
Introducing FLAME🔥: Factuality-Aware Alignment for LLMs We found that the standard alignment process **encourages** hallucination. We hence propose factuality-aware alignment while maintaining the LLM's general instruction-following capability. arxiv.org/abs/2405.01525
3
8
35
7K
15
Download Image
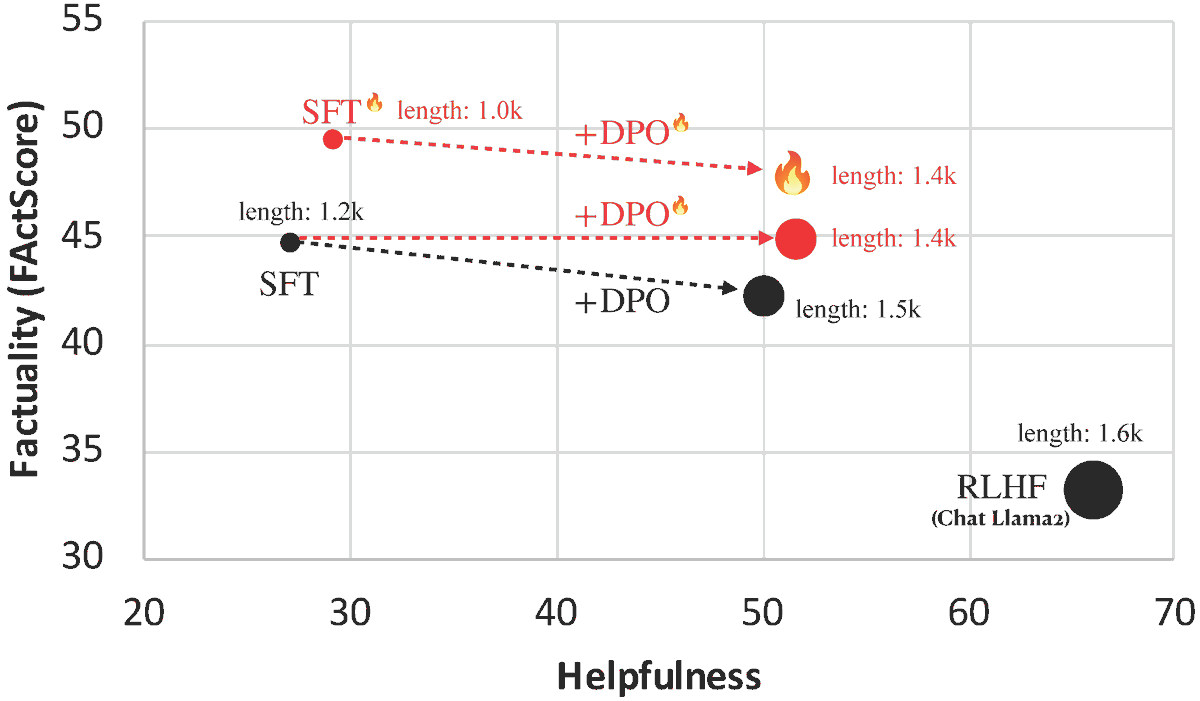
@jacklin_64 @luyu_gao @XiongWenhan @scottyih We first identify factors that lead to hallucination in both alignment steps: supervised fine-tuning (SFT) and reinforcement learning (RL). In particular, we find that training the LLM on new or unfamiliar knowledge can encourage hallucination. (2/n)
As a result, standard SFT makes the LLM less factual as it trains on human labeled data that may be novel to the LLM. (3/n)