm at #ICML2025, presenting Ladder-Residual (arxiv.org/abs/2501.06589) at the first poster session tomorrow morning (7/15 11am-1:30pm), looking forward to seeing you at West Exhibition Hall B2-B3 #W-1000!

Have you noticed… 🔍 Aligned LLM generations feel less diverse? 🎯 Base models are decoding-sensitive? 🤔 Generations get more predictable as they progress? 🌲 Tree search fails mid-generation (esp. for reasoning)? We trace these mysteries to LLM probability concentration, and…

I didn't believe when I first saw, but: We trained a prompt stealing model that gets >3x SoTA accuracy. The secret is representing LLM outputs *correctly* 🚲 Demo/blog: mattf1n.github.io/pils 📄: arxiv.org/abs/2506.17090 🤖: huggingface.co/dill-lab/pils-… 🧑💻: github.com/dill-lab/PILS


Hi all, I'm going to @FAccTConference in Athens this week to present my paper on copyright and LLM memorization. Please reach out if you are interested to chat about law, policy, and LLMs!
Hi all, I'm going to @FAccTConference in Athens this week to present my paper on copyright and LLM memorization. Please reach out if you are interested to chat about law, policy, and LLMs!

LLMs excel at finding surprising “needles” in very long documents, but can they detect when information is conspicuously missing? 🫥AbsenceBench🫥 shows that even SoTA LLMs struggle on this task, suggesting that LLMs have trouble perceiving “negative space” in documents. paper:…


We built sparse-frontier — a clean abstraction that lets you focus on your custom sparse attention implementation while automatically inheriting vLLM’s optimizations and model support. As a PhD student, I've learned that sometimes the bottleneck in research isn't ideas — it's…


read the first letter of every name in the gemini contributors list

Wanna 🔎 inside Internet-scale LLM training data w/o spending 💰💰💰? Introducing infini-gram mini, an exact-match search engine with 14x less storage req than the OG infini-gram 😎 We make 45.6 TB of text searchable. Read on to find our Web Interface, API, and more. (1/n) ⬇️


🤔Conventional LM safety alignment is reactive: find vulnerabilities→patch→repeat 🌟We propose 𝗼𝗻𝗹𝗶𝗻𝗲 𝐦𝐮𝐥𝐭𝐢-𝐚𝐠𝐞𝐧𝐭 𝗥𝗟 𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴 where Attacker & Defender self-play to co-evolve, finding diverse attacks and improving safety by up to 72% vs. RLHF 🧵

After a year of internship with amazing folks at @togethercompute, I will be interning at @GoogleDeepMind this summer working on language model architecture! Hit me up and I will get you a boba at the bayview rooftop of my Emeryville apartment 😉



🧐When do LLMs admit their mistakes when they should know better? In our new paper, we define this behavior as retraction: the model indicates that its generated answer was wrong. LLMs can retract—but they rarely do.🤯 arxiv.org/abs/2505.16170 👇🧵

Ever get bored seeing LLMs output one token per step? Check out HAMburger (advised by @ce_zhang), which smashes multiple tokens into a virtual token with up to 2x decoding TPS boost + reduced KV FLOPs and storage while maintaining quality! github.com/Jingyu6/hambur…
Extremely fun read that unifies many scattered anecdotes on RLVR together and conclude with a set of beautiful experiments and explanations :))
Extremely fun read that unifies many scattered anecdotes on RLVR together and conclude with a set of beautiful experiments and explanations :))


Textual steering vectors can improve visual understanding in multimodal LLMs! You can extract steering vectors via any interpretability toolkit you like -- SAEs, MeanShift, Probes -- and apply them to image or text tokens (or both) of Multimodal LLMs. And They Steer!




Ziling Cheng @ziling_cheng
98 Followers 149 Following Research MSc @Mila_Quebec @mcgill_nlp | Research Fellow @RBCBorealis | reasoning and hallucination x evaluation and interpretability | Looking for Fall '26 PhD

Clara Smith @Nurulemylia8
113 Followers 5K Following Guiding @Elonmusk’s vision for a better future through SpaceX, Tesla, Neuralink and more 🚀 I teach enthusiasts, dream chaser and innovation advocate 🌟
Sihao Chen @soshsihao
952 Followers 541 Following Researcher @ Microsoft #OAR. Learning AI models from experience. Previously: @upennnlp @cogcomp @GoogleAI. Opnions my own.

degen_bobo 🤖💎 @agostino90
640 Followers 4K Following
Arjun Choudhry @Arjun_7m
266 Followers 1K Following 1st Year ML PhD @GeorgiaTech. Previously @AutonLab @SCSatCMU, @UTSAAII, @UQAM, @dtu_delhi. Interests: Multimodal FMs, Structured Data, Efficiency

MoatsOnly🇺🇸 @Ywapu586
46 Followers 2K Following 15-30% Monthly | 2 High-Conviction Stocks.Short-Term Gains: 15-20% in Days/Weeks.DM "JOIN" for WhatsApp Alerts. Live Trade Signals • Market Analysis
Lourdes Dach @DachLourde32600
84 Followers 3K Following
jogender yadav @jogende7142081
12 Followers 807 Following
Twirdjawr @Twirdjawr325
86 Followers 1K Following
Gaeul @KE3934399331305
2 Followers 120 Following
Ryleigh Heller @RyleighH97726
39 Followers 2K Following

Lucie Schinner @LucieSchin66669
25 Followers 2K Following
Sterling Hsu @SterlingHsu
0 Followers 22 Following
Akshit @akshitwt
3K Followers 663 Following assessing ai capabilities. soon: ml grad @cambridge_uni. previously @precogatiiith, @iiit_hyderabad. futurebound.
Andrey Risukhin @ ICM... @AndreyRisuka
61 Followers 100 Following Data. Founding team @perceptroninc. Incoming UIUC PhD, @uwnlp BS/MS
Ian Magnusson @IanMagnusson
445 Followers 446 Following Science of language models @uwnlp and @allen_ai with @PangWeiKoh and @nlpnoah.
Zheng | Vibe Working @zheng401
831 Followers 4K Following vibe living with AGI @Kimi fueled by caffeine, code and dream!
Rudi Alaja @Racotour
37 Followers 1K Following
Владислав @vlad_andronikk
2 Followers 89 Following
Fahad Shah @sfahad
935 Followers 8K Following @Leadership @DataScience @HP @AzureML @Happily Married 😊

Pengxiang Li @pixeli_polyu
0 Followers 5 Following
James Morrison Rubin @import_jmr
7K Followers 6K Following Product Lead | Google Gemini Prev: Launched @aws Trainium, @alexa99 Echo Show 5 Tweets are my own. Retweets are not endorsements. Joyful Learning Machines
Brad Pitt @janiceKus
126 Followers 2K Following Jesus Christ is the King I am Brad Pitt from America 🇺🇸 I love my people and I love America 🇺🇸 God bless America
Xinyu Yang @Xinyu2ML
993 Followers 981 Following Ph.D. @CarnegieMellon. Working on data and hardware-driven principled algorithm & system co-design for scalable and generalizable foundation models. They/Them

Miami @lhu017627560190
6 Followers 899 Following


Shahzaib Saqib Warrai... @Shahzaib_S98
7 Followers 101 Following MS at @nlp_usc w/ @swabhz & @gyauney | ML Intern at @paramountpics | Interpretability, Alignment, Evaluation, Reasoning
Henry Ko @henryHM_ko
637 Followers 313 Following performance and efficiency in ML | CS @ UC Berkeley, @BerkeleyML
Tiansheng Wen @TianshengV111
45 Followers 109 Following Looking for PhD in 26fall. --DM if interested #AIGC & #ML & #ProbabilisticModel & #INFP
keesha @KeeshaBrown96
644 Followers 7K Following The wind is free to come and go, and we will meet when we are supposed to meet. If you decide to be brilliant, there is no mountain to block you, and no sea to
Andreas Kirsch 🇺�... @BlackHC
14K Followers 6K Following My opinions only here. 👨🔬 RS @DeepMind, @Midjourney 1y 🧑🎓 DPhil @AIMS_oxford @UniofOxford 4.5y 🧙♂️ RE DeepMind 1y 📺 SWE @Google 3y 🎓 TUM 👤 @nwspk
Kaiyuan Liu @KaiyuanLiu04
15 Followers 104 Following ICPC World Finalist, UW CS Undergrad looking for PhD position~

Sunny Sanyal @SunnySanyal9
1K Followers 519 Following PhD candidate @UTexasECE| Intern @GoogleDeepMind, @LightningAI & @AmazonScience | On Job market
Leo Liu @ZEYULIU10
1K Followers 2K Following PhD at UT Austin ex-{uw, isi, facebook} nlper Former intern @SFResearch
Karl Xie @Karl00994
7 Followers 146 Following
Amr Khalifa @AmrMAlameen
1K Followers 439 Following Research Scientist @GoogleDeepMind, pre-training and architecture research in Gemini, Gemma. On leave from PhD with @AaronCourville. Opinions are my own.

Yoram Bachrach @yorambac
3K Followers 7K Following Research Scientist at Meta (prev Google DeepMind and Microsoft Research). Working on LLM Agents and Multi-Agent Systems.
Matteo Bonano @MatteoBonano1
5 Followers 188 Following

Ziling Cheng @ziling_cheng
98 Followers 149 Following Research MSc @Mila_Quebec @mcgill_nlp | Research Fellow @RBCBorealis | reasoning and hallucination x evaluation and interpretability | Looking for Fall '26 PhD
Sihao Chen @soshsihao
952 Followers 541 Following Researcher @ Microsoft #OAR. Learning AI models from experience. Previously: @upennnlp @cogcomp @GoogleAI. Opnions my own.
James Chen @jchencxh
849 Followers 507 Following mostly representation learning for vision and generalisation @SCSatCMU hot takes on everything else
Andrey Risukhin @ ICM... @AndreyRisuka
61 Followers 100 Following Data. Founding team @perceptroninc. Incoming UIUC PhD, @uwnlp BS/MS
Ian Magnusson @IanMagnusson
445 Followers 446 Following Science of language models @uwnlp and @allen_ai with @PangWeiKoh and @nlpnoah.
Victor Zhong @hllo_wrld
5K Followers 500 Following ML+NLP AP @UWCheritonCS, @cifar_news AIChair @vectorinst. Former @MSFTResearch @MetaAI, @SFResearch via @MetamindIO, @uwnlp, @StanfordNLP, @eceuoft.
James Morrison Rubin @import_jmr
7K Followers 6K Following Product Lead | Google Gemini Prev: Launched @aws Trainium, @alexa99 Echo Show 5 Tweets are my own. Retweets are not endorsements. Joyful Learning Machines
望月けい @key_999
1.0M Followers 716 Following kei Mochizuki / Illustrator アニメと絵が好きです ▶︎ LOOPERS / Project:;COLDシリーズ / 第四境界 / レーミク2025 / FGO「バーヴァンシー」/ 刀剣乱舞「京極正宗」/ サンリオ「シエロモート」キャラデザ ▶︎https://t.co/qeDmYyDhAf
Xinyu Yang @Xinyu2ML
993 Followers 981 Following Ph.D. @CarnegieMellon. Working on data and hardware-driven principled algorithm & system co-design for scalable and generalizable foundation models. They/Them
Tiansheng Wen @TianshengV111
45 Followers 109 Following Looking for PhD in 26fall. --DM if interested #AIGC & #ML & #ProbabilisticModel & #INFP
Henry Ko @henryHM_ko
637 Followers 313 Following performance and efficiency in ML | CS @ UC Berkeley, @BerkeleyML
Andreas Kirsch 🇺�... @BlackHC
14K Followers 6K Following My opinions only here. 👨🔬 RS @DeepMind, @Midjourney 1y 🧑🎓 DPhil @AIMS_oxford @UniofOxford 4.5y 🧙♂️ RE DeepMind 1y 📺 SWE @Google 3y 🎓 TUM 👤 @nwspk
Kaiyuan Liu @KaiyuanLiu04
15 Followers 104 Following ICPC World Finalist, UW CS Undergrad looking for PhD position~
Sunny Sanyal @SunnySanyal9
1K Followers 519 Following PhD candidate @UTexasECE| Intern @GoogleDeepMind, @LightningAI & @AmazonScience | On Job market
Leo Liu @ZEYULIU10
1K Followers 2K Following PhD at UT Austin ex-{uw, isi, facebook} nlper Former intern @SFResearch
Simon Willison @simonw
115K Followers 6K Following Creator @datasetteproj, co-creator Django. PSF board. Hangs out with @natbat. He/Him. Mastodon: https://t.co/t0MrmnJW0K Bsky: https://t.co/OnWIyhX4CH
Amr Khalifa @AmrMAlameen
1K Followers 439 Following Research Scientist @GoogleDeepMind, pre-training and architecture research in Gemini, Gemma. On leave from PhD with @AaronCourville. Opinions are my own.
Alexander Spangher @AlexanderSpangh
888 Followers 287 Following @bloomberg PhD fellow, PhD in computer science at @usc studying creativity/planning in NLP. Former data scientist @nytimes and studied music at @JuilliardSchool


Nicholas Roberts @nick11roberts
1K Followers 2K Following Ph.D. student @WisconsinCS. Working on foundation models and breaking past scaling laws. Previously at CMU @mldcmu, UCSD @ucsd_cse, FCC @fresnocity.
Ted Zadouri @tedzadouri
595 Followers 273 Following PhD Student @PrincetonCS @togethercompute | Previously: @cohere @UCLA
CLS @ChengleiSi
5K Followers 3K Following PhDing @stanfordnlp | teaching language models to do research | real AGI is the friends we made along the way
Mann Patel @punsbymann
315 Followers 645 Following LLMs @CapitalOne | prev ml @google, GLAMOR LAB @USC | interpretability and all things compute

Yucheng Lu @_yucheng_lu
403 Followers 798 Following Assistant Professor @nyushanghai in ML Systems. Prev @togethercompute.
Leena Mathur @lmathur_
1K Followers 1K Following PhD student @SCSatCMU & SR @GoogleDeepMind. I study multimodal AI, social intelligence, & robotics w/ @ybisk & @lpmorency. prev @RobustAI, @USC, @Caltech, @EPFL
Richard Zhuang @RichardZ412
261 Followers 466 Following MSCS @Stanford🌲 Prev. Applied Math & CS @UCBerkeley🐻, Research Intern @bespokelabsai
Zijian Wang @zijianwang30
613 Followers 395 Following Science Manager at AWS AI Labs. Training code LLM/agents. Organizer of @DL4Code at ICLR and @LLM4Code at ICSE Past @StanfordNLP @StanfordSymSys @UMich @SJTU1896
Omar Khattab @lateinteraction
24K Followers 3K Following Asst professor @MIT EECS & CSAIL (@nlp_mit). Author of https://t.co/VgyLxl0oa1 and https://t.co/ZZaSzaRaZ7 (@DSPyOSS). Prev: CS PhD @StanfordNLP. Research @Databricks.

Yichuan Wang @YichuanM
703 Followers 2K Following 1st year EECS PhD at UC Berkeley SkyLab @BerkeleySky, 2020 ACM class in SJTU, interested in MLSYS.
Stella Li @StellaLisy
3K Followers 443 Following PhD student @uwnlp | visiting researcher @AIatMeta | undergrad @jhuclsp #NLProc

Simona Liao @SimonaLiao
28 Followers 11 Following
Atharva Kulkarni @athrvkk
177 Followers 304 Following CS PhD @CSatUSC | Prev - @SimonsInstitute, @LTIatCMU, @Apple, @lcs2lab | #NLProc Research
Peter Webb @WebyVGC
4 Followers 56 Following
Xiaosen Zheng @xszheng2020
597 Followers 2K Following Researcher @ TikTok 📄 RegMix 💼 Past: PhD @sgSMU | Intern @SeaAIL 🧠 Interests: Data-Centric AI | Code AI
Niloofar (✈️ ACL) @niloofar_mire
7K Followers 2K Following Niloofar Mireshghallah — incoming asst. prof @LTIatCMU @CMU_EPP, RS in @AIatMeta, postdoc @uwcse, Ph.D. @ucsd_cse, former @MSFTResearch -Privacy, ML, NLP
Jieyu Zhao @jieyuzhao11
3K Followers 824 Following Assistant Prof. @CSatUSC, @USC || Postdoc @ClipUMD || PhD from @UCLANLP, @UCLA. #NLP, #ML, #TrustworthyNLP
Linxin Song @linxins2
368 Followers 522 Following PhD student @csatusc @nlp_usc | Master @waseda_univ | Research intern @SFResearch | NLP/CV, LLM/LMM, Agent, Trustworthy model, Synthetic data
Qinyuan Ye @qinyuan_ye
2K Followers 2K Following ☁️ Research Scientist @SFResearch | 🐾 Teaching machines to be versatile and curious. | Prev @nlp_usc

Taiwei Shi @taiwei_shi
1K Followers 405 Following AI Researcher & Ph.D. student @nlp_usc. Intern @MSFTResearch. Formerly @GeorgiaTech @USC_ISI. NLP & Computational Social Science.
Rui Pan 潘瑞 @ruipeterpan
677 Followers 2K Following 3rd-yr PhD @PrincetonCS working on systems for ML/LLMs, interning @Google, previously @AmazonScience @maxplanckpress @WisconsinCS, fan of @fcbarcelona
Jingyu Liu @Jingyu227
71 Followers 86 Following CS PhD @Uchicago. Ex AI Resident @AIatMeta, MLE @ByteDanceTalk.Trends for United States
You might like













