
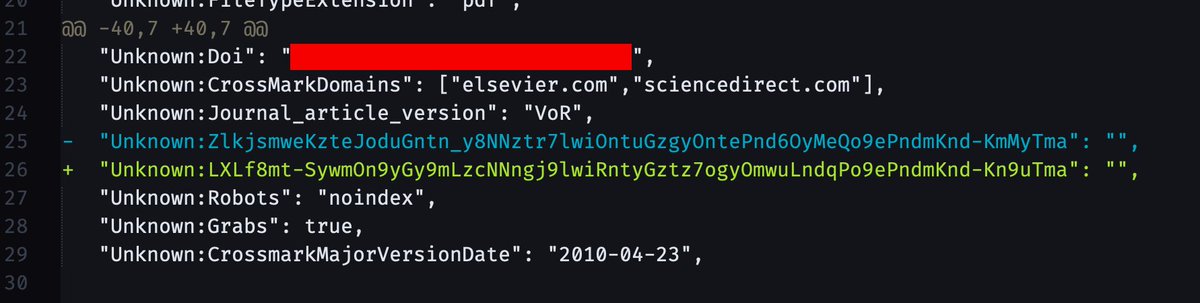
More fun publisher surveillance: Elsevier embeds a hash in the PDF metadata that is *unique for each time a PDF is downloaded*, this is a diff between metadata from two of the same paper. Combined with access timestamps, they can uniquely identify the source of any shared PDFs.
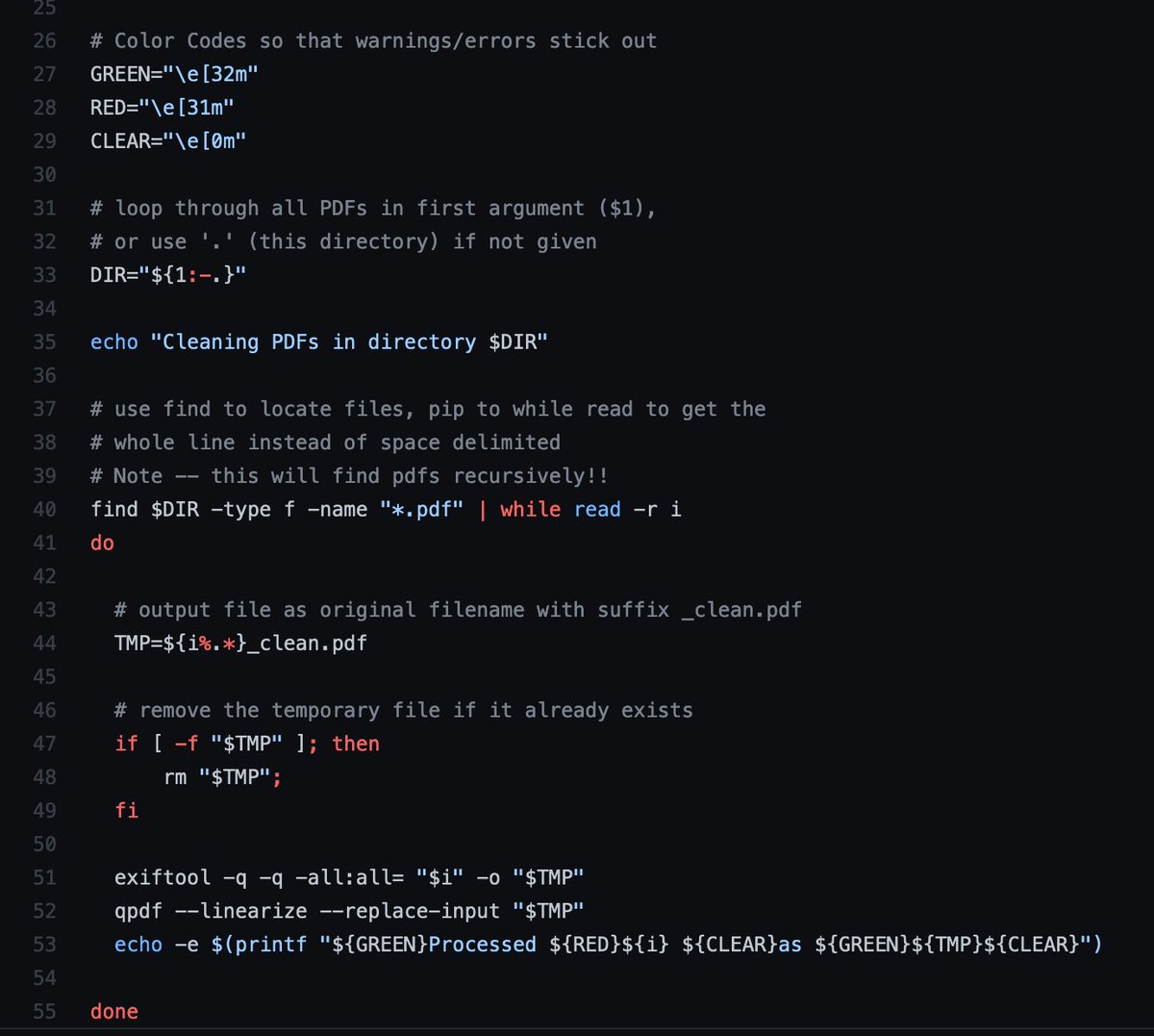
You can see for yourself using exiftool. To remove all of the top-level metadata, you can use exiftool and qpdf: exiftool -all:all= <path.pdf> -o <output1.pdf> qpdf --linearize <output1.pdf> <output2.pdf> To remove *all* metadata, you can use dangerzone or mat2
Also present in the metadata are NISO tags for document status indicating the "final published version" (VoR), and limits on what domains it should be present on. Elsevier scans for PDFs with this metadata, so good idea to strip it any time you're sharing a copy.

Links: exiftool: exiftool.org qpdf: qpdf.sourceforge.io dangerzone (GUI, render PDF as images, then re-OCR everything): dangerzone.rocks mat2 (render PDF as images, don't OCR): 0xacab.org/jvoisin/mat2
here's a shell script that recursively removes metadata from pdfs in a provided (or current) directory as described above. For mac/*nix-like computers, and you need to have qpdf and exiftool installed: gist.github.com/sneakers-the-r…
The metadata appears to be preserved on papers from sci-hub. since it works by using harvested academic credentials to download papers, this would allow publishers to identify which accounts need to be closed/secured
The metadata appears to be preserved on papers from sci-hub. since it works by using harvested academic credentials to download papers, this would allow publishers to identify which accounts need to be closed/secured
for any security researchers out there, here are a few more "hashes" that a few have noted do not appear to be random and might be decodable. exiftool apparently squashed the whitespace so there is a bit more structure to them than in the OP: gist.github.com/sneakers-the-r…